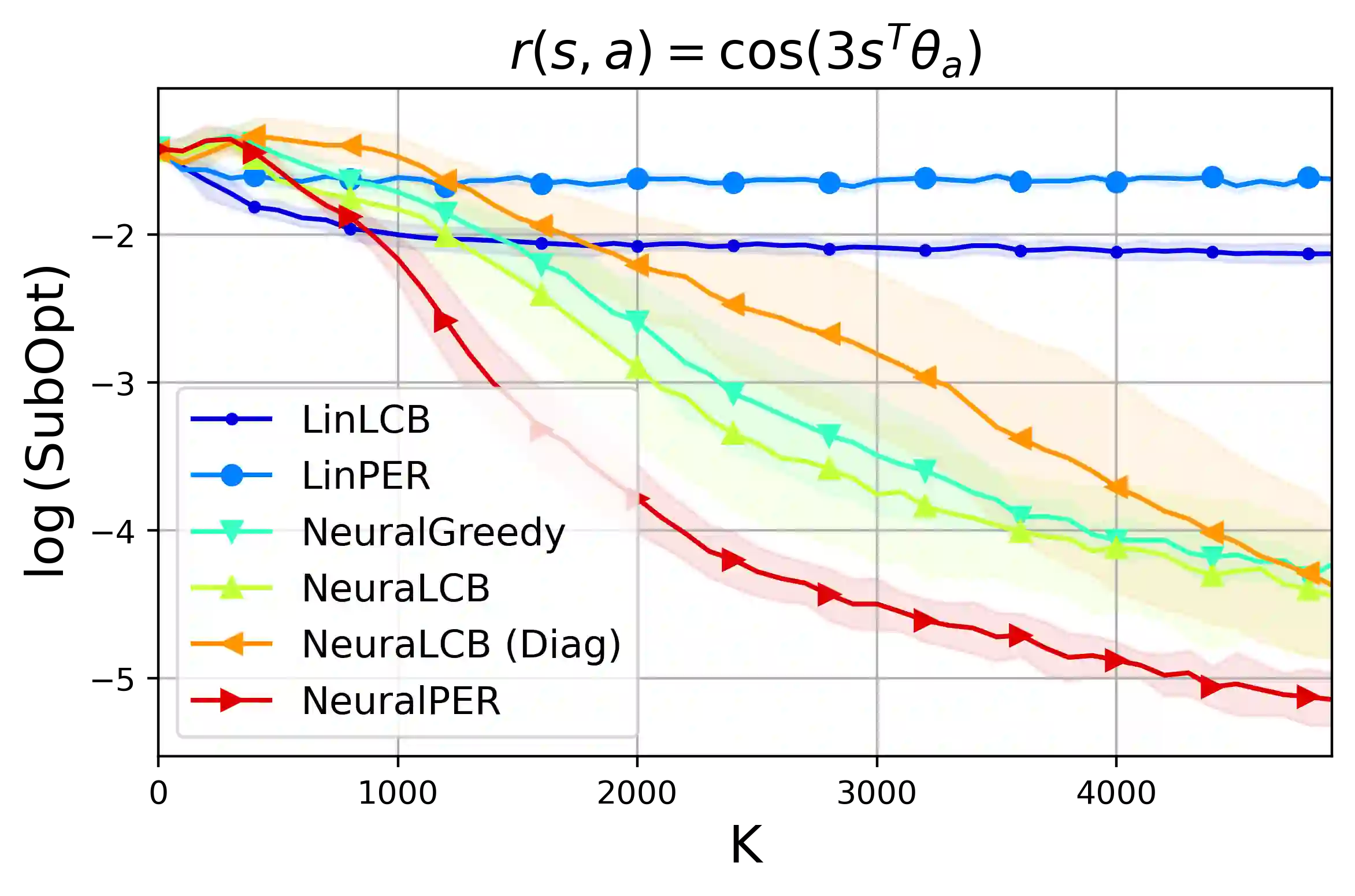
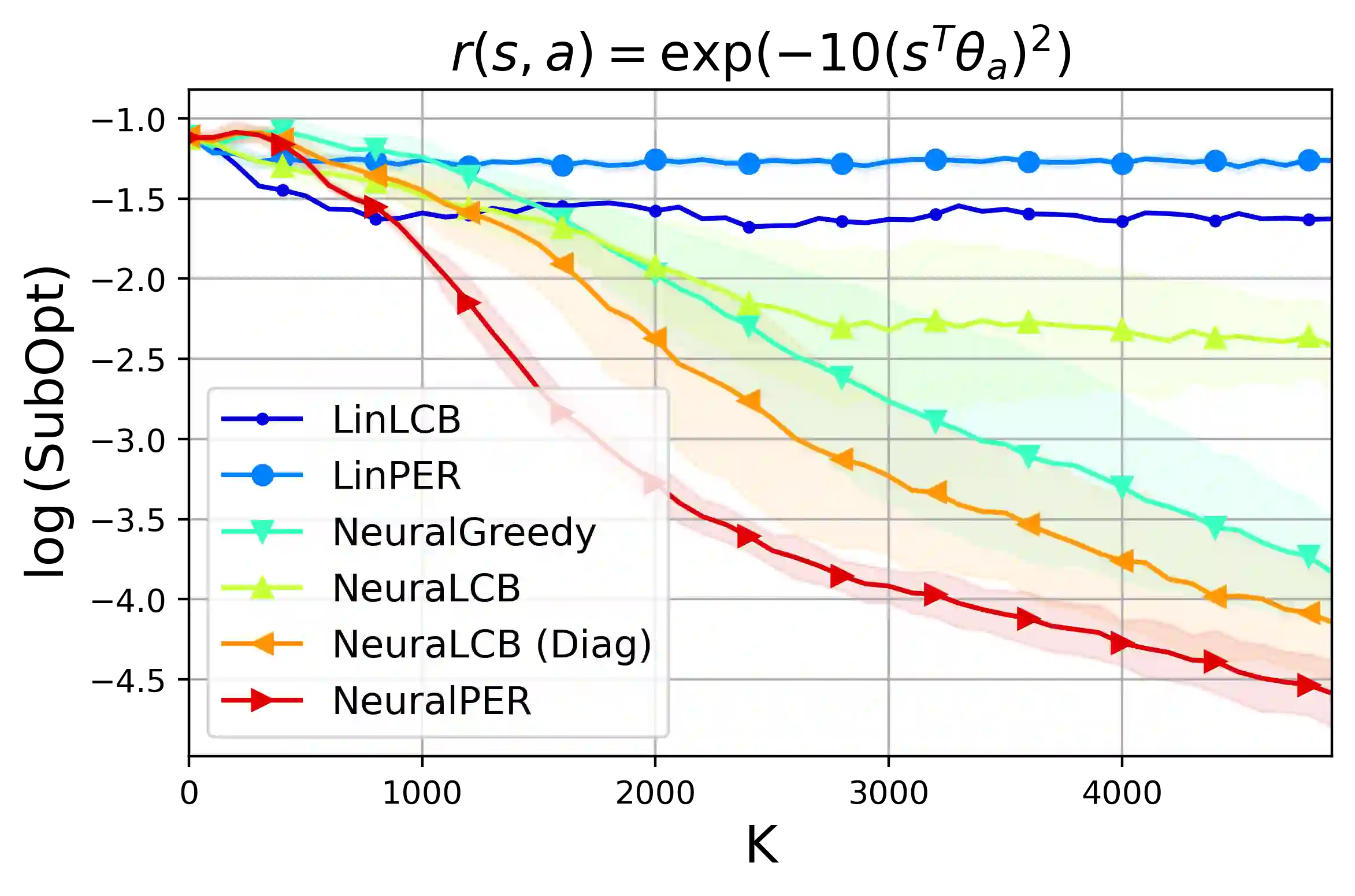
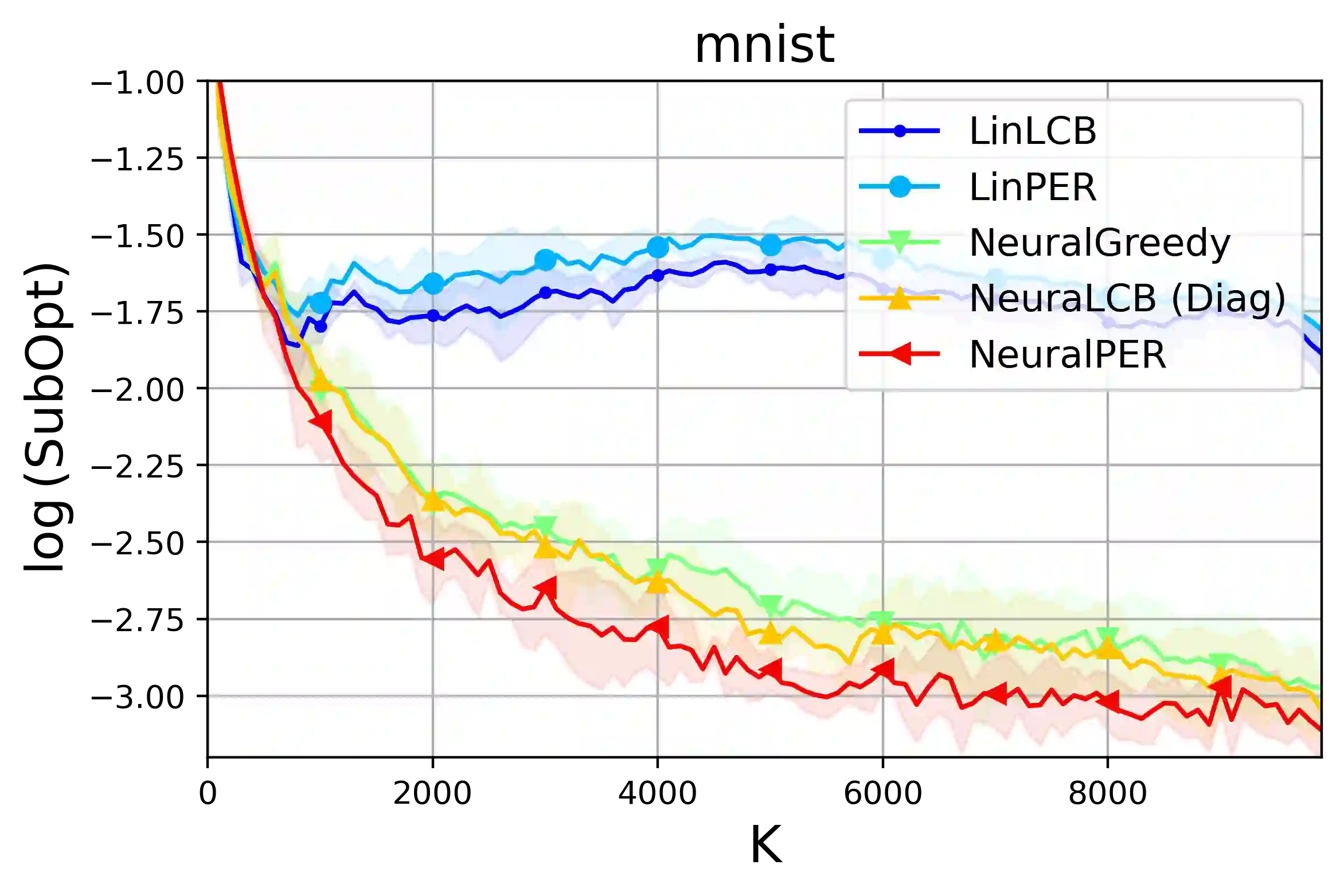
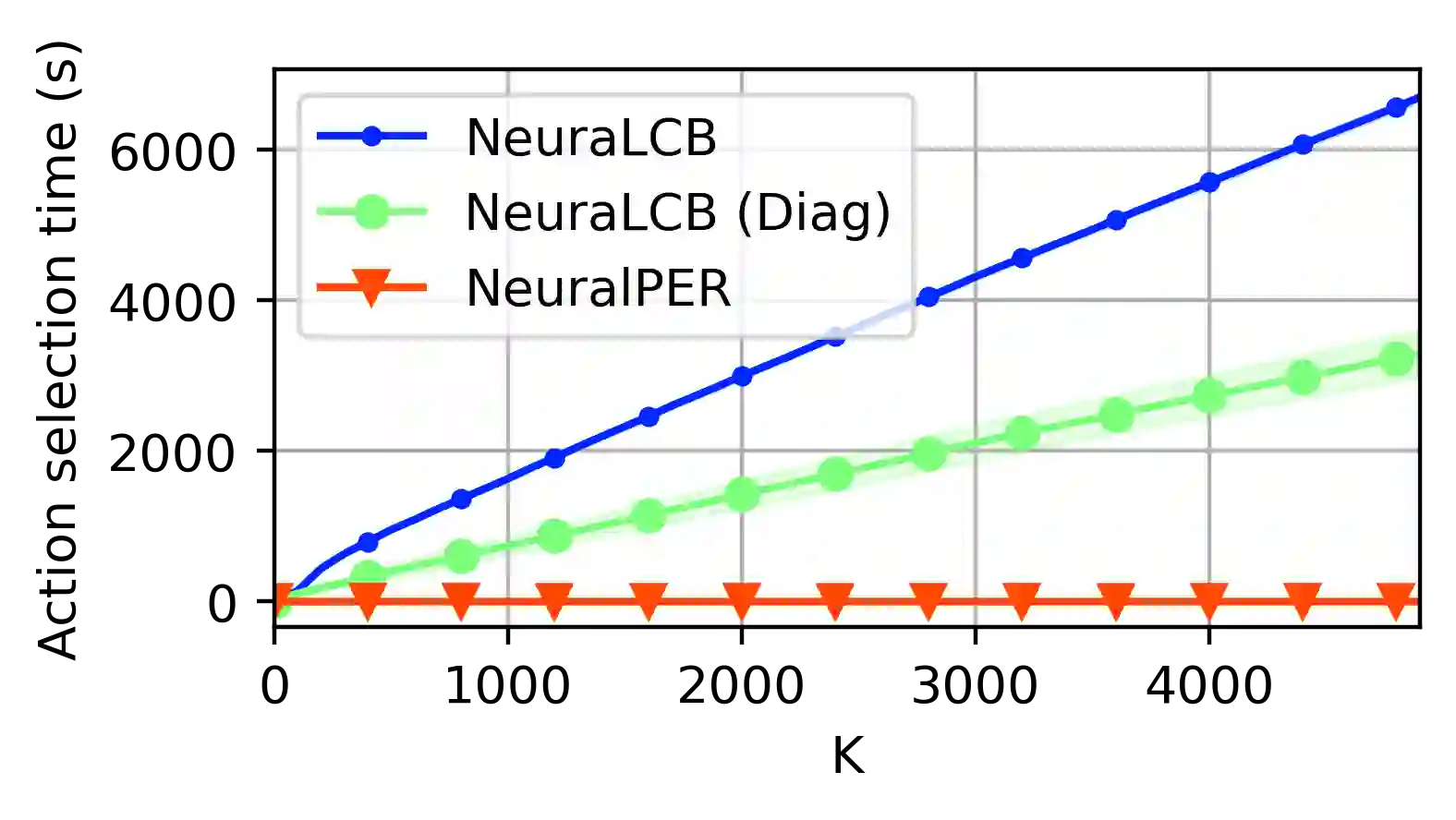
We propose a novel offline reinforcement learning (RL) algorithm, namely Value Iteration with Perturbed Rewards (VIPeR) which amalgamates the randomized value function idea with the pessimism principle. Most current offline RL algorithms explicitly construct statistical confidence regions to obtain pessimism via lower confidence bounds (LCB), which cannot easily scale to complex problems where a neural network is used to estimate the value functions. Instead, VIPeR implicitly obtains pessimism by simply perturbing the offline data multiple times with carefully-designed i.i.d Gaussian noises to learn an ensemble of estimated state-action values and acting greedily to the minimum of the ensemble. The estimated state-action values are obtained by fitting a parametric model (e.g. neural networks) to the perturbed datasets using gradient descent. As a result, VIPeR only needs $\mathcal{O}(1)$ time complexity for action selection while LCB-based algorithms require at least $\Omega(K^2)$, where $K$ is the total number of trajectories in the offline data. We also propose a novel data splitting technique that helps remove the potentially large log covering number in the learning bound. We prove that VIPeR yields a provable uncertainty quantifier with overparameterized neural networks and achieves an $\tilde{\mathcal{O}}\left( \frac{ \kappa H^{5/2} \tilde{d} }{\sqrt{K}} \right)$ sub-optimality where $\tilde{d}$ is the effective dimension, $H$ is the horizon length and $\kappa$ measures the distributional shift. We corroborate the statistical and computational efficiency of VIPeR with an empirical evaluation in a wide set of synthetic and real-world datasets. To the best of our knowledge, VIPeR is the first offline RL algorithm that is both provably and computationally efficient in general Markov decision processes (MDPs) with neural network function approximation.
翻译:我们提出了一种新的离线强化学习算法,即基于扰动奖励的值迭代算法(VIPeR),该算法融合了随机化价值函数思想与悲观原则。当前大多数离线强化学习算法通过显式构建统计置信区域并利用置信下界(LCB)实现悲观性,但这类方法难以扩展到使用神经网络估计价值函数的复杂问题。VIPeR则通过简单地对离线数据多次添加精心设计的独立同分布高斯噪声扰动来隐式实现悲观性,从而学习估计状态-动作值的集成模型,并对集成模型的最小值执行贪心策略。估计的状态-动作值通过利用梯度下降对扰动数据集拟合参数化模型(如神经网络)获得。因此,VIPeR在动作选择时仅需$\mathcal{O}(1)$的时间复杂度,而基于LCB的算法至少需要$\Omega(K^2)$,其中$K$为离线数据中的轨迹总数。我们还提出了一种新的数据分割技术,有助于消除学习界限中潜在的大对数覆盖数。我们证明,VIPeR通过过参数化神经网络可生成可证明的不确定性量化器,并实现$\tilde{\mathcal{O}}\left( \frac{ \kappa H^{5/2} \tilde{d} }{\sqrt{K}} \right)$的次优性上界,其中$\tilde{d}$为有效维度,$H$为水平长度,$\kappa$度量分布偏移。我们通过在合成数据集和真实数据集上的广泛实验验证了VIPeR的统计与计算效率。据我们所知,VIPeR是首个在具有神经网络函数逼近的一般马尔可夫决策过程(MDPs)中同时实现可证明高效性和计算效率的离线强化学习算法。