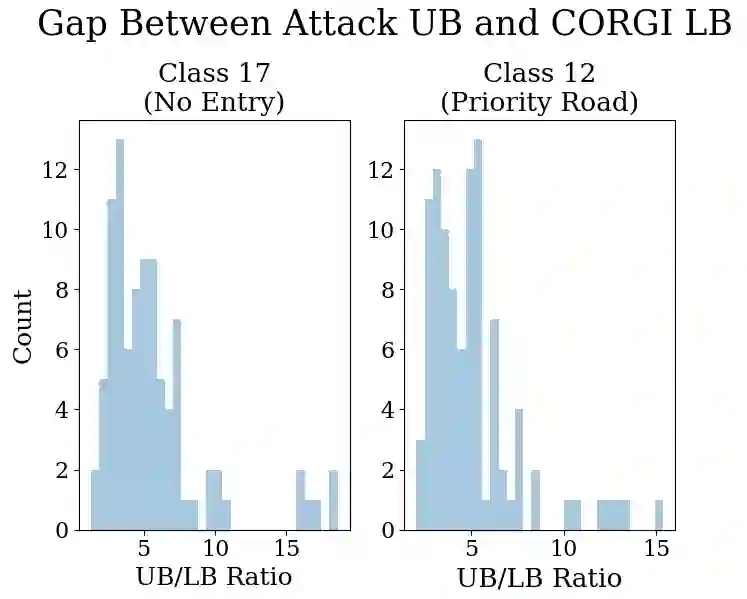
Interpreting machine learning models is challenging but crucial for ensuring the safety of deep networks in autonomous driving systems. Due to the prevalence of deep learning based perception models in autonomous vehicles, accurately interpreting their predictions is crucial. While a variety of such methods have been proposed, most are shown to lack robustness. Yet, little has been done to provide certificates for interpretability robustness. Taking a step in this direction, we present CORGI, short for Certifiably prOvable Robustness Guarantees for Interpretability mapping. CORGI is an algorithm that takes in an input image and gives a certifiable lower bound for the robustness of the top k pixels of its CAM interpretability map. We show the effectiveness of CORGI via a case study on traffic sign data, certifying lower bounds on the minimum adversarial perturbation not far from (4-5x) state-of-the-art attack methods.
翻译:解释机器学习模型具有挑战性但对确保自动驾驶系统中深度网络的安全性至关重要。由于基于深度学习的感知模型在自动驾驶车辆中的普遍应用,准确解释其预测结果尤为重要。尽管已有多种此类方法被提出,但大多数被证明缺乏鲁棒性。然而,目前尚未有研究为可解释性鲁棒性提供认证。为向此方向迈出一步,我们提出CORGI(可认证可解释性映射鲁棒性保证的简称)。CORGI是一种算法,它接收输入图像,并为其CAM可解释性映射中前k个像素的鲁棒性提供可认证的下界。我们通过在交通标志数据上的案例研究证明了CORGI的有效性,其对最小对抗扰动下界的认证结果与最先进的攻击方法相比差距不大(4-5倍)。