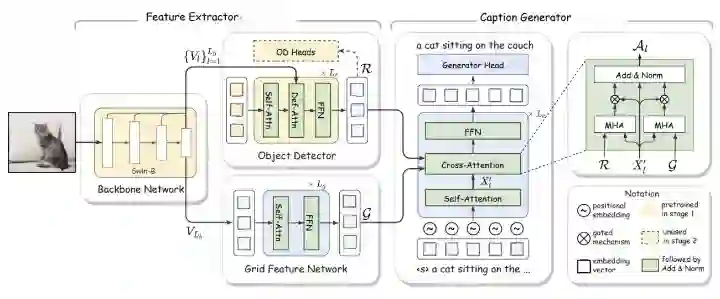
This work presents the early development of a model of image captioning for the Brazilian Portuguese language. We used the GRIT (Grid - and Region-based Image captioning Transformer) model to accomplish this work. GRIT is a Transformer-only neural architecture that effectively utilizes two visual features to generate better captions. The GRIT method emerged as a proposal to be a more efficient way to generate image captioning. In this work, we adapt the GRIT model to be trained in a Brazilian Portuguese dataset to have an image captioning method for the Brazilian Portuguese Language.
翻译:本文介绍了针对巴西葡萄牙语的图像描述生成模型的早期开发工作。我们采用GRIT(基于网格与区域的图像描述生成Transformer)模型来完成此项研究。GRIT是一种纯Transformer神经架构,通过有效利用两种视觉特征生成更优质的描述文本。该方法作为一种更高效的图像描述生成方案被提出。在本工作中,我们对GRIT模型进行适配,使其能够在巴西葡萄牙语数据集上进行训练,从而构建适用于巴西葡萄牙语的图像描述生成方法。