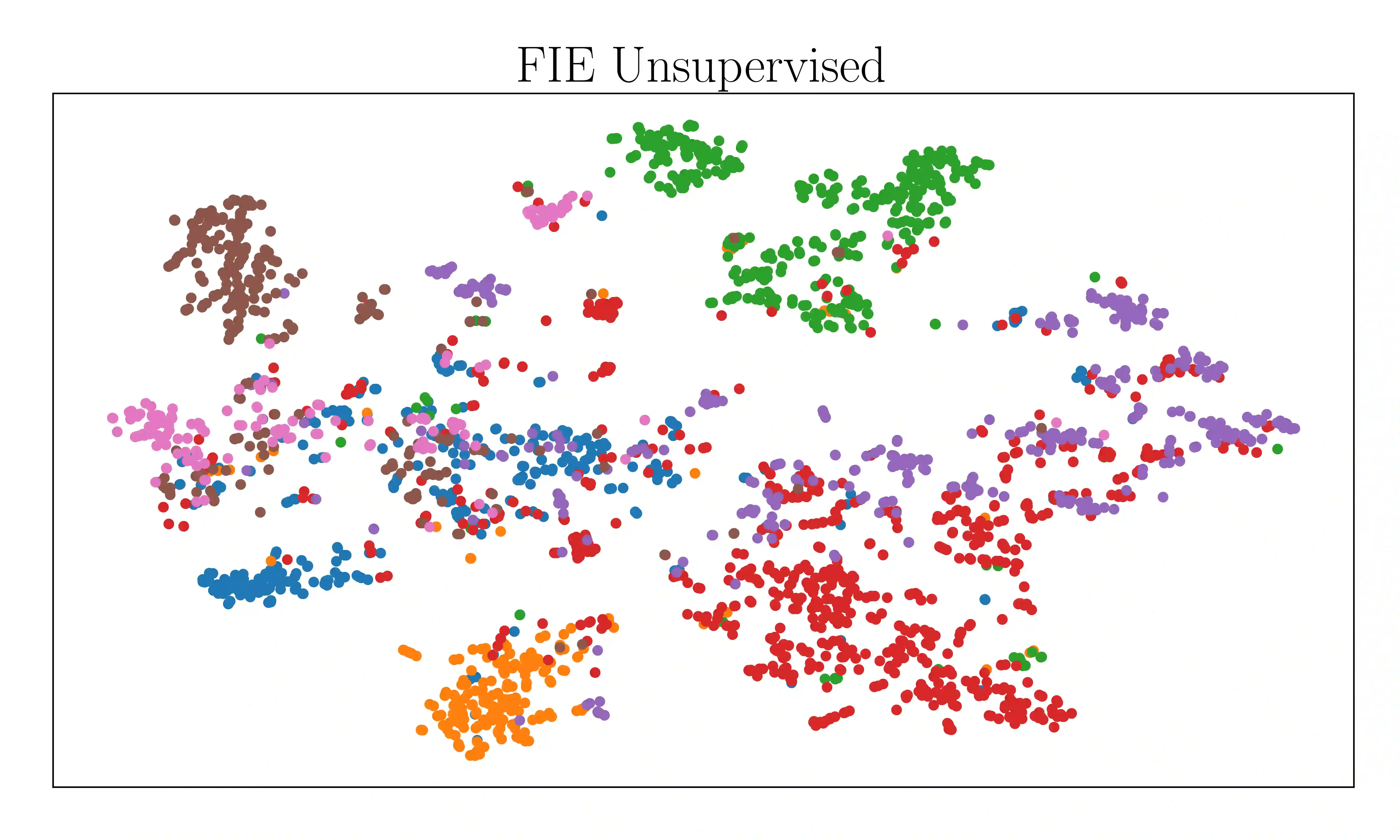
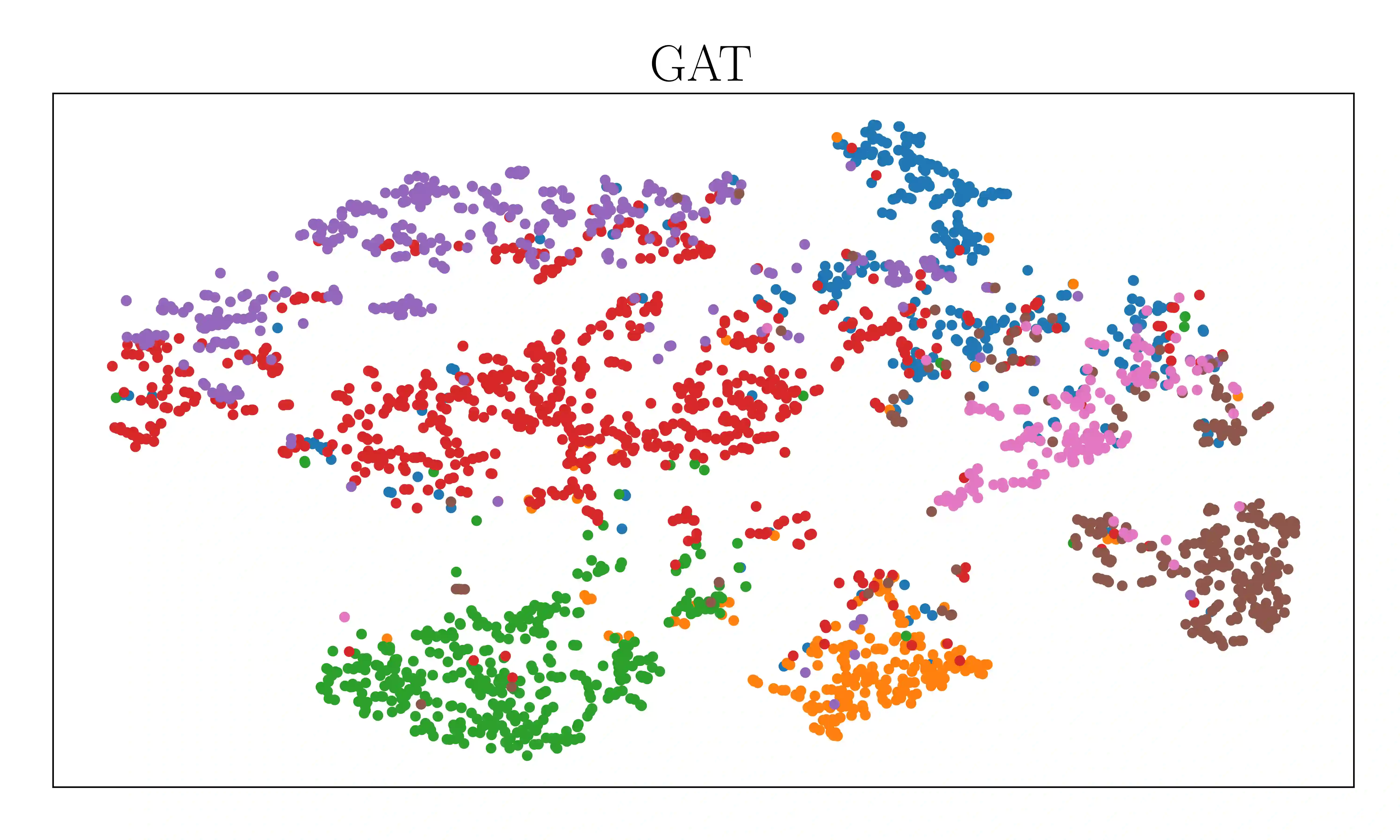
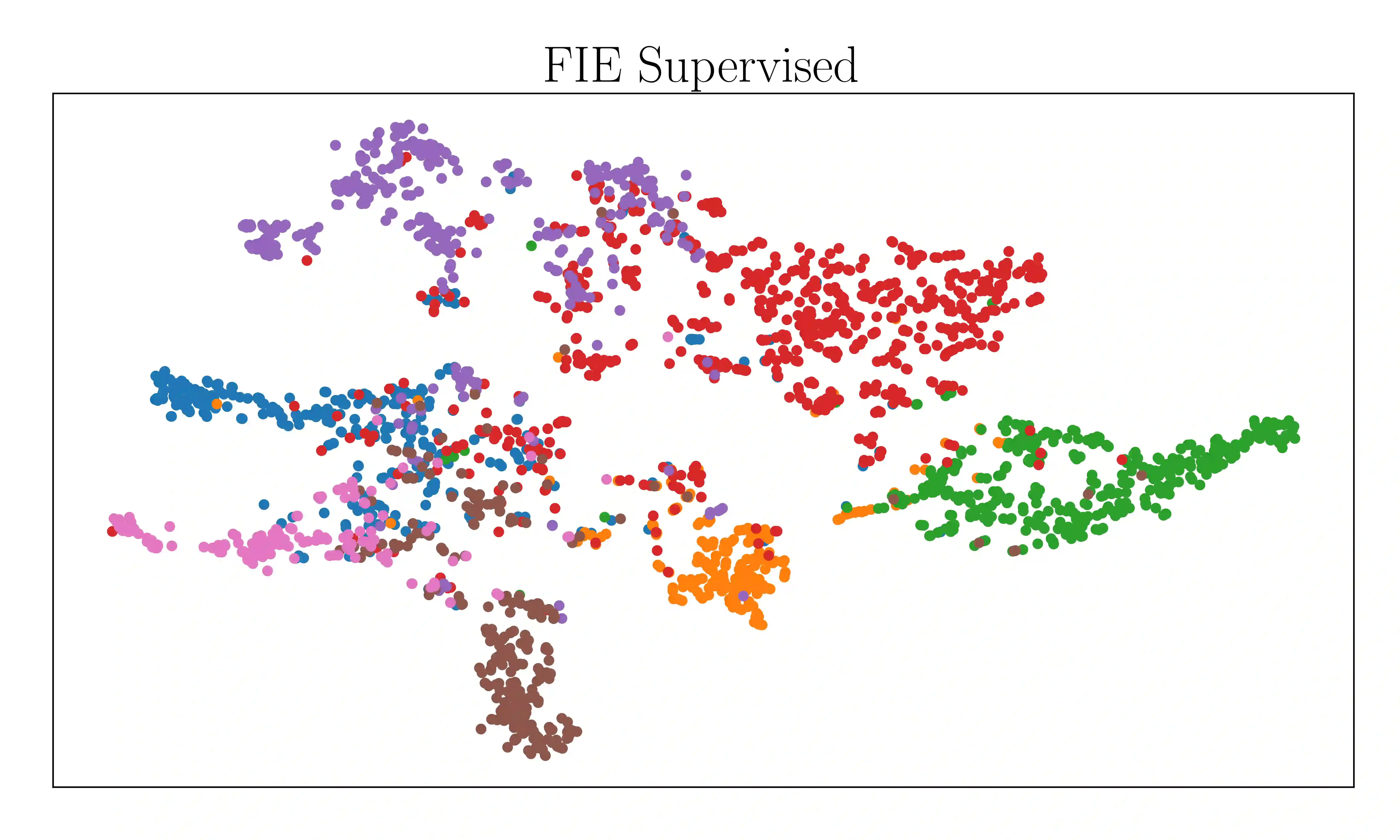
Attention-based graph neural networks (GNNs), such as graph attention networks (GATs), have become popular neural architectures for processing graph-structured data and learning node embeddings. Despite their empirical success, these models rely on labeled data and the theoretical properties of these models have yet to be fully understood. In this work, we propose a novel attention-based node embedding framework for graphs. Our framework builds upon a hierarchical kernel for multisets of subgraphs around nodes (e.g. neighborhoods) and each kernel leverages the geometry of a smooth statistical manifold to compare pairs of multisets, by "projecting" the multisets onto the manifold. By explicitly computing node embeddings with a manifold of Gaussian mixtures, our method leads to a new attention mechanism for neighborhood aggregation. We provide theoretical insights into genralizability and expressivity of our embeddings, contributing to a deeper understanding of attention-based GNNs. We propose efficient unsupervised and supervised methods for learning the embeddings, with the unsupervised method not requiring any labeled data. Through experiments on several node classification benchmarks, we demonstrate that our proposed method outperforms existing attention-based graph models like GATs. Our code is available at https://github.com/BorgwardtLab/fisher_information_embedding.
翻译:基于注意力的图神经网络(如图注意力网络GAT)已成为处理图结构数据和学习的节点嵌入的流行神经架构。尽管这些模型在实证中取得成功,但它们依赖标注数据,且其理论性质尚未完全明晰。本文提出一种新颖的基于注意力的图节点嵌入框架。该框架构建于节点周围子图多重集(如邻域)的层次化核函数之上,每个核函数利用光滑统计流形的几何结构,通过将多重集“投影”到流形上,实现多重集对的比较。通过使用高斯混合流形显式计算节点嵌入,我们的方法衍生出一种用于邻域聚合的新型注意力机制。我们提供了关于嵌入可泛化性与表达力的理论洞见,从而加深对基于注意力的GNN的理解。我们提出了高效的嵌入学习方法,包括无需标注数据的无监督方法。在多个节点分类基准上的实验表明,我们提出的方法优于GAT等现有基于注意力的图模型。我们的代码开源在https://github.com/BorgwardtLab/fisher_information_embedding。