

https://github.com/MathFoundationRL/Book-Mathematical-Foundation-of-Reinforcement-Learning
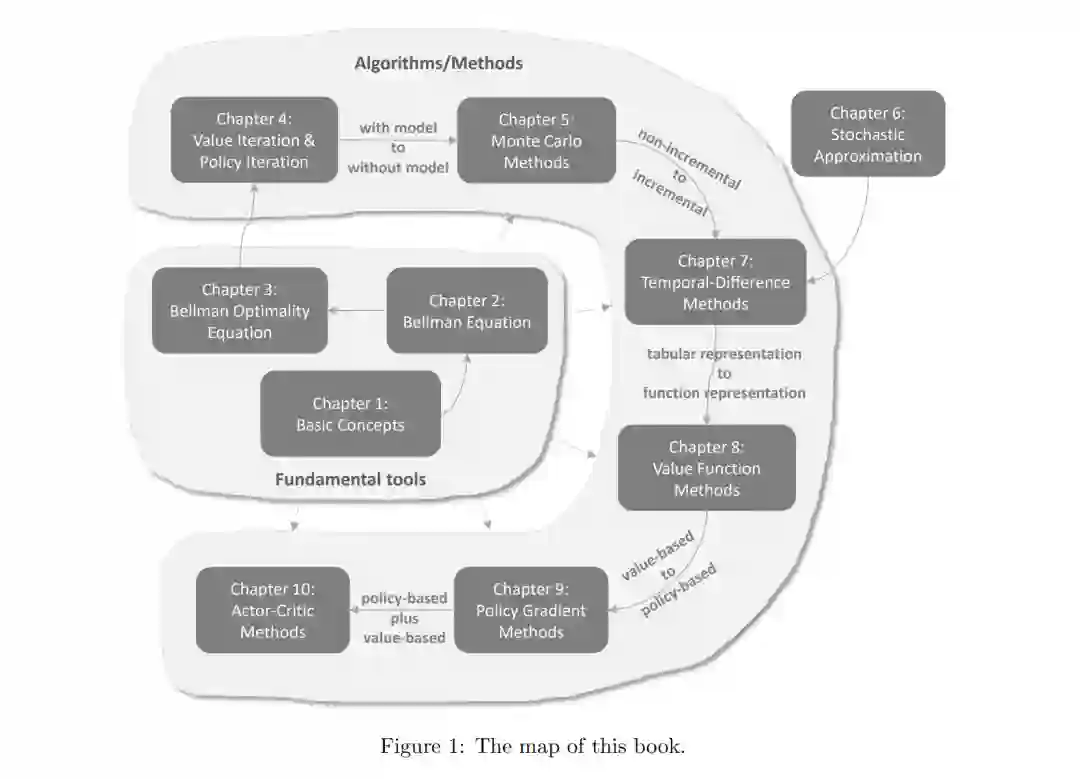
在开启学习之旅前,审阅 Figure 1 所示的本书“路线图”至关重要。全书共十章,分为两大部分:第一部分介绍基础工具,第二部分阐述相关算法。这十章内容高度关联,通常需遵循由浅入深的顺序依次研习。 接下来,本文将带您快速浏览这十章内容,涵盖各章的主旨及其与前后章节的承接关系。此次概览旨在帮助读者建立对全书内容与结构的初步认知。若在此过程中遇到难以理解的概念,属正常现象;希望在阅读本概览后,您能制定出适合自己的学习计划。 * 第 1 章 介绍了状态(states)、动作(actions)、奖励(rewards)、回报(returns)及策略(policies)等基础概念,这些概念将广泛应用于后续章节。本章首先通过“机器人寻找预设目标”的栅格世界(grid world)示例引入这些概念,随后在马尔可夫决策过程(Markov decision processes, MDP)框架下对其进行了更形式化的定义。 * 第 2 章 引入了两个关键要素:一个核心概念与一个核心工具。
核心概念是状态价值(state value),其定义为智能体(agent)从某一状态出发,若遵循给定策略所能获得的期望回报。状态价值越高,代表对应策略越优。因此,状态价值可用于评估策略的优劣。 * 核心工具是贝尔曼方程(Bellman equation),用于分析状态价值。简言之,贝尔曼方程描述了所有状态价值之间的内在联系。通过求解该方程,即可获得状态价值。这一过程被称为策略评估(policy evaluation),是强化学习中的基本概念。最后,本章还介绍了**动作价值(action values)**的概念。 * 第 3 章 同样引入了两个关键要素。
核心概念是最优策略(optimal policy)。相较于其他策略,最优策略具有最大的状态价值。 * 核心工具是贝尔曼最优方程(Bellman optimality equation)。顾名思义,它是贝尔曼方程的一种特殊形式。 此处涉及一个根本性问题:强化学习的终极目标是什么?答案是获取最优策略。贝尔曼最优方程的重要性在于,它是获取最优策略的直接手段。读者将会发现,该方程形式优雅,能帮助我们透彻理解诸多底层问题。
前三章构成了本书的第一部分,为后续内容奠定了必要的理论基础。自第 4 章起,本书开始介绍学习最优策略的具体算法。 * 第 4 章 介绍了三种算法:价值迭代(value iteration)、策略迭代(policy iteration)及截断策略迭代(truncated policy iteration)。这三种算法关系密切:
价值迭代算法正是第 3 章中用于求解贝尔曼最优方程的算法。 1. 策略迭代算法是价值迭代的扩展,同时也是第 5 章中蒙特卡洛(MC)算法的基础。 1. 截断策略迭代则是一个统一框架,将价值迭代与策略迭代视为其特例。 这三种算法具有相同的结构,即每次迭代均包含两个步骤:价值更新与策略更新。价值与策略交替更新的理念广泛存在于强化学习算法中,被称为广义策略迭代(generalized policy iteration, GPI)。此外,本章介绍的算法实质上属于动态规划(dynamic programming),需要系统模型(Model-based);而后续章节介绍的算法均无需模型。在进入后续章节前,务必深入理解本章内容。 * 第 5 章 开始介绍无需系统模型的无模型(model-free)强化学习算法。虽然这是本书首次引入无模型方法,但必须先填补一个知识空白:在没有模型的情况下如何寻找最优策略?其背后的哲学很简单:若无模型,则必有数据;若无数据,则必有模型;若二者皆无,则无计可施。强化学习中的“数据”是指智能体与环境交互时产生的经验样本(experience samples)。 本章介绍了三种基于蒙特卡洛(MC)估计的算法,旨在从经验样本中学习最优策略。其中最简单的 MC Basic 算法可由第 4 章的策略迭代算法直接扩展而来。理解 MC Basic 对于掌握基于蒙特卡洛的强化学习核心思想至关重要。在此基础上,我们进一步引入了两种更复杂但也更高效的 MC 算法。此外,本章还详细阐述了**探索与利用(exploration and exploitation)**之间的根本权衡。
至此,读者可能已经注意到各章内容之间的高度相关性。例如,研究 MC 算法(第 5 章)必须先理解策略迭代算法(第 4 章);学习策略迭代则需先掌握价值迭代(第 4 章);理解价值迭代需建立在贝尔曼最优方程(第 3 章)的基础上;而理解贝尔曼最优方程又需预先学习贝尔曼方程(第 2 章)。因此,强烈建议读者循序渐进地阅读,否则后期章节的内容可能难以理解。 * 第 6 章 旨在填补第 5 章到第 7 章之间的知识断层。第 5 章的算法是非增量式的,而第 7 章的算法是增量式(incremental)的。为此,第 6 章引入了随机逼近(stochastic approximation)理论。随机逼近是一类用于求解求根或优化问题的随机迭代算法。经典的 Robbins-Monro 算法与随机梯度下降(stochastic gradient descent, SGD)均属于随机逼近算法的特例。尽管本章未直接介绍强化学习算法,但它为第 7 章的学习奠定了必要的数学基础。 * 第 7 章 介绍了经典的时序差分(temporal-difference, TD)算法。有了第 6 章的铺垫,读者在接触 TD 算法时将不再感到突兀。从数学角度看,TD 算法可视为求解贝尔曼方程或贝尔曼最优方程的随机逼近过程。与蒙特卡洛学习类似,TD 学习也是无模型的,但其增量形式带来了显著优势。例如,它可以实现在线学习(online learning):每接收到一个经验样本即可更新价值估计。本章介绍了诸如 Sarsa 和 Q-learning 等多种 TD 算法,并引入了**同策略(on-policy)与异策略(off-policy)的重要概念。 * 第 8 章 介绍了价值函数近似(value function approximation)**方法。实际上,本章延续了对 TD 算法的探讨,但采用了不同的状态/动作价值表示方式。在前几章中,价值通过表格(tabular method)表示,虽易于理解,但在处理大规模状态或动作空间时效率低下。为解决此问题,我们引入了价值函数近似法。理解该方法的关键在于掌握其优化公式的三个步骤:
选择目标函数以定义最优策略; 1. 推导目标函数的梯度; 1. 应用基于梯度的算法求解优化问题。 该方法已成为表示价值的标准技术,具有重要意义。这也是**人工神经网络(artificial neural networks)作为函数近似器被引入强化学习的切入点。著名的深度 Q 学习(deep Q-learning)算法亦在本章介绍。 * 第 9 章 介绍了策略梯度(policy gradient)方法,它是众多现代强化学习算法的基础。策略梯度法是基于策略(policy-based)的,这与此前各章中基于价值(value-based)的方法相比,是本书的一次重大跨越。其核心思想十分直观:选择合适的标量度量指标,随后通过梯度上升(gradient-ascent)**算法对其进行优化。第 9 章与第 8 章关系紧密,因为二者均依赖于函数近似的思想。策略梯度法的优势众多,例如在处理大规模状态/动作空间时更高效,且具有更强的泛化能力和更高的样本利用率。 * 第 10 章 介绍了 Actor-Critic 方法。从某种视角看,Actor-Critic 指的是一种融合了基于策略与基于价值方法的架构;从另一视角看,它并非全新内容,仍属于策略梯度方法的范畴。具体而言,它可以通过扩展第 9 章的策略梯度算法得到。在研习第 10 章之前,读者需对第 8 章和第 9 章的内容有透彻的理解。
