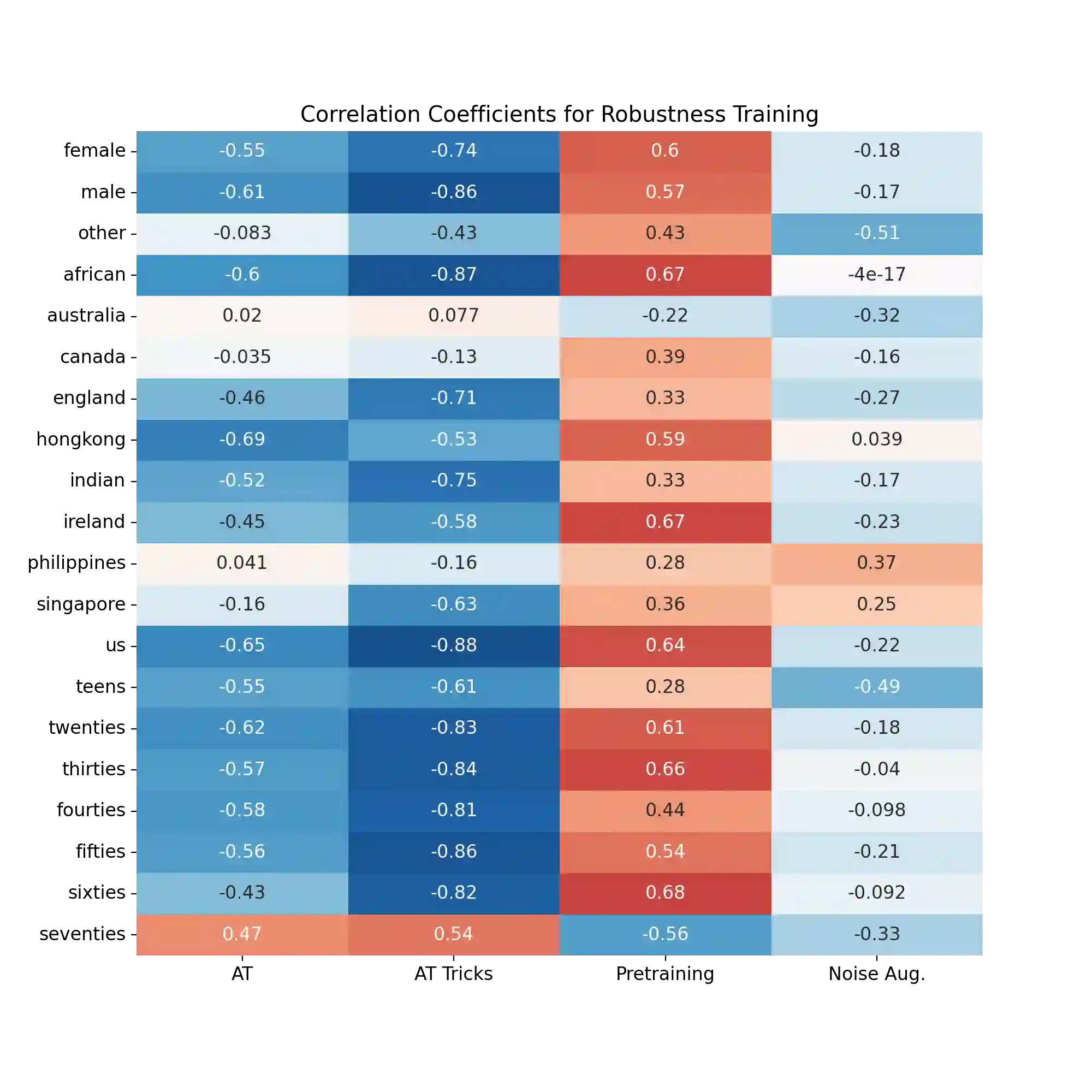
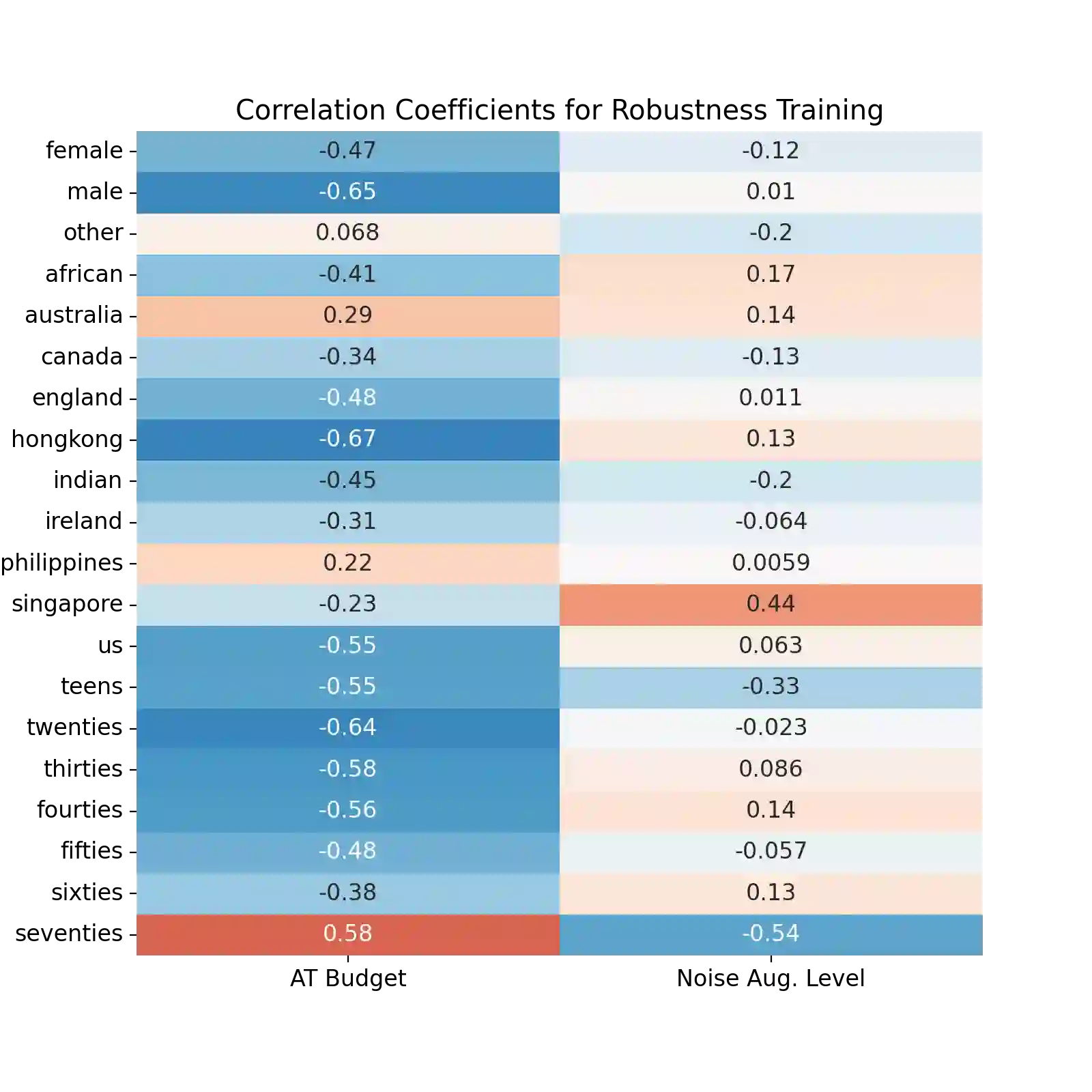
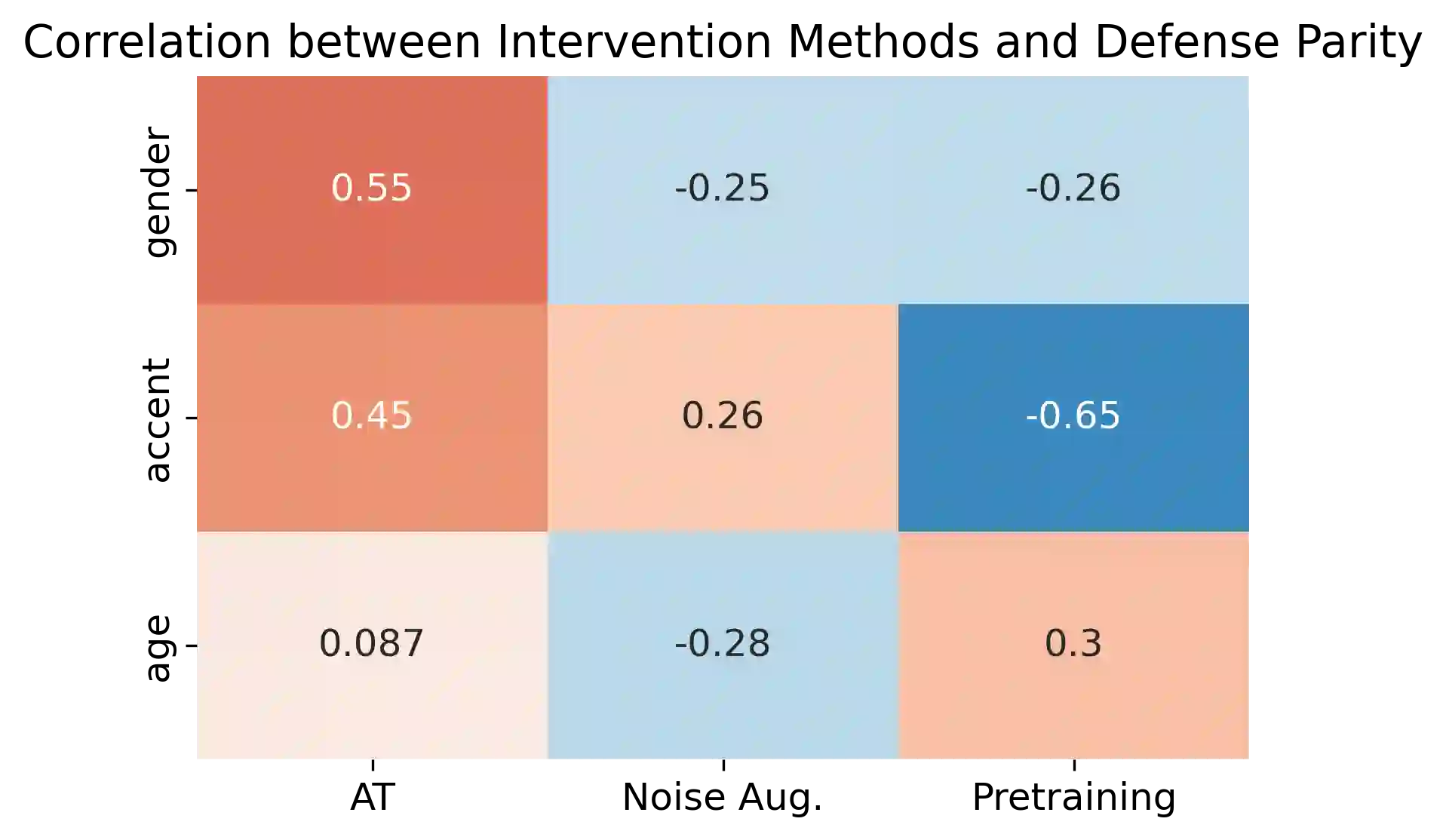
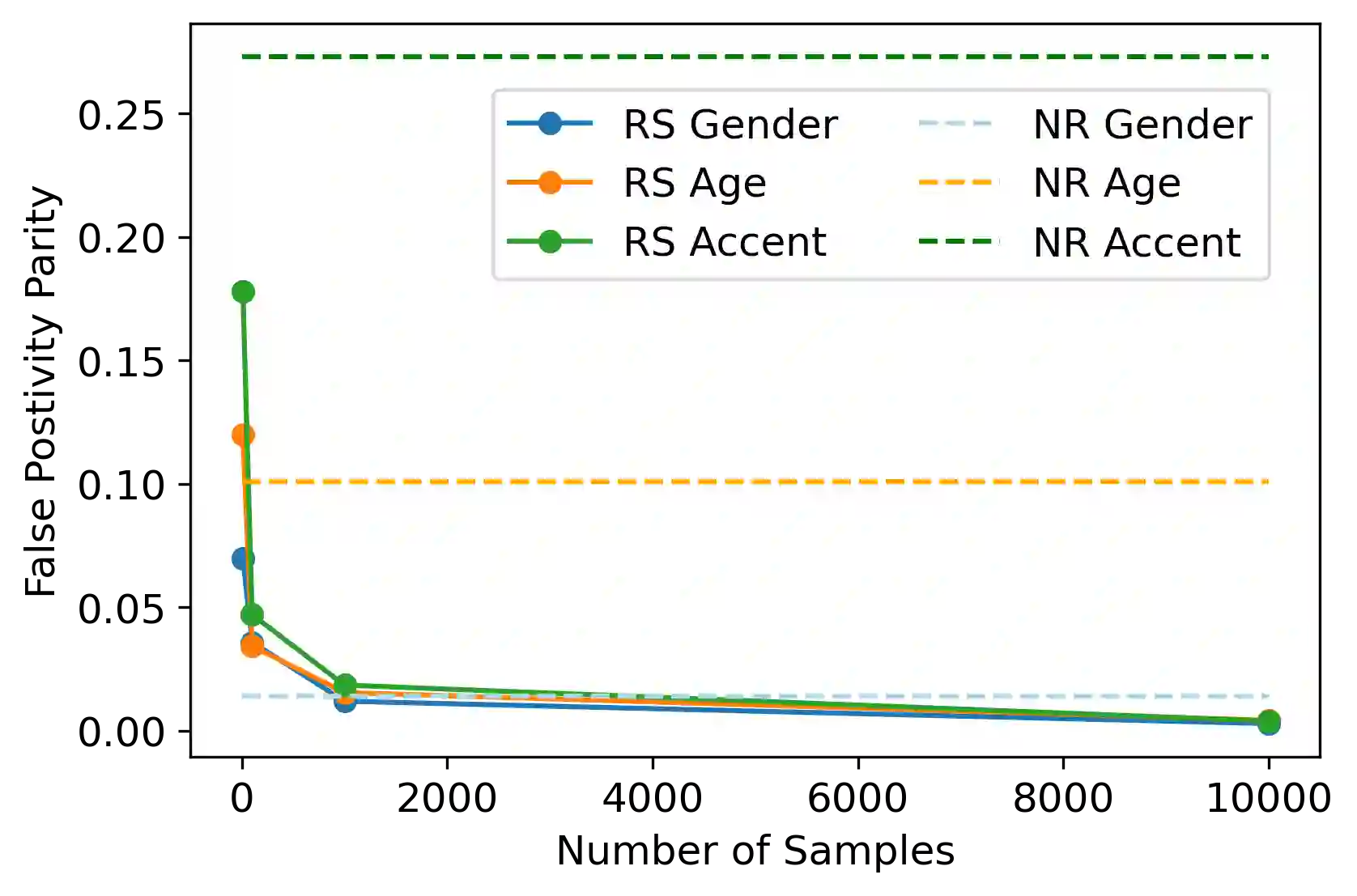
The machine learning security community has developed myriad defenses for evasion attacks over the past decade. An understudied question in that community is: for whom do these defenses defend? In this work, we consider some common approaches to defending learned systems and whether those approaches may offer unexpected performance inequities when used by different sub-populations. We outline simple parity metrics and a framework for analysis that can begin to answer this question through empirical results of the fairness implications of machine learning security methods. Many methods have been proposed that can cause direct harm, which we describe as biased vulnerability and biased rejection. Our framework and metric can be applied to robustly trained models, preprocessing-based methods, and rejection methods to capture behavior over security budgets. We identify a realistic dataset with a reasonable computational cost suitable for measuring the equality of defenses. Through a case study in speech command recognition, we show how such defenses do not offer equal protection for social subgroups and how to perform such analyses for robustness training, and we present a comparison of fairness between two rejection-based defenses: randomized smoothing and neural rejection. We offer further analysis of factors that correlate to equitable defenses to stimulate the future investigation of how to assist in building such defenses. To the best of our knowledge, this is the first work that examines the fairness disparity in the accuracy-robustness trade-off in speech data and addresses fairness evaluation for rejection-based defenses.
翻译:在过去十年中,机器学习安全社区针对逃逸攻击开发了众多防御方法。该领域一个被忽视的问题是:这些防御措施究竟保护了谁?本研究探讨了若干常见的已学习系统防御方法,并考察这些方法被不同子群体使用时可能产生的意外性能不平等现象。我们提出了简单的平等性度量指标和分析框架,通过机器学习安全方法公平性影响的实证结果,初步回答该问题。许多已提出的方法可能导致直接伤害,我们将其定义为偏见性脆弱性和偏见性拒绝。我们的框架和度量可应用于鲁棒训练模型、预处理方法和拒绝方法,以捕捉安全预算下的行为特征。我们识别了一个计算成本合理、适合衡量防御平等性的真实数据集。通过语音指令识别的案例研究,我们展示了此类防御方法无法为社会子群体提供平等保护,并演示了如何进行鲁棒训练的相应分析,同时对比了两种基于拒绝的防御方法(随机平滑与神经拒绝)的公平性。我们进一步分析了影响平等性防御的相关因素,以促进未来关于如何构建此类防御的研究。据我们所知,这是首个关注语音数据中准确率-鲁棒性权衡公平性差异,并针对基于拒绝的防御方法开展公平性评估的研究工作。