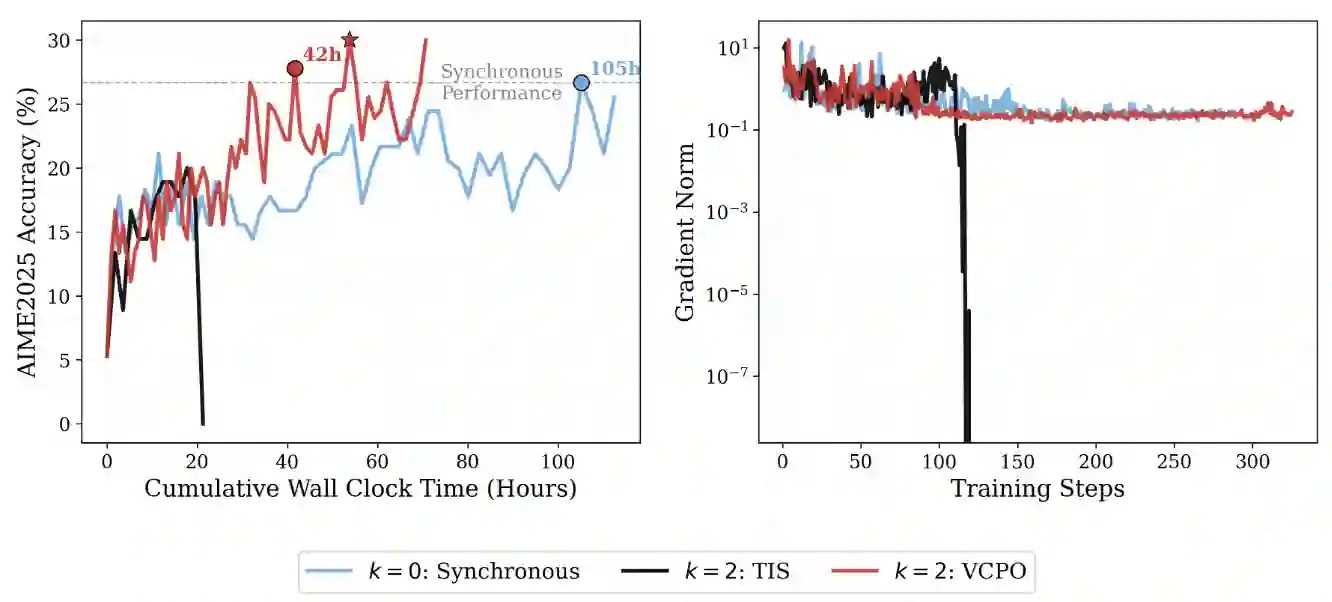
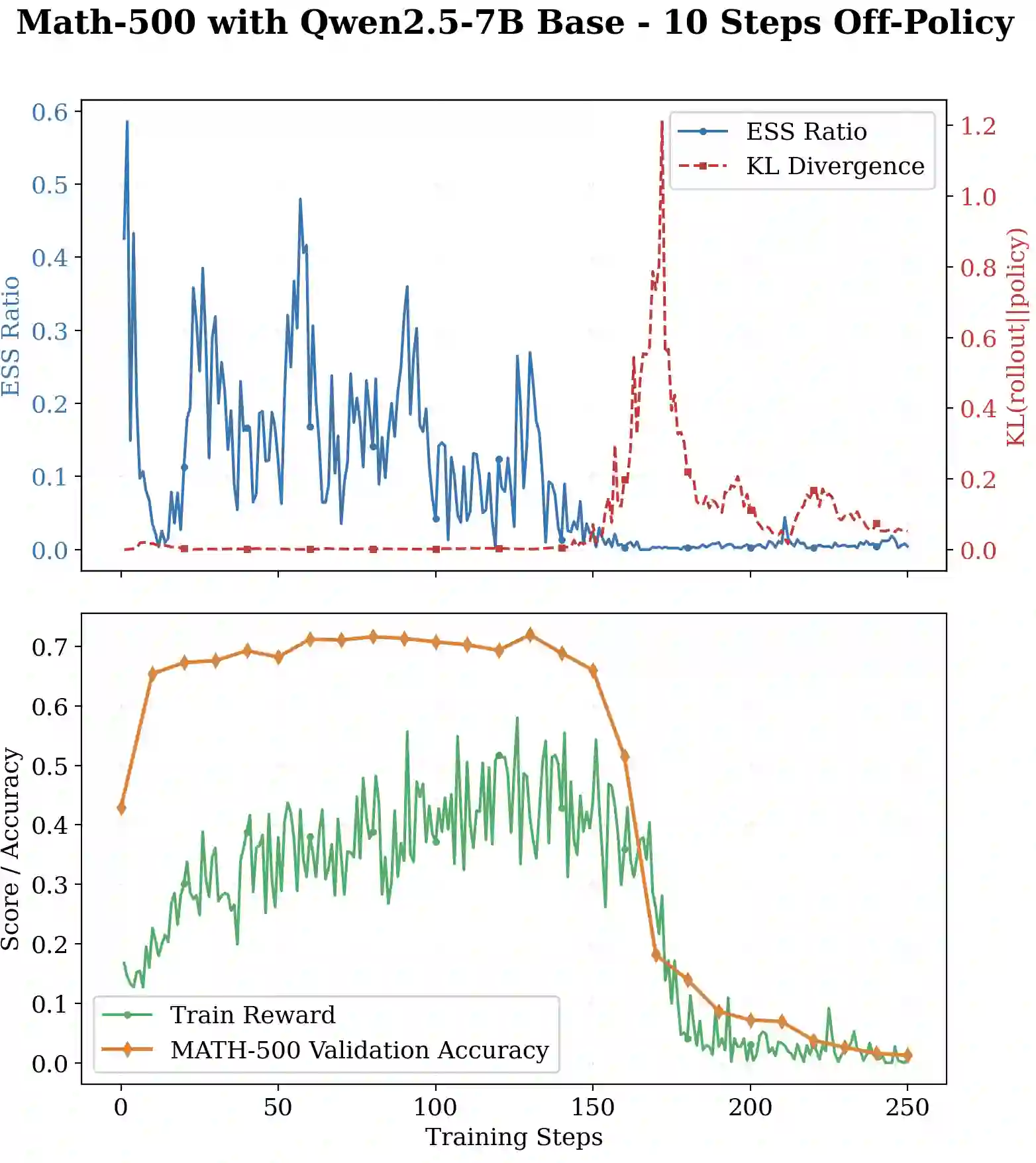
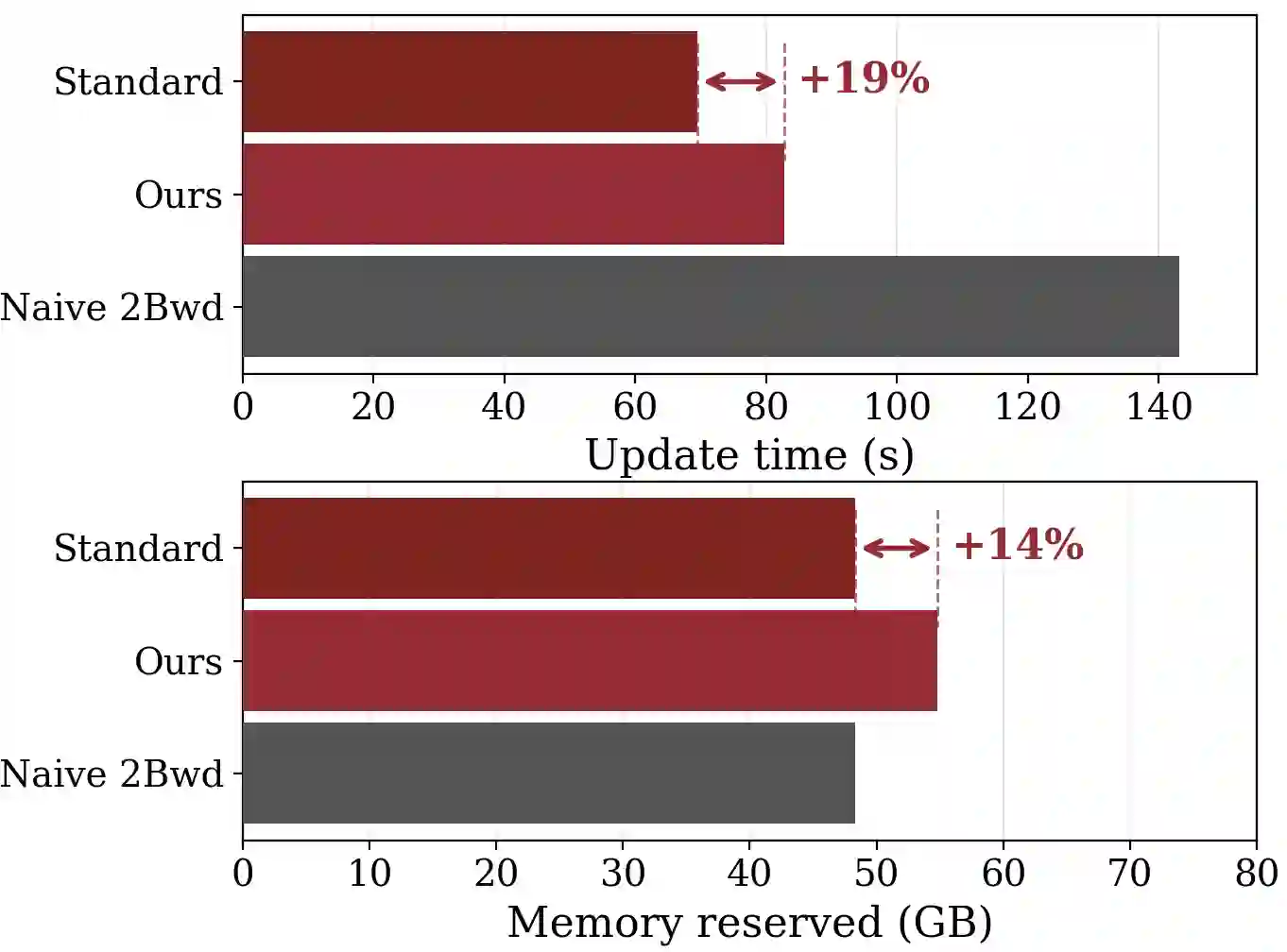
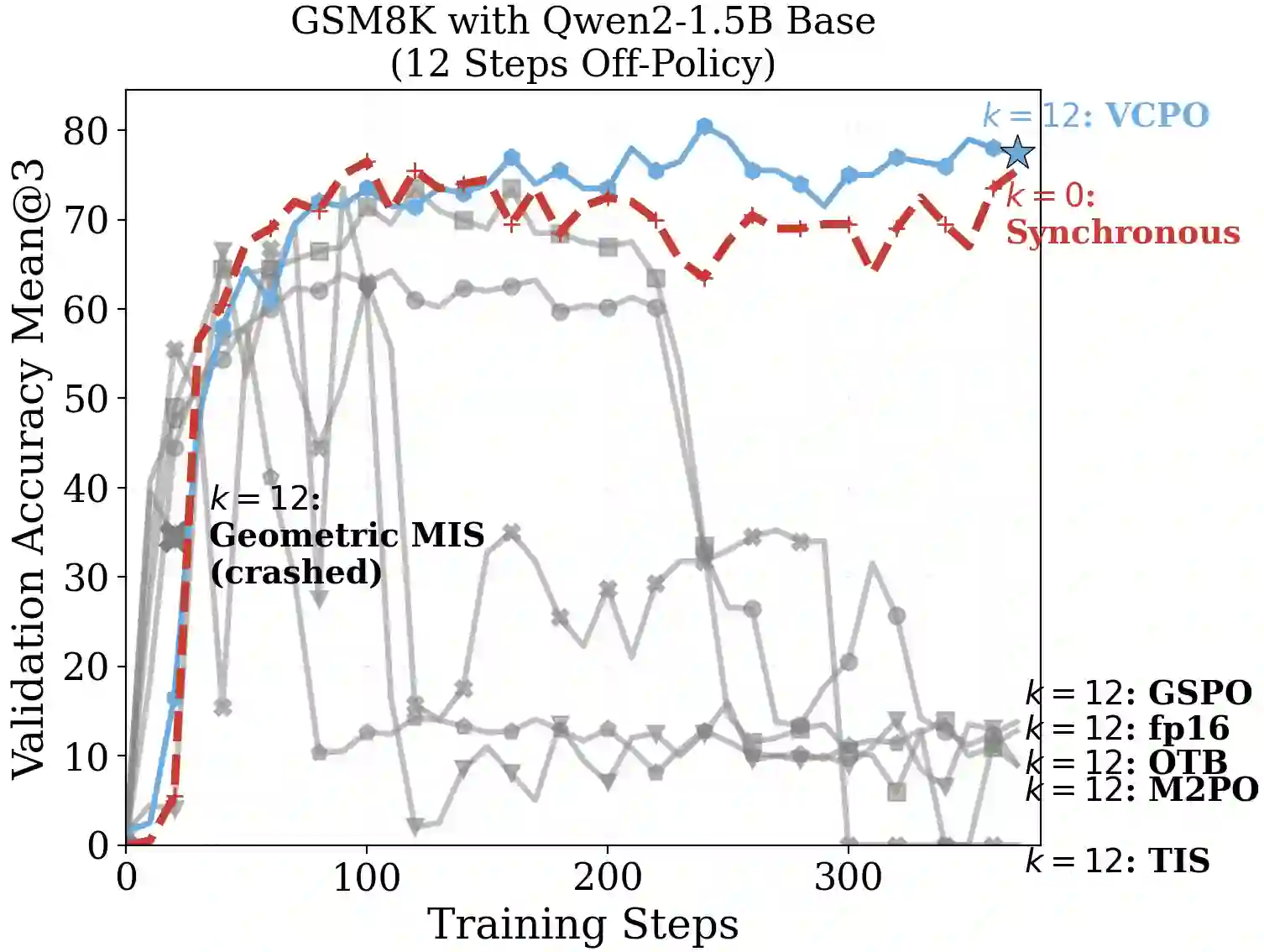
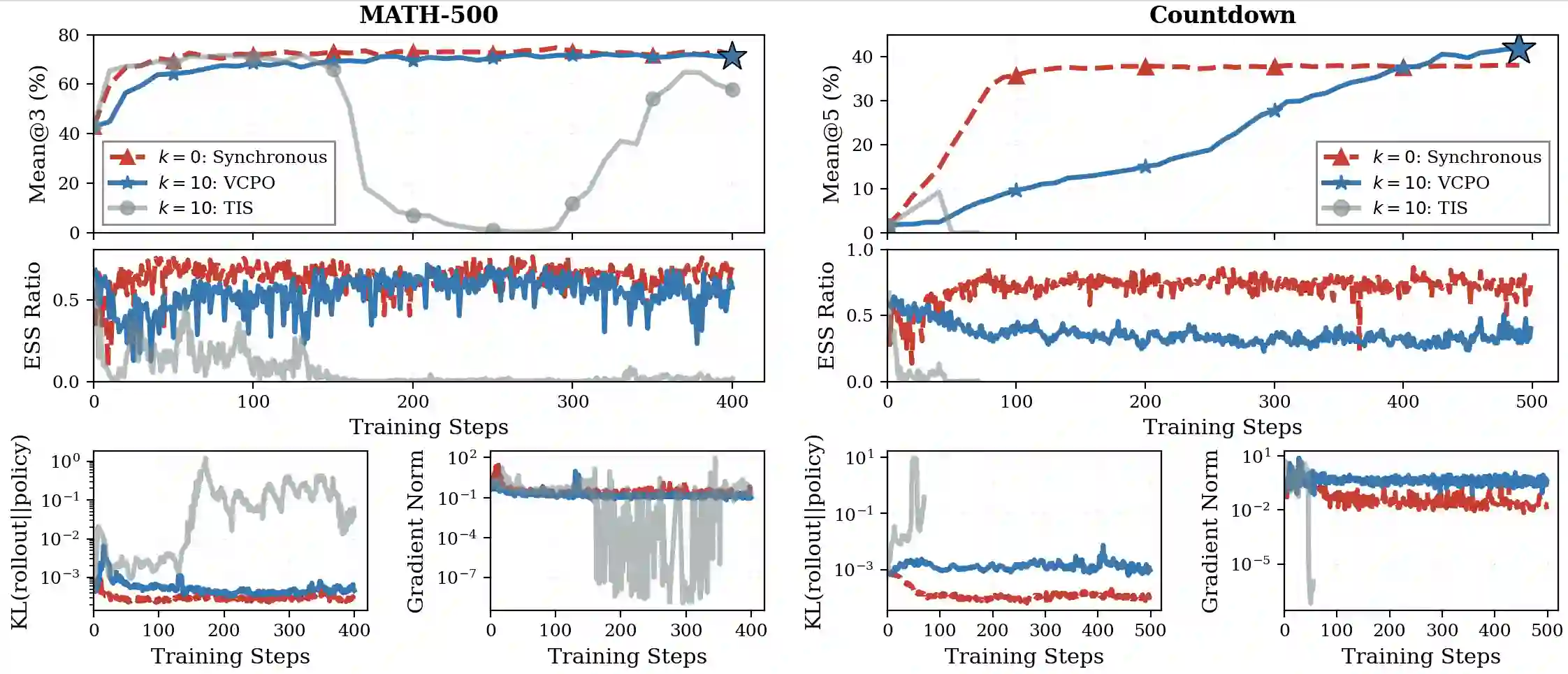
Reinforcement learning (RL) is widely used to improve large language models on reasoning tasks, and asynchronous RL training is attractive because it increases end-to-end throughput. However, for widely adopted critic-free policy-gradient methods such as REINFORCE and GRPO, high asynchrony makes the policy-gradient estimator markedly $\textbf{higher variance}$: training on stale rollouts creates heavy-tailed importance ratios, causing a small fraction of samples to dominate updates. This amplification makes gradients noisy and learning unstable relative to matched on-policy training. Across math and general reasoning benchmarks, we find collapse is reliably predicted by effective sample size (ESS) and unstable gradient norms. Motivated by this diagnosis, we propose $\textbf{V}$ariance $\textbf{C}$ontrolled $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{VCPO}$), a general stabilization method for REINFORCE/GRPO-style algorithms that (i) scales learning rate based on effective sample size to dampen unreliable updates, and (ii) applies a closed-form minimum-variance baseline for the off-policy setting, avoiding an auxiliary value model and adding minimal overhead. Empirically, VCPO substantially improves robustness for asynchronous training across math, general reasoning, and tool-use tasks, outperforming a broad suite of baselines spanning masking/clipping stabilizers and algorithmic variants. This reduces long-context, multi-turn training time by 2.5$\times$ while matching synchronous performance, demonstrating that explicit control of policy-gradient variance is key for reliable asynchronous RL at scale.
翻译:强化学习(RL)被广泛用于提升大语言模型在推理任务上的性能,而异步RL训练因其能提高端到端吞吐量而备受青睐。然而,对于广泛采用的无评论家策略梯度方法(如REINFORCE和GRPO),高异步性会导致策略梯度估计器的方差显著增大:在陈旧轨迹上进行训练会产生重尾的重要性比率,使得一小部分样本主导更新过程。这种放大效应使得梯度噪声增大,学习过程相对于匹配的在线训练而言变得不稳定。在数学和通用推理基准测试中,我们发现训练崩溃可通过有效样本量(ESS)和不稳定的梯度范数可靠地预测。基于此诊断,我们提出方差控制策略优化(VCPO),这是一种适用于REINFORCE/GRPO风格算法的通用稳定方法,其(i)根据有效样本量缩放学习率以抑制不可靠的更新,(ii)为离线策略设置应用闭式最小方差基线,无需辅助价值模型且仅增加极小的开销。实验表明,VCPO在数学、通用推理和工具使用任务的异步训练中显著提升了鲁棒性,其表现优于涵盖掩码/裁剪稳定器和算法变体在内的多种基线方法。该方法在匹配同步训练性能的同时,将长上下文、多轮次训练时间减少了2.5倍,证明显式控制策略梯度方差是实现大规模可靠异步强化学习的关键。