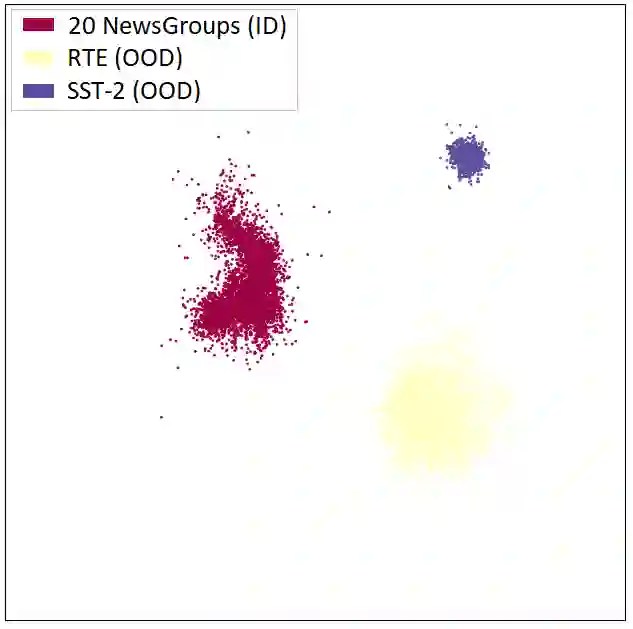
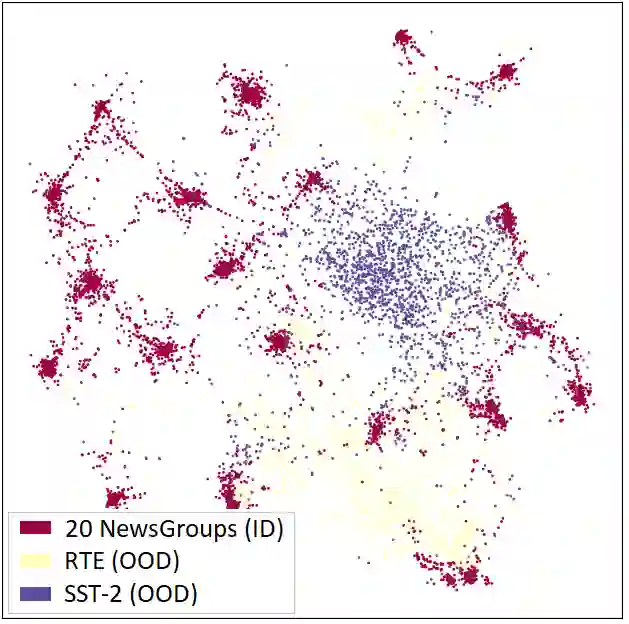
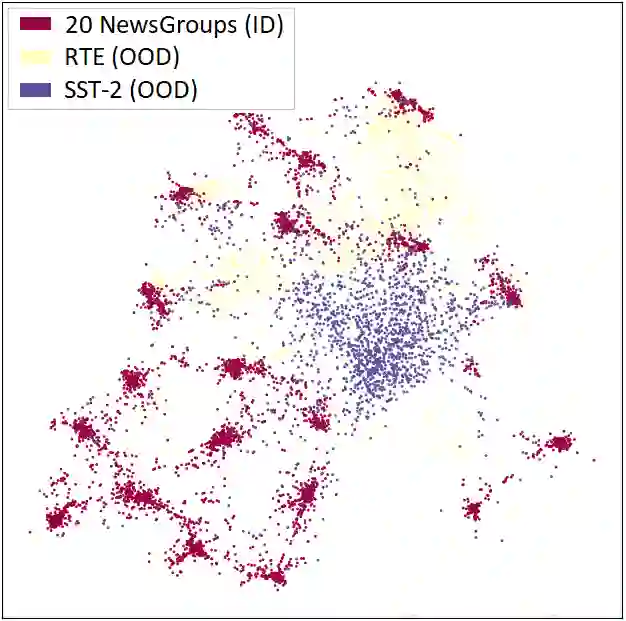
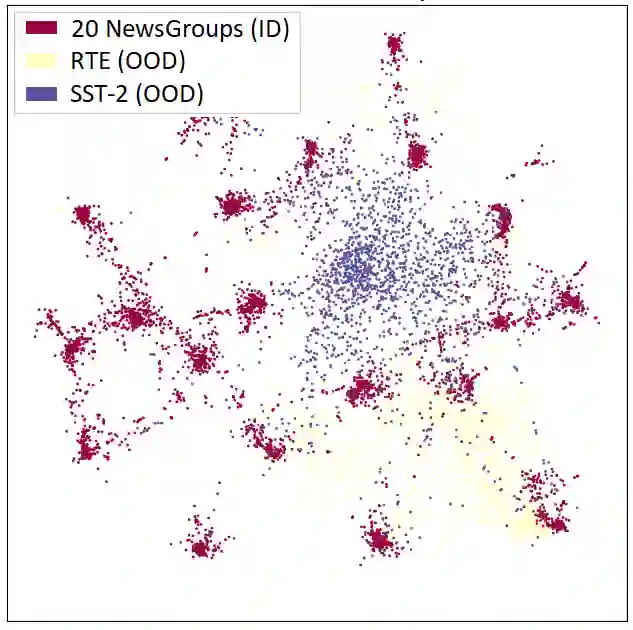
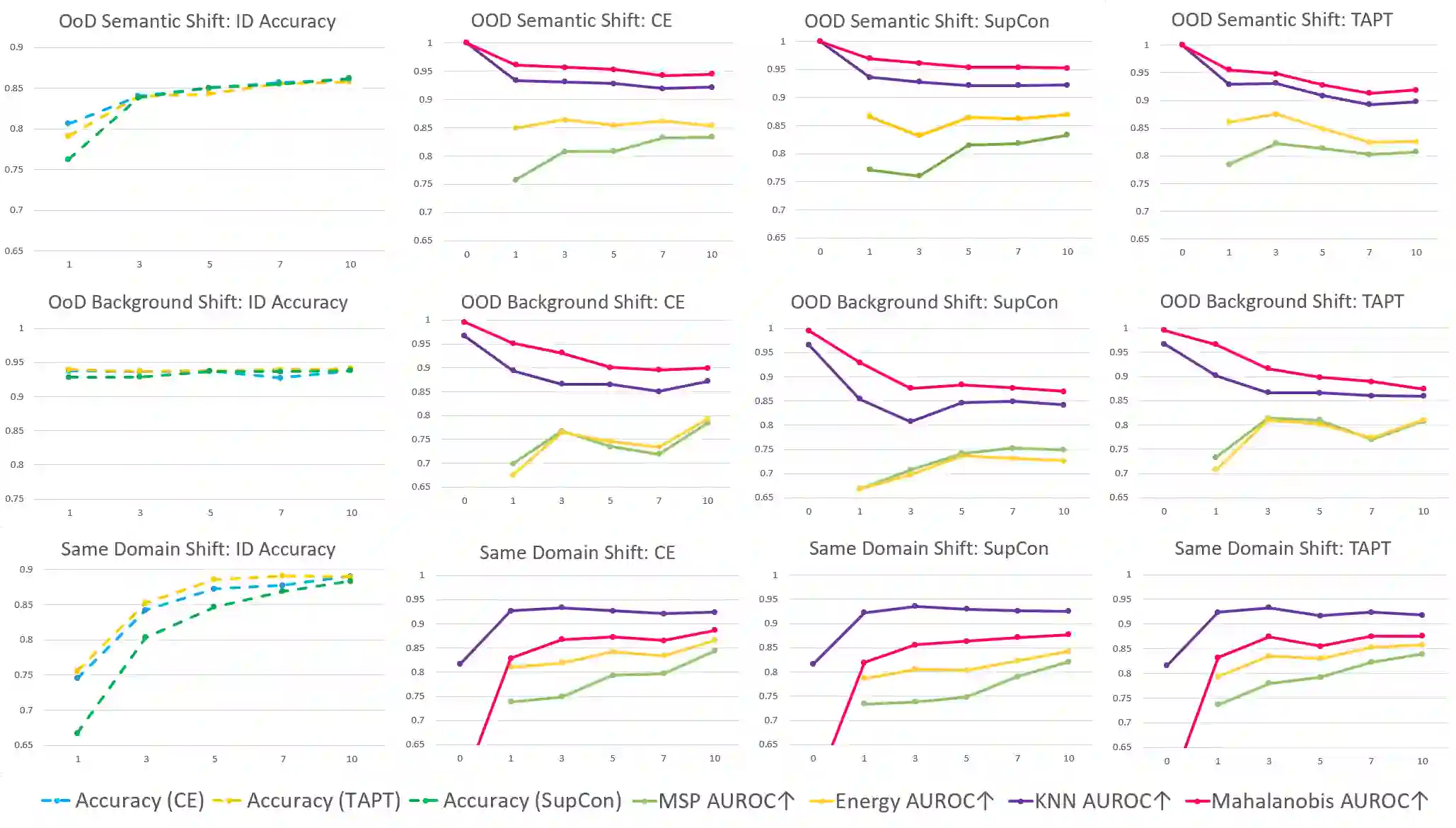
Out-of-distribution (OOD) detection is a critical task for reliable predictions over text. Fine-tuning with pre-trained language models has been a de facto procedure to derive OOD detectors with respect to in-distribution (ID) data. Despite its common use, the understanding of the role of fine-tuning and its necessity for OOD detection is largely unexplored. In this paper, we raise the question: is fine-tuning necessary for OOD detection? We present a study investigating the efficacy of directly leveraging pre-trained language models for OOD detection, without any model fine-tuning on the ID data. We compare the approach with several competitive fine-tuning objectives, and offer new insights under various types of distributional shifts. Extensive evaluations on 8 diverse ID-OOD dataset pairs demonstrate near-perfect OOD detection performance (with 0% FPR95 in many cases), strongly outperforming its fine-tuned counterparts. We show that using distance-based detection methods, pre-trained language models are near-perfect OOD detectors when the distribution shift involves a domain change. Furthermore, we study the effect of fine-tuning on OOD detection and identify how to balance ID accuracy with OOD detection performance. Our code is publically available at https://github.com/Uppaal/lm-ood.
翻译:分布外(OOD)检测是实现文本可靠预测的关键任务。基于预训练语言模型进行微调,已成为针对分布内(ID)数据构建OOD检测器的标准流程。尽管微调被广泛使用,但其在OOD检测中的作用及必要性仍未得到充分探究。本文提出疑问:OOD检测是否需要微调?我们开展了一项研究,探讨直接利用预训练语言模型进行OOD检测(无需在ID数据上进行任何模型微调)的有效性。我们将该方法与多种具有竞争力的微调目标函数进行对比,并在各类分布偏移场景下提出新见解。在8组不同的ID-OOD数据集对上的广泛评估表明,该方法实现了近乎完美的OOD检测性能(许多情况下FPR95为0%),显著优于微调方法。我们证明,当分布偏移涉及领域变化时,采用基于距离的检测方法,预训练语言模型可作为近乎完美的OOD检测器。此外,我们研究了微调对OOD检测的影响,并明确了如何在ID准确率与OOD检测性能之间取得平衡。我们的代码已公开于https://github.com/Uppaal/lm-ood。