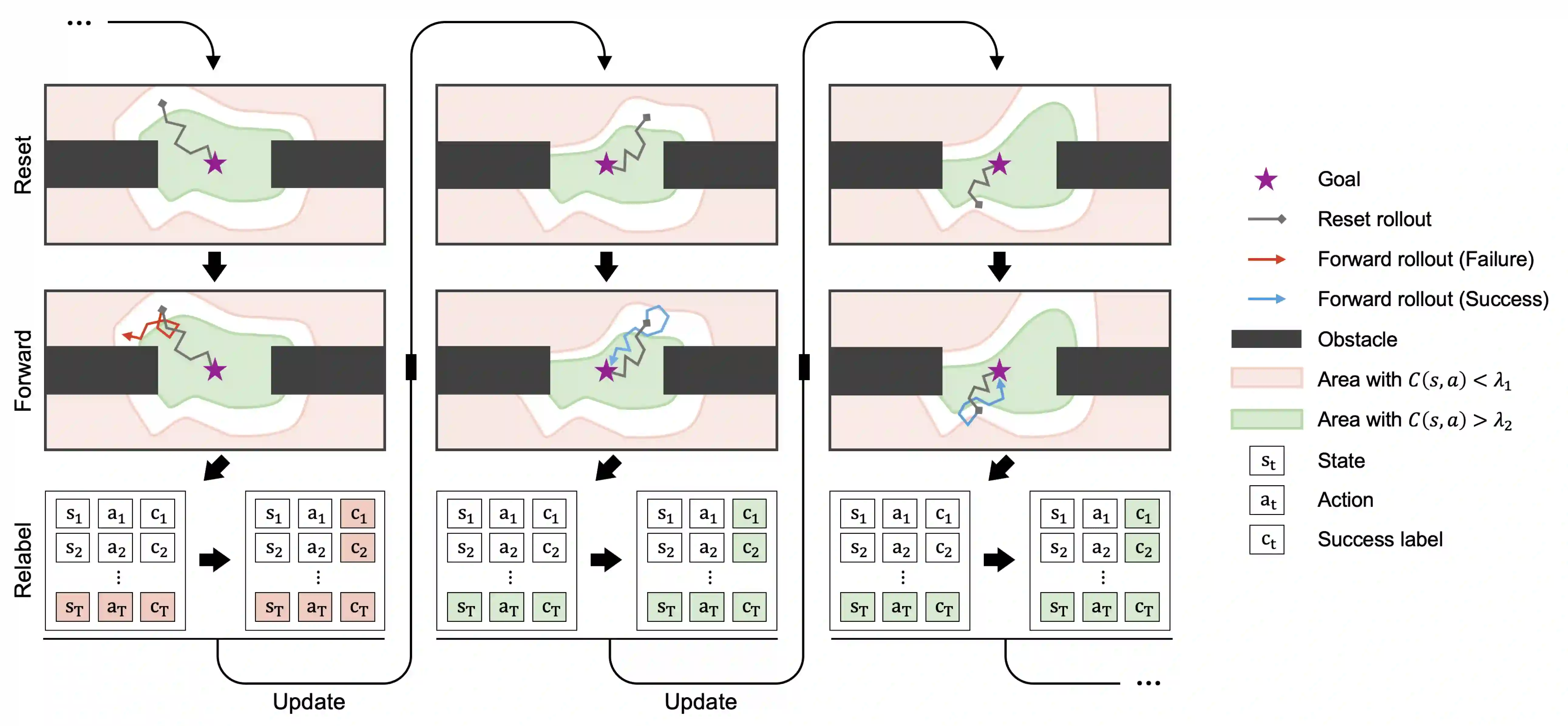
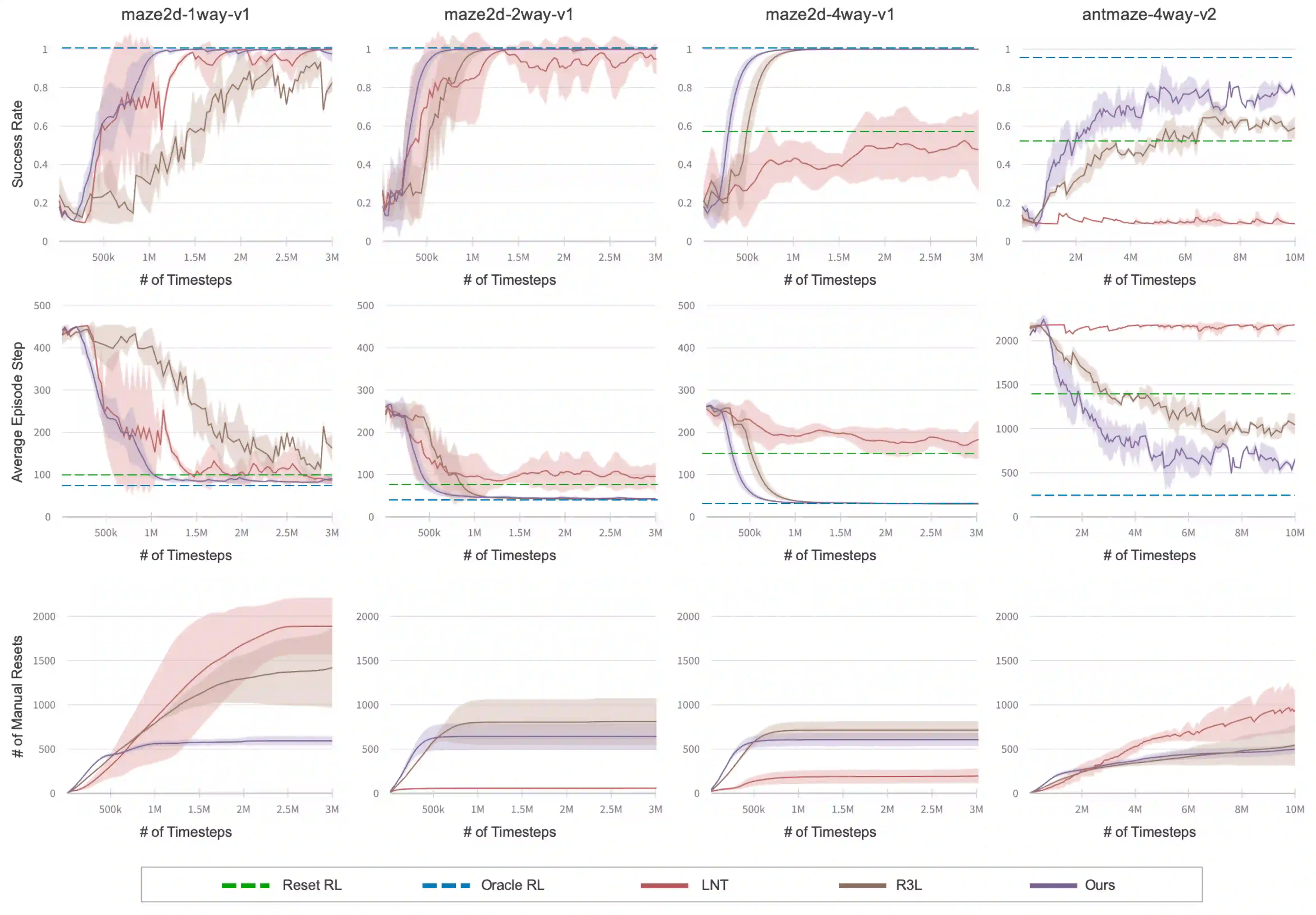
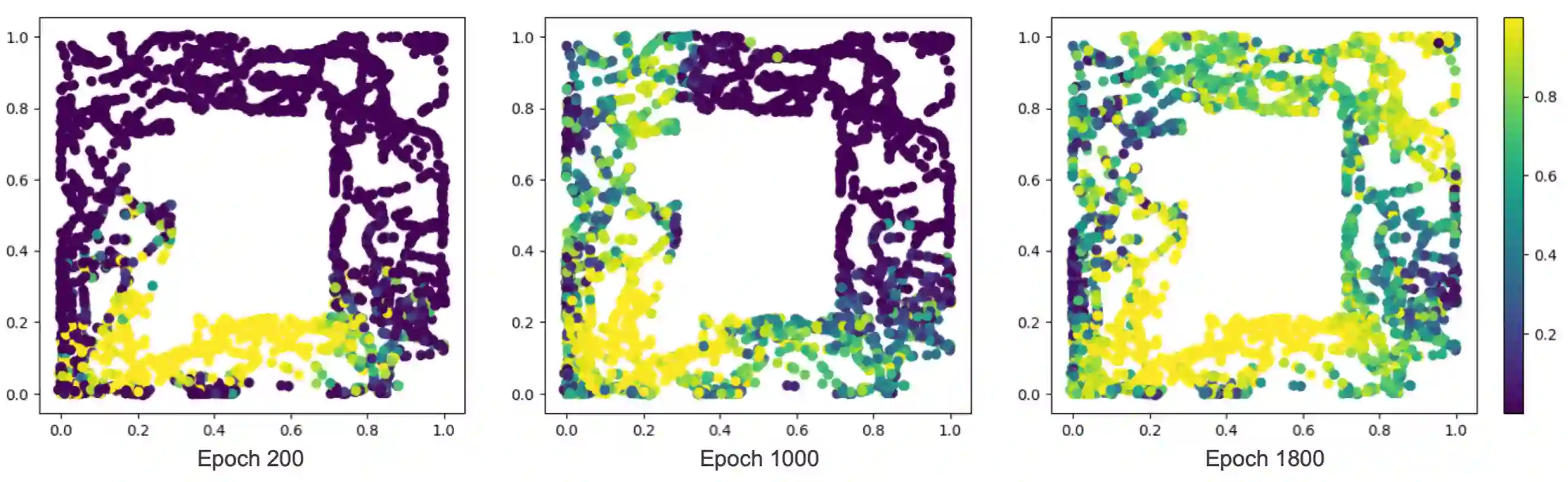
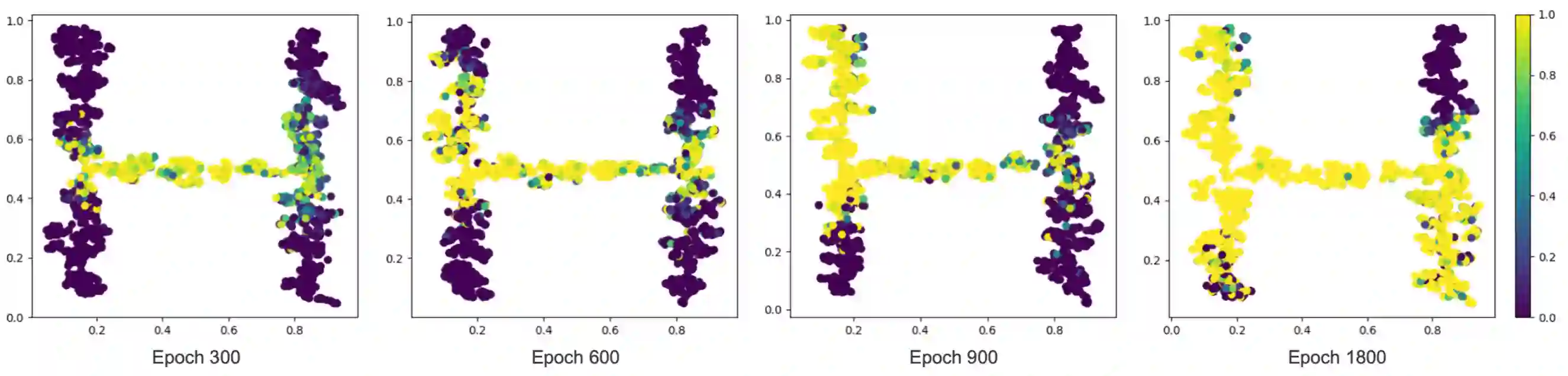
A significant bottleneck in applying current reinforcement learning algorithms to real-world scenarios is the need to reset the environment between every episode. This reset process demands substantial human intervention, making it difficult for the agent to learn continuously and autonomously. Several recent works have introduced autonomous reinforcement learning (ARL) algorithms that generate curricula for jointly training reset and forward policies. While their curricula can reduce the number of required manual resets by taking into account the agent's learning progress, they rely on task-specific knowledge, such as predefined initial states or reset reward functions. In this paper, we propose a novel ARL algorithm that can generate a curriculum adaptive to the agent's learning progress without task-specific knowledge. Our curriculum empowers the agent to autonomously reset to diverse and informative initial states. To achieve this, we introduce a success discriminator that estimates the success probability from each initial state when the agent follows the forward policy. The success discriminator is trained with relabeled transitions in a self-supervised manner. Our experimental results demonstrate that our ARL algorithm can generate an adaptive curriculum and enable the agent to efficiently bootstrap to solve sparse-reward maze navigation tasks, outperforming baselines with significantly fewer manual resets.
翻译:当前强化学习算法在现实场景应用中的一个主要瓶颈是需要在每个回合之间重置环境。这种重置过程需要大量人工干预,使得智能体难以持续自主地学习。近期多项研究提出了自主强化学习算法,通过生成联合训练重置策略与正向策略的课程来解决问题。尽管这些课程能通过考虑智能体的学习进度减少所需的人工重置次数,但它们依赖于任务特定知识,如预定义的初始状态或重置奖励函数。本文提出一种新颖的自主强化学习算法,能够在无需任务特定知识的情况下,生成自适应于智能体学习进度的课程。该课程使智能体能够自主重置到多样且信息丰富的初始状态。为实现这一目标,我们引入一个成功判别器,评估智能体在执行正向策略时从各初始状态出发的成功概率。该判别器通过重标注的转换以自监督方式进行训练。实验结果表明,本自主强化学习算法能生成自适应课程,并有效引导智能体高效启动以解决稀疏奖励迷宫导航任务,在显著减少人工重置次数的同时超越基线方法。