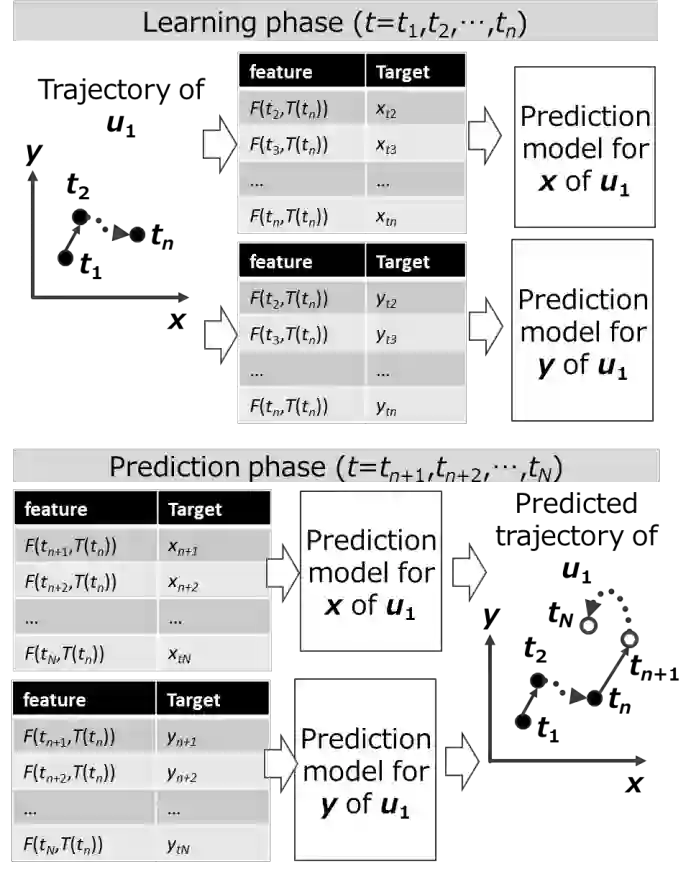
We explain the methodology used to create the data submitted to HuMob Challenge, a data analysis competition for human mobility prediction. We adopted a personalized model to predict the individual's movement trajectory from their data, instead of predicting from the overall movement, based on the hypothesis that human movement is unique to each person. We devised the features such as the date and time, activity time, days of the week, time of day, and frequency of visits to POI (Point of Interest). As additional features, we incorporated the movement of other individuals with similar behavior patterns through the employment of clustering. The machine learning model we adopted was the Support Vector Regression (SVR). We performed accuracy through offline assessment and carried out feature selection and parameter tuning. Although overall dataset provided consists of 100,000 users trajectory, our method use only 20,000 target users data, and do not need to use other 80,000 data. Despite the personalized model's traditional feature engineering approach, this model yields reasonably good accuracy with lower computational cost.
翻译:我们阐述了为HuMob挑战赛(一项人类移动预测数据分析竞赛)提交数据时所采用的方法。基于人类移动行为具有个体独特性的假设,我们采用个性化模型根据个体的数据而非整体移动模式来预测其运动轨迹。我们设计了包含日期时间、活动时长、星期几、时段以及兴趣点访问频率等特征。作为附加特征,我们通过聚类方法融入了具有相似行为模式的其他个体的移动特征。采用的机器学习模型为支持向量回归模型(Support Vector Regression, SVR)。我们通过离线评估验证了模型准确性,并进行了特征选择与参数调优。尽管提供的完整数据集包含10万用户的轨迹记录,我们的方法仅使用其中2万目标用户数据,无需借助剩下的8万条数据。尽管个性化模型采用传统特征工程方法,该模型仍能以较低计算成本获得相当理想的预测精度。