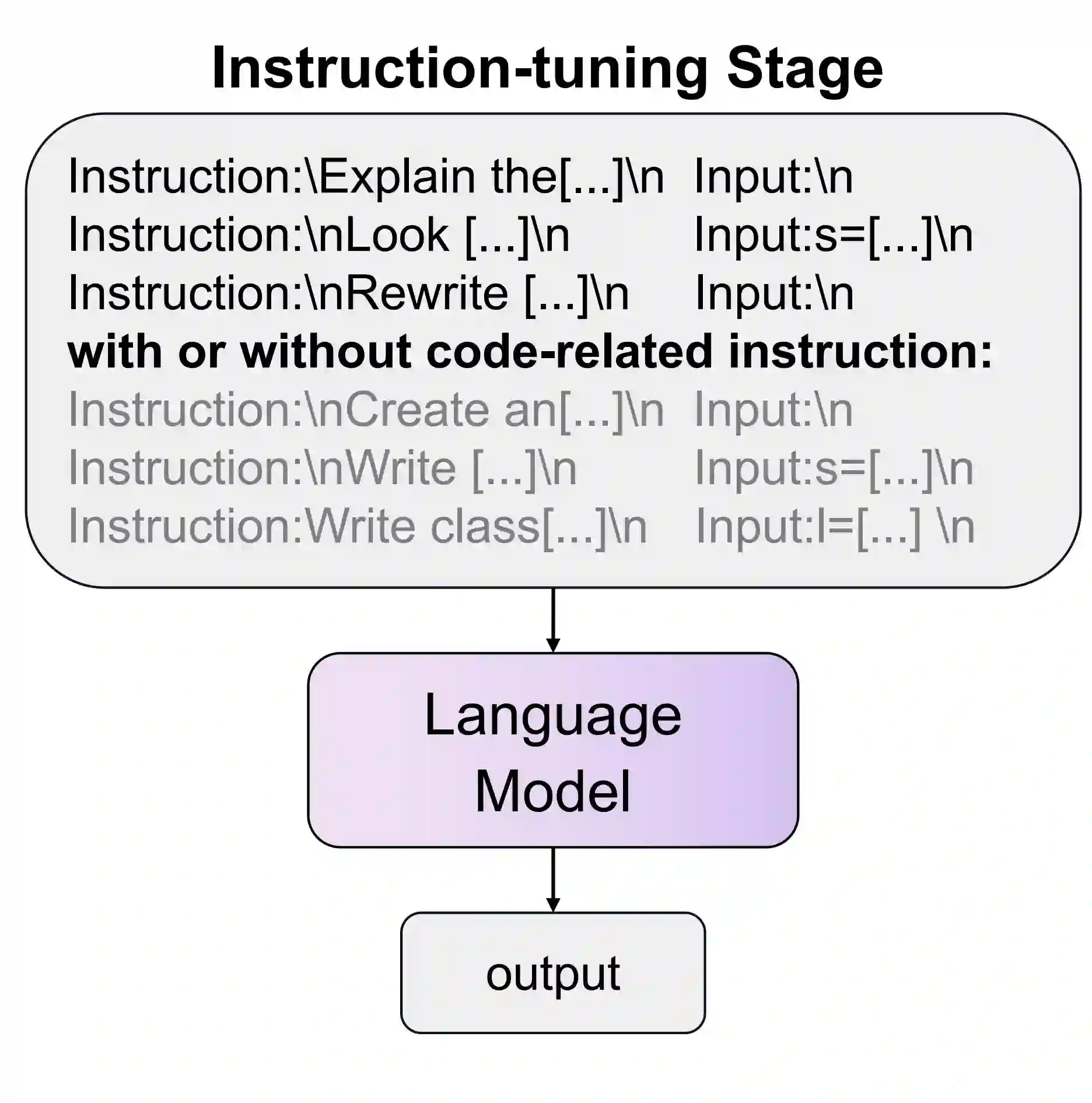
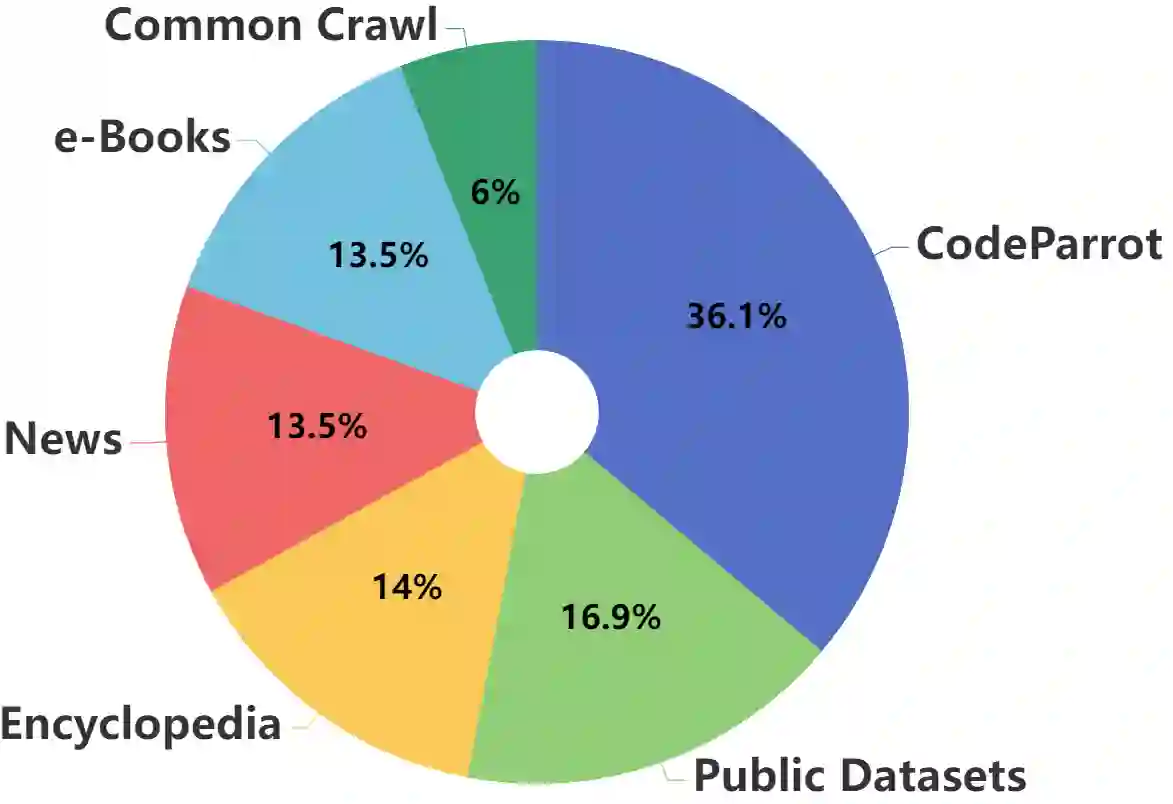
Large Language Models (LLMs) have exhibited remarkable reasoning capabilities and become the foundation of language technologies. Inspired by the great success of code data in training LLMs, we naturally wonder at which training stage introducing code data can really help LLMs reasoning. To this end, this paper systematically explores the impact of code data on LLMs at different stages. Concretely, we introduce the code data at the pre-training stage, instruction-tuning stage, and both of them, respectively. Then, the reasoning capability of LLMs is comprehensively and fairly evaluated via six reasoning tasks in five domains. We critically analyze the experimental results and provide conclusions with insights. First, pre-training LLMs with the mixture of code and text can significantly enhance LLMs' general reasoning capability almost without negative transfer on other tasks. Besides, at the instruction-tuning stage, code data endows LLMs the task-specific reasoning capability. Moreover, the dynamic mixing strategy of code and text data assists LLMs to learn reasoning capability step-by-step during training. These insights deepen the understanding of LLMs regarding reasoning ability for their application, such as scientific question answering, legal support, etc. The source code and model parameters are released at the link:~\url{https://github.com/yingweima2022/CodeLLM}.
翻译:大语言模型(LLMs)已展现出卓越的推理能力,并成为语言技术的基础。受代码数据在训练LLMs中取得巨大成功的启发,我们自然好奇在哪个训练阶段引入代码数据才能真正帮助LLMs提升推理能力。为此,本文系统性地探索了代码数据在不同阶段对LLMs的影响。具体而言,我们分别在预训练阶段、指令微调阶段以及两个阶段同时引入代码数据。随后,通过五个领域的六项推理任务全面且公平地评估LLMs的推理能力。我们对实验结果进行了批判性分析,并得出具有洞察力的结论。首先,使用代码与文本混合进行预训练能显著增强LLMs的通用推理能力,且几乎不会对其他任务产生负面迁移。其次,在指令微调阶段,代码数据赋予LLMs任务特定的推理能力。此外,代码与文本数据的动态混合策略可助力LLMs在训练过程中逐步学习推理能力。这些洞察深化了对LLMs推理能力的理解,为其在科学问答、法律支持等应用场景中提供了指导。源代码与模型参数已发布于链接:\url{https://github.com/yingweima2022/CodeLLM}。