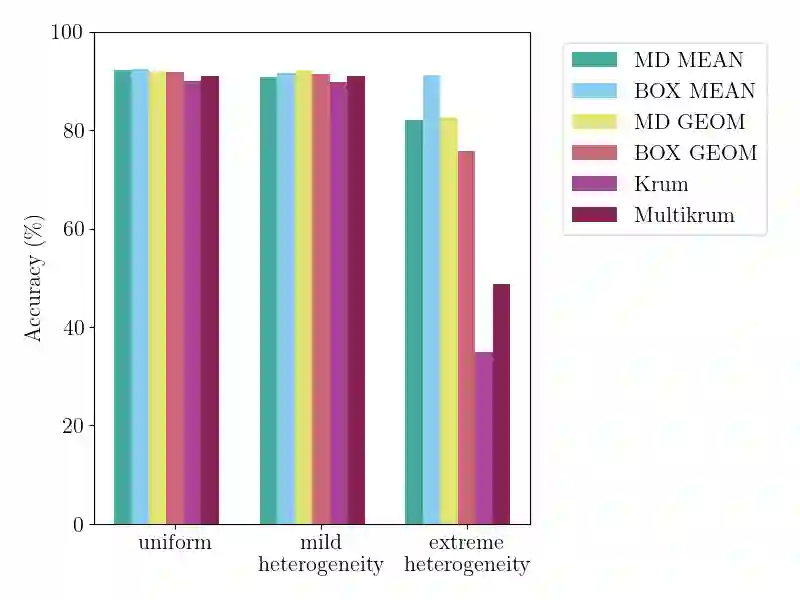
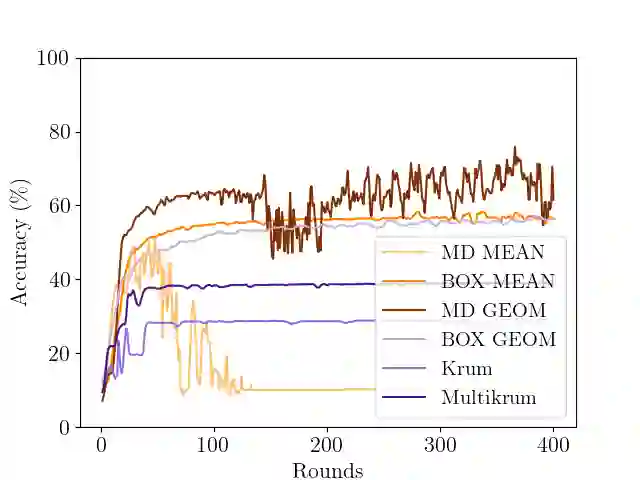
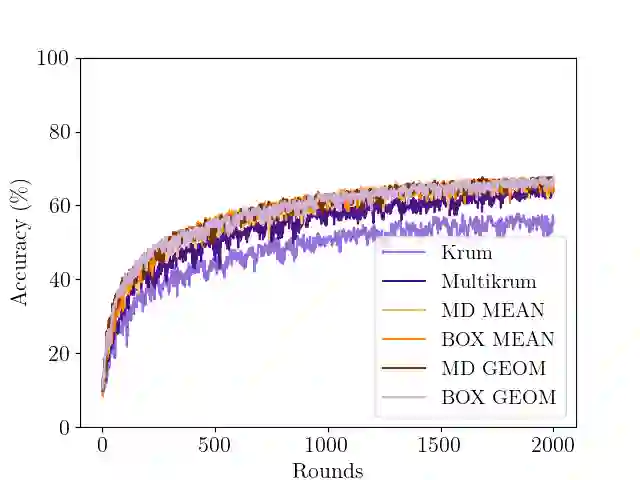
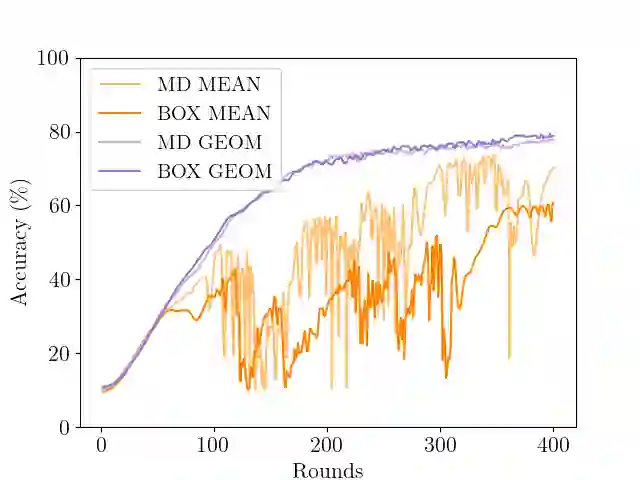
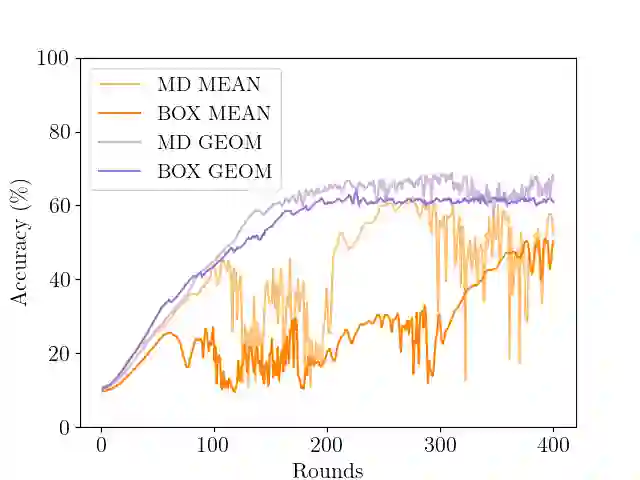
In Byzantine collaborative learning, $n$ clients in a peer-to-peer network collectively learn a model without sharing their data by exchanging and aggregating stochastic gradient estimates. Byzantine clients can prevent others from collecting identical sets of gradient estimates. The aggregation step thus needs to be combined with an efficient (approximate) agreement subroutine to ensure convergence of the training process. In this work, we study the geometric median aggregation rule for Byzantine collaborative learning. We show that known approaches do not provide theoretical guarantees on convergence or gradient quality in the agreement subroutine. To satisfy these theoretical guarantees, we present a hyperbox algorithm for geometric median aggregation. We practically evaluate our algorithm in both centralized and decentralized settings under Byzantine attacks on non-i.i.d. data. We show that our geometric median-based approaches can tolerate sign-flip attacks better than known mean-based approaches from the literature.
翻译:在拜占庭协作学习中,点对点网络中的$n$个客户端通过交换和聚合随机梯度估计来协同学习模型,而无需共享其数据。拜占庭客户端可以阻止其他客户端收集相同的梯度估计集合。因此,聚合步骤需要与高效的(近似)一致性子程序相结合,以确保训练过程的收敛性。在本研究中,我们探讨了拜占庭协作学习中的几何中位数聚合规则。我们发现现有方法在一致性子程序中无法提供关于收敛性或梯度质量的理论保证。为满足这些理论保证,我们提出了一种用于几何中位数聚合的超立方体算法。我们在集中式和去中心化设置下,对非独立同分布数据遭受拜占庭攻击的场景中进行了算法实践评估。实验表明,基于几何中位数的方法比文献中已知的基于均值的方法能更好地抵御符号翻转攻击。