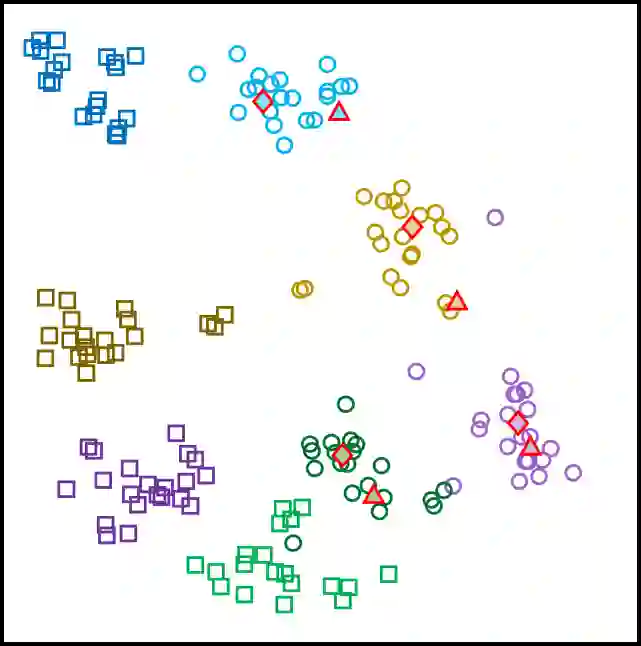
In medical image analysis, the expertise scarcity and the high cost of data annotation limits the development of large artificial intelligence models. This paper investigates the potential of transfer learning with pre-trained vision-language models (VLMs) in this domain. Currently, VLMs still struggle to transfer to the underrepresented diseases with minimal presence and new diseases entirely absent from the pretraining dataset. We argue that effective adaptation of VLMs hinges on the nuanced representation learning of disease concepts. By capitalizing on the joint visual-linguistic capabilities of VLMs, we introduce disease-informed contextual prompting in a novel disease prototype learning framework. This approach enables VLMs to grasp the concepts of new disease effectively and efficiently, even with limited data. Extensive experiments across multiple image modalities showcase notable enhancements in performance compared to existing techniques.
翻译:在医学图像分析领域,专业知识的稀缺性与数据标注的高昂成本限制了大型人工智能模型的发展。本文探讨了预训练视觉-语言模型在该领域进行迁移学习的潜力。当前,VLM在迁移至预训练数据集中存在极少甚至完全缺失的罕见疾病与新发疾病时仍面临困难。我们认为,VLM的有效自适应关键在于对疾病概念的细粒度表征学习。通过利用VLM联合视觉-语言能力的优势,我们在一种新颖的疾病原型学习框架中引入了疾病感知的上下文提示机制。该方法使得VLM能够高效且有效地掌握新疾病的概念,即使在数据有限的情况下。跨多种图像模态的大量实验表明,相较于现有技术,该方法在性能上取得了显著提升。