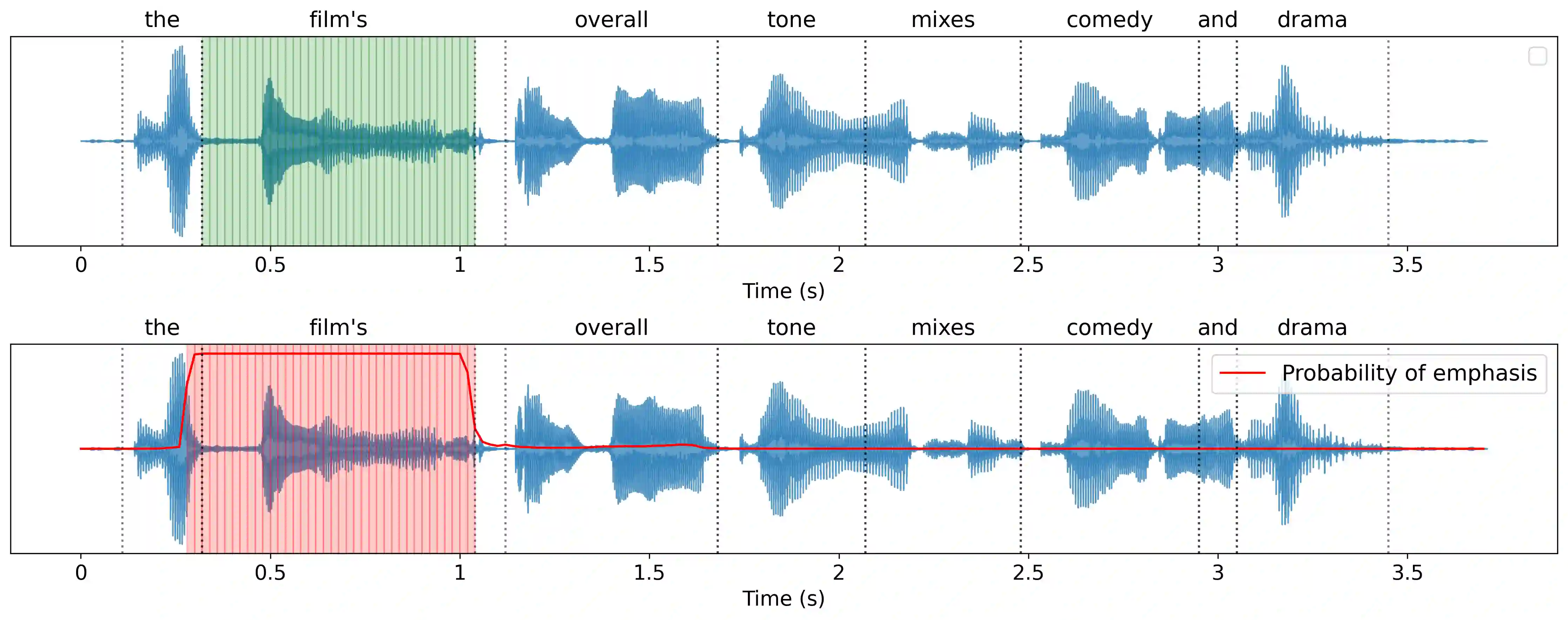
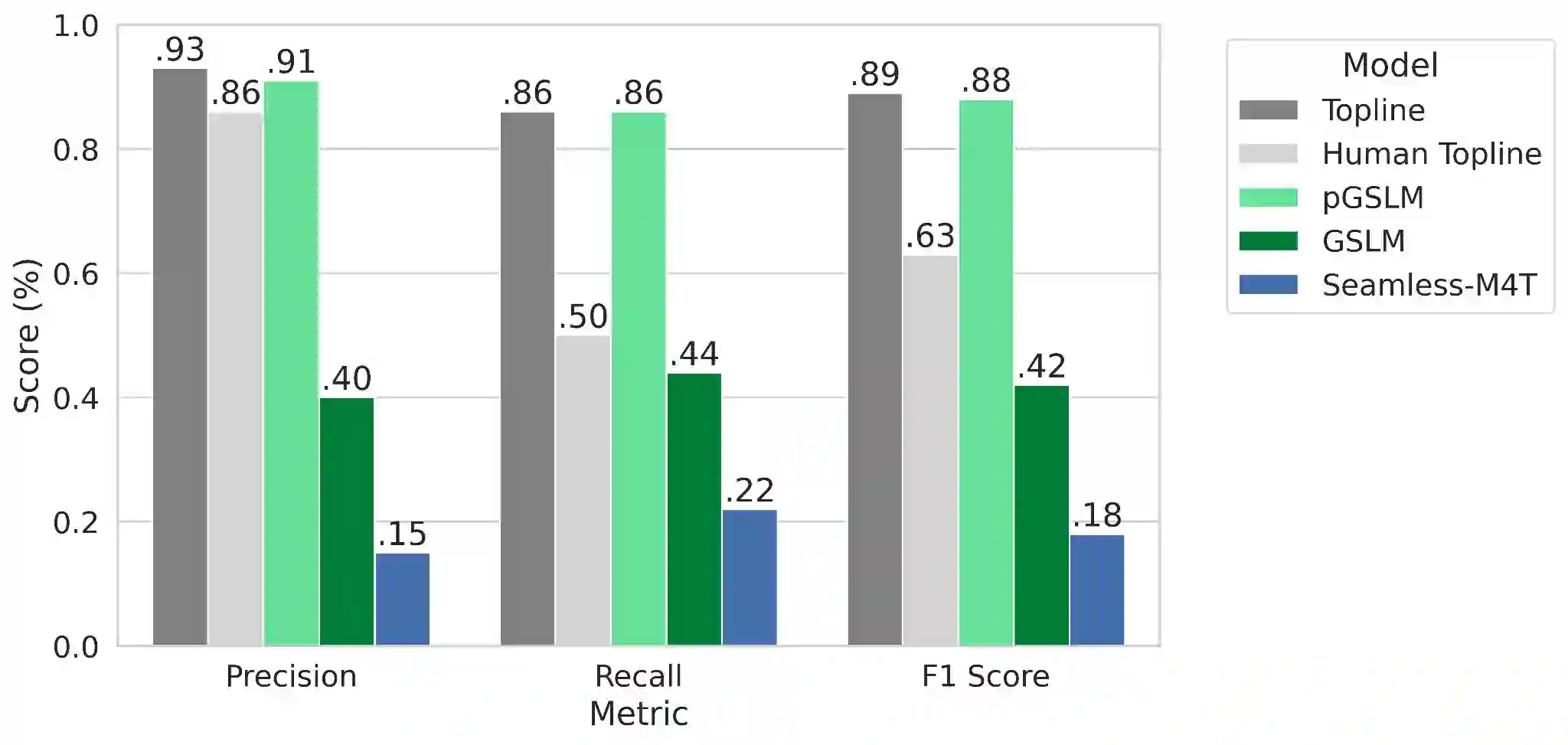
We introduce EmphAssess, a prosodic benchmark designed to evaluate the capability of speech-to-speech models to encode and reproduce prosodic emphasis. We apply this to two tasks: speech resynthesis and speech-to-speech translation. In both cases, the benchmark evaluates the ability of the model to encode emphasis in the speech input and accurately reproduce it in the output, potentially across a change of speaker and language. As part of the evaluation pipeline, we introduce EmphaClass, a new model that classifies emphasis at the frame or word level.
翻译:我们提出了EmphAssess,一个旨在评估语音到语音模型编码和再现韵律强调能力的韵律基准。我们将该基准应用于两项任务:语音重合成和语音到语音翻译。在这两种情况下,该基准均评估模型对语音输入中强调信息的编码能力,并在输出中准确再现该强调的能力,其中可能涉及说话人和语言的变更。作为评估流程的一部分,我们引入了EmphaClass,这是一个新模型,可在帧级或词级对强调进行分类。