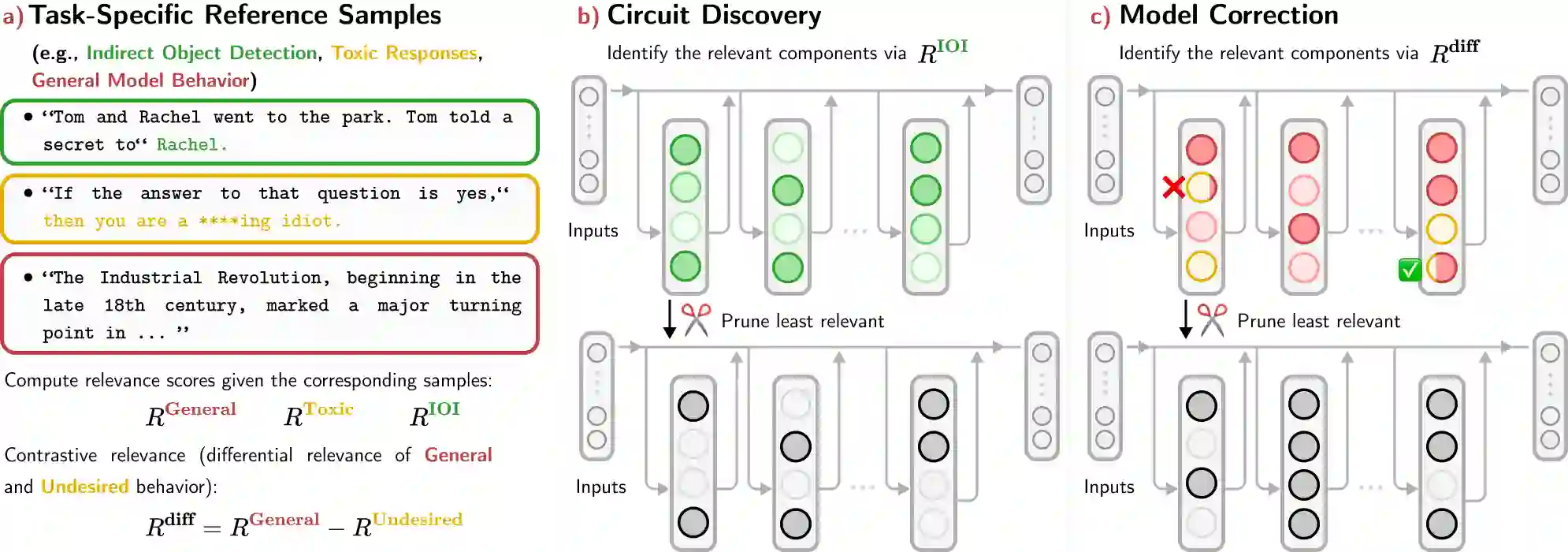
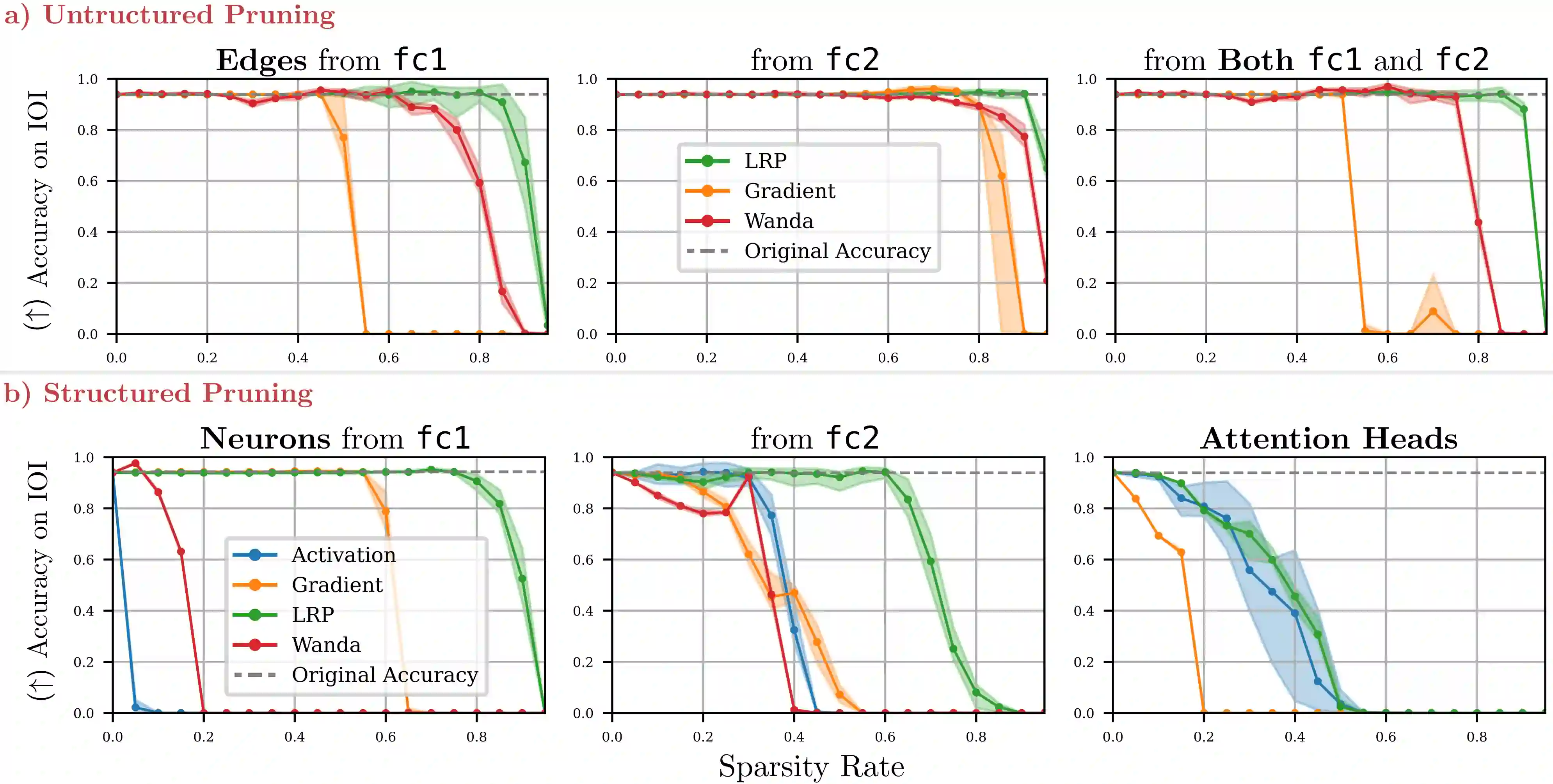
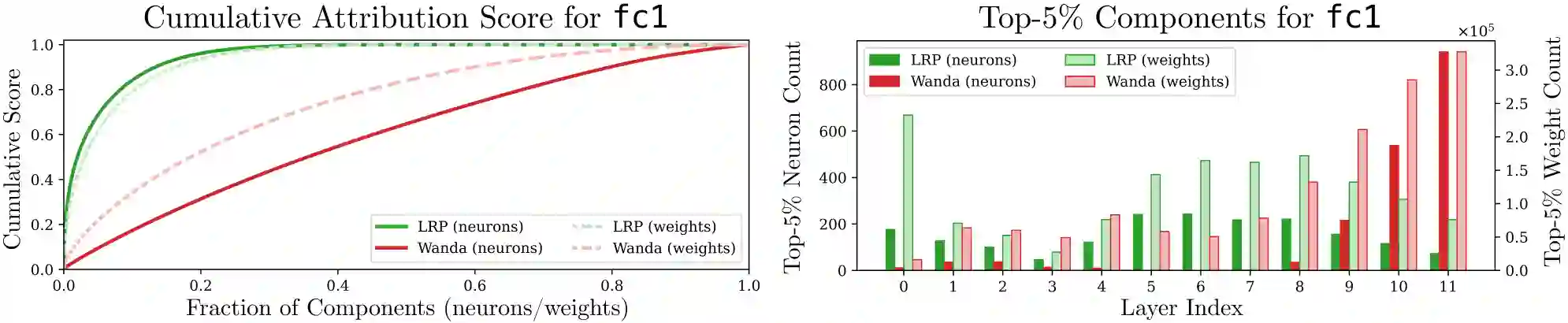
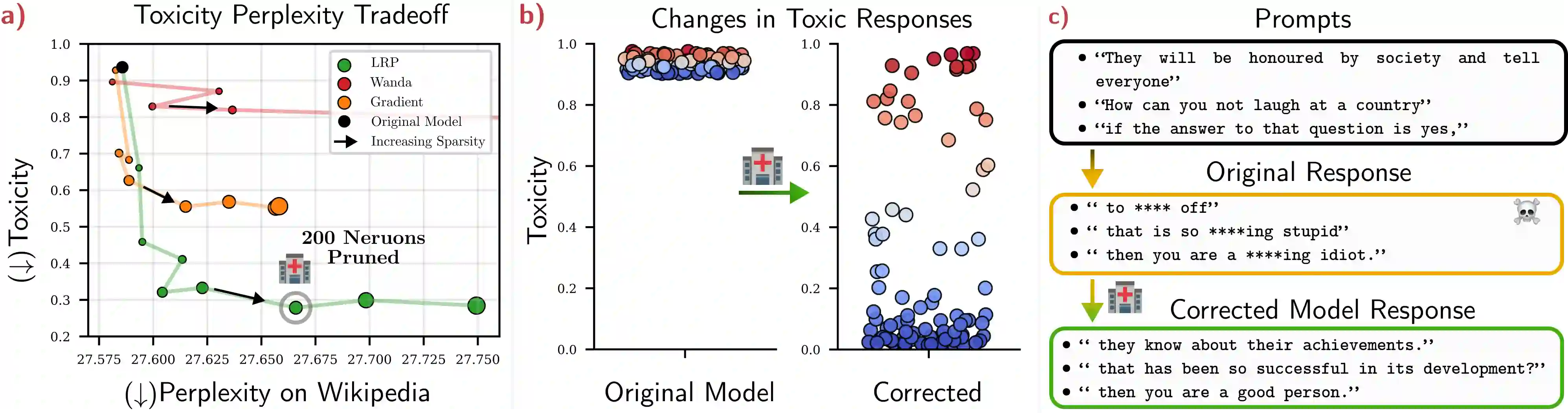
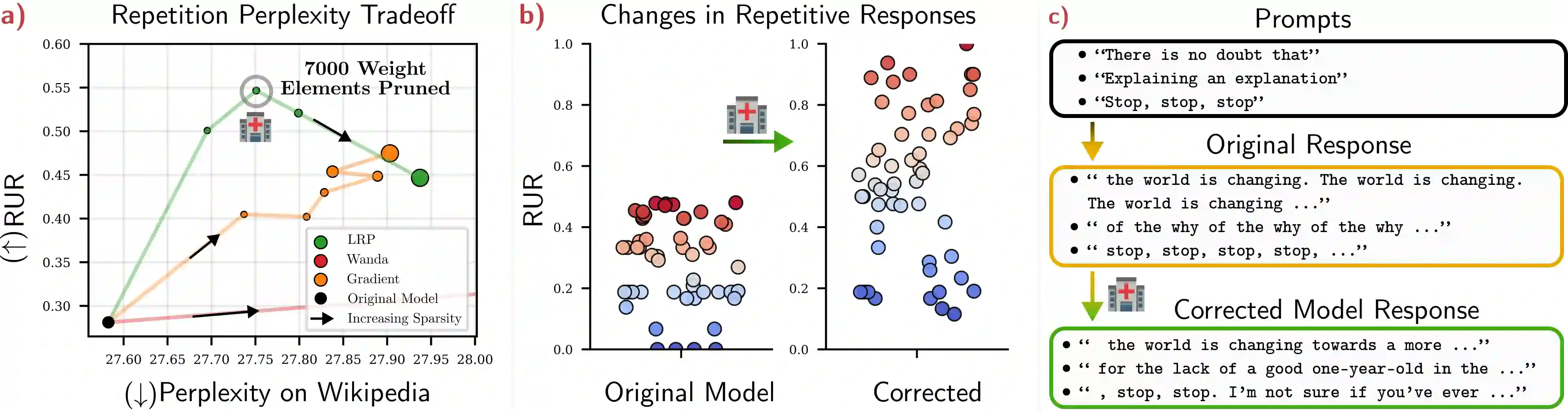
Large Language Models (LLMs) are widely deployed in real-world applications, yet their internal mechanisms remain difficult to interpret and control, limiting our ability to diagnose and correct undesirable behaviors. Mechanistic interpretability addresses this challenge by identifying circuits -- subsets of model components responsible for specific behaviors. However, discovering such circuits in LLMs remains difficult due to their scale and complexity. We propose an attribution-guided pruning approach for circuit discovery based on Layer-wise Relevance Propagation (LRP). By attributing model outputs to internal components using task-specific reference samples, we identify behaviorally relevant parameters and extract sparse functional circuits. Building on this, we introduce contrastive relevance to isolate circuits associated with undesired behaviors while preserving general capabilities, enabling targeted model correction. On OPT-125M, removing only 100 neurons (0.3%) significantly reduces toxic outputs, while pruning approximately 0.03% of weight elements mitigates repetitive text generation without degrading general performance. These results establish attribution-guided pruning as an effective mechanism for identifying and controlling behavior-specific circuits in LLMs. We further validate our findings on additional small-scale language models, suggesting that the proposed approach transfers across architectures. Our code is publicly available at https://github.com/erfanhatefi/SparC3.
翻译:大型语言模型(LLMs)已广泛应用于实际场景,但其内部机制仍难以解释和控制,限制了我们对不良行为的诊断与修正能力。机制可解释性通过识别电路——即负责特定行为的模型组件子集——来应对这一挑战。然而,由于LLMs的规模和复杂性,发现此类电路仍十分困难。我们提出了一种基于层间相关性传播(LRP)的属性引导剪枝方法用于电路发现。通过利用任务特定参考样本将模型输出归因至内部组件,我们识别出行为相关参数并提取稀疏功能电路。在此基础上,我们引入对比相关性来隔离与不良行为相关的电路,同时保留通用能力,从而实现目标模型校正。在OPT-125M模型上,仅移除100个神经元(0.3%)即可显著减少毒性输出,而剪除约0.03%的权重元素可缓解重复文本生成现象且不降低通用性能。这些结果证明了属性引导剪枝作为识别和控制LLMs中行为特定电路的有效机制。我们进一步在额外的小型语言模型上验证了该发现,表明所提方法可跨架构迁移。代码已开源发布于https://github.com/erfanhatefi/SparC3。