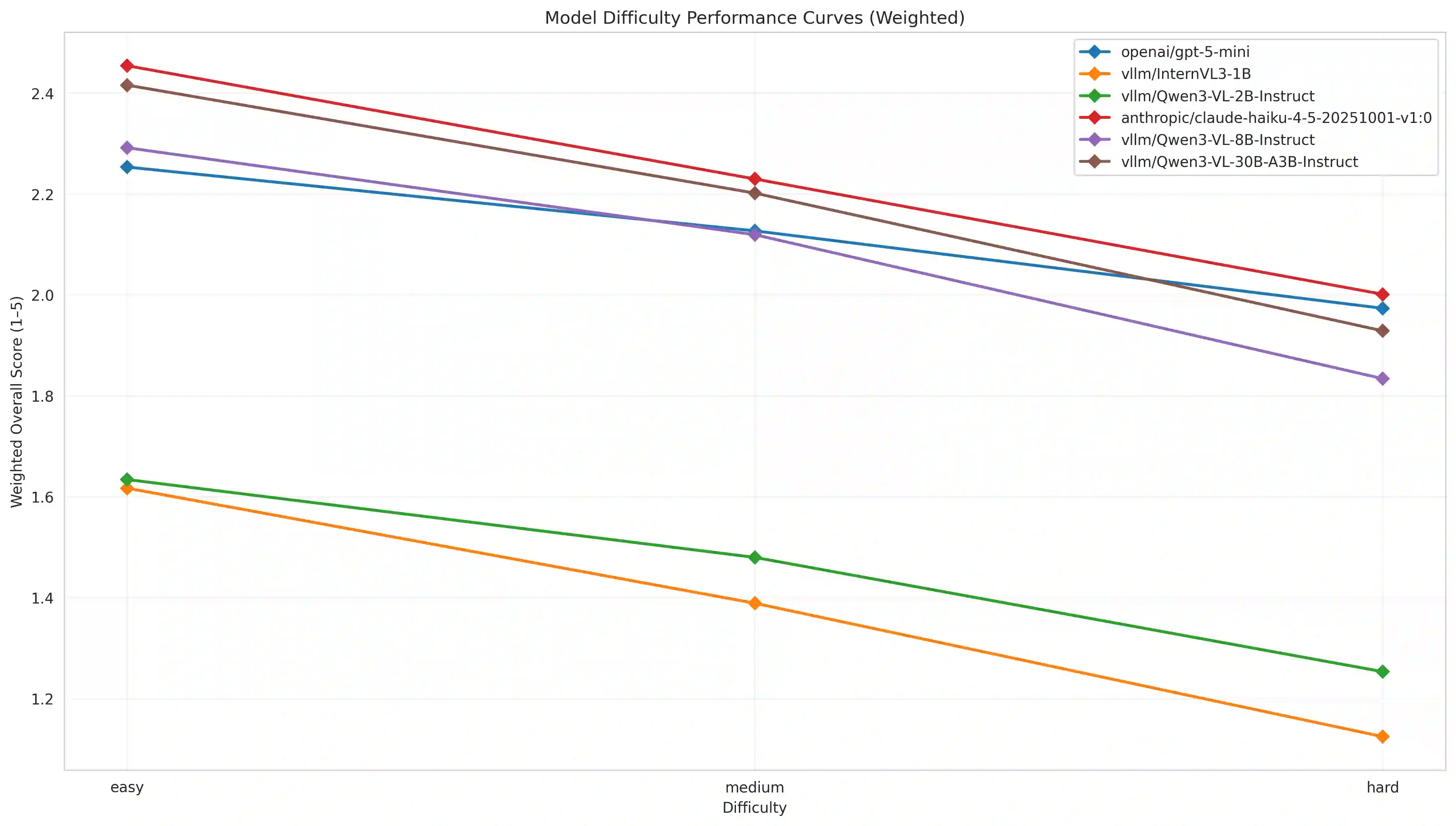
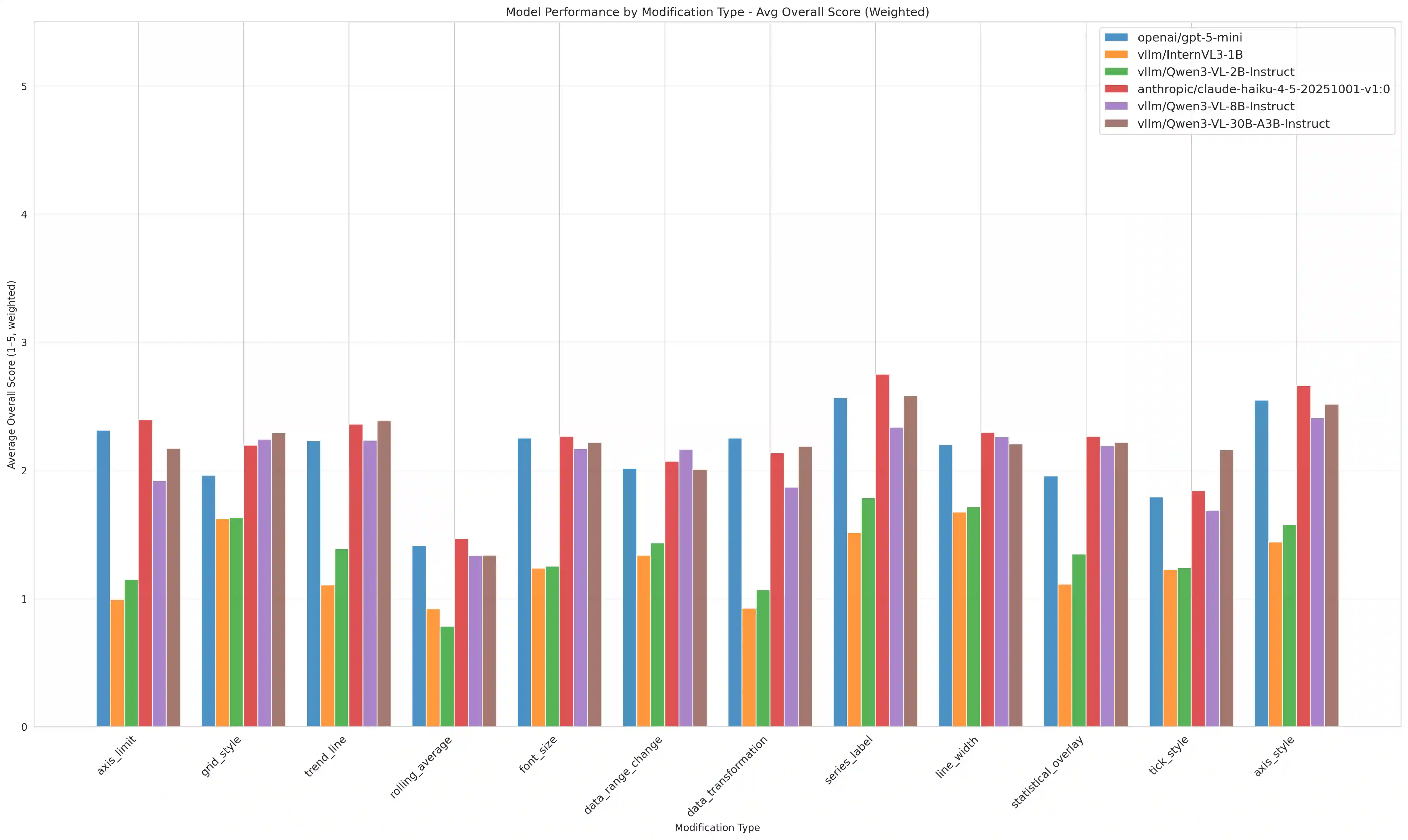
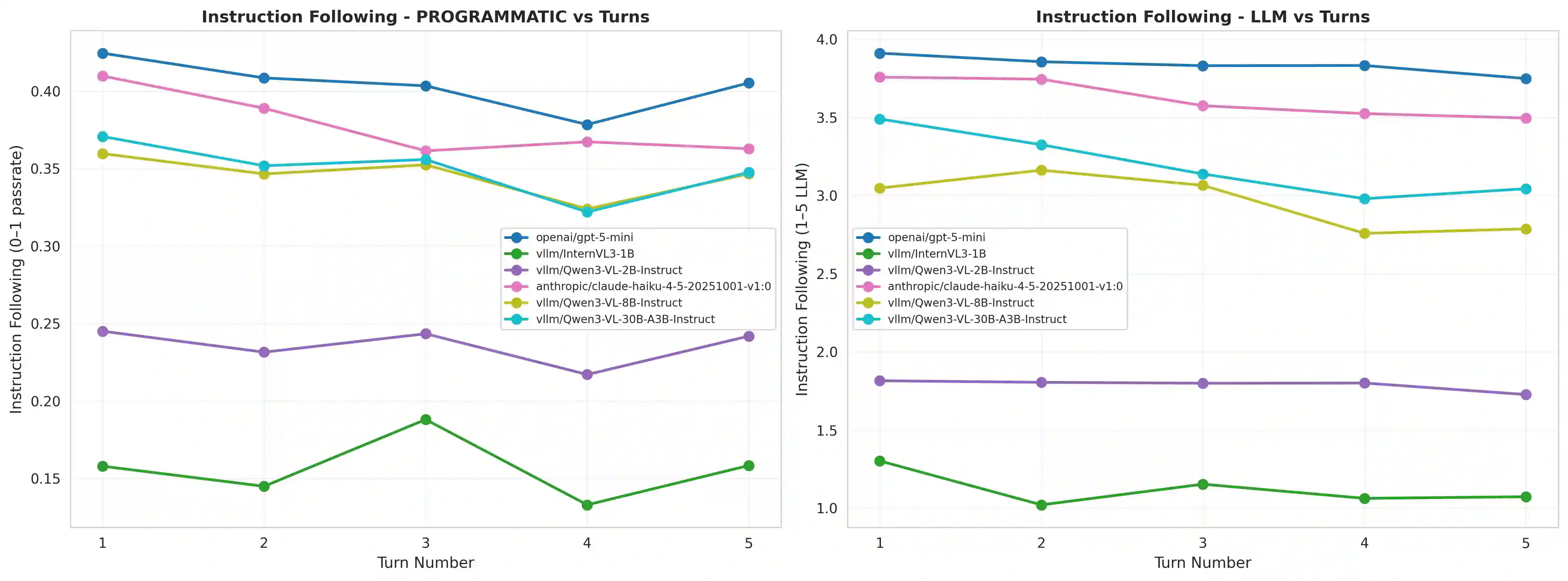
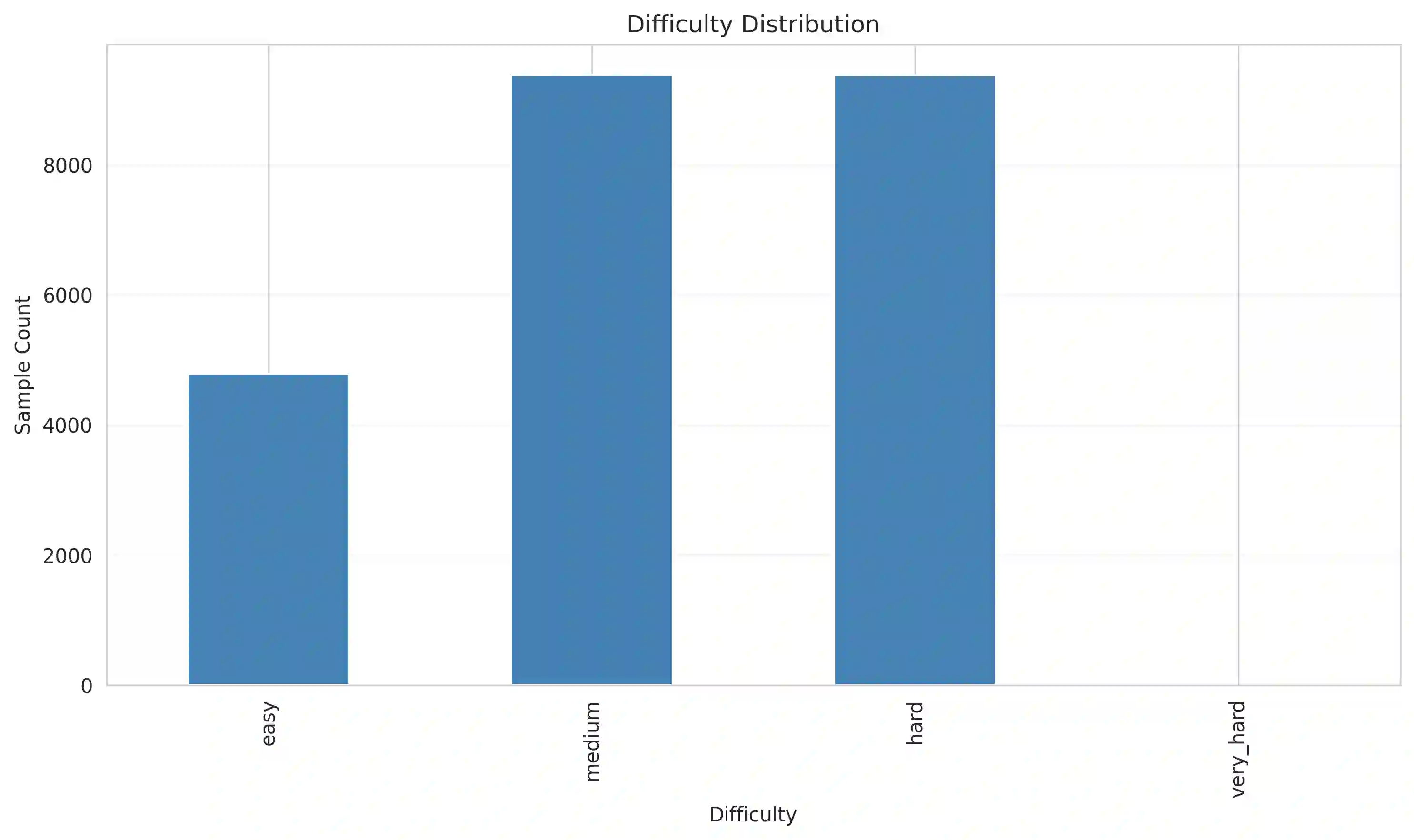
While Multimodal Large Language Models (MLLMs) perform strongly on single-turn chart generation, their ability to support real-world exploratory data analysis remains underexplored. In practice, users iteratively refine visualizations through multi-turn interactions that require maintaining common ground, tracking prior edits, and adapting to evolving preferences. We introduce ChartEditBench, a benchmark for incremental, visually grounded chart editing via code, comprising 5,000 difficulty-controlled modification chains and a rigorously human-verified subset. Unlike prior one-shot benchmarks, ChartEditBench evaluates sustained, context-aware editing. We further propose a robust evaluation framework that mitigates limitations of LLM-as-a-Judge metrics by integrating execution-based fidelity checks, pixel-level visual similarity, and logical code verification. Experiments with state-of-the-art MLLMs reveal substantial degradation in multi-turn settings due to error accumulation and breakdowns in shared context, with strong performance on stylistic edits but frequent execution failures on data-centric transformations. ChartEditBench, establishes a challenging testbed for grounded, intent-aware multimodal programming.
翻译:尽管多模态大语言模型(MLLMs)在单轮图表生成任务上表现强劲,但其支持真实世界探索性数据分析的能力仍有待深入探究。在实际应用中,用户通过多轮交互迭代优化可视化结果,这需要模型能够维持共同基础、追踪先前编辑并适应不断变化的偏好。我们提出了ChartEditBench,一个通过代码进行增量式、视觉基础图表编辑的基准测试,包含5,000条难度可控的修改链及一个经过严格人工验证的子集。与先前单轮基准测试不同,ChartEditBench评估的是持续、上下文感知的编辑能力。我们进一步提出一个稳健的评估框架,通过整合基于执行的保真度检查、像素级视觉相似性及逻辑代码验证,以缓解LLM-as-a-Judge指标的局限性。对前沿多模态大语言模型的实验表明,由于错误累积和共享上下文崩溃,其在多轮设置中性能显著下降——在样式编辑上表现良好,但在以数据为中心的转换上频繁出现执行失败。ChartEditBench为基于基础、意图感知的多模态编程建立了一个具有挑战性的测试平台。