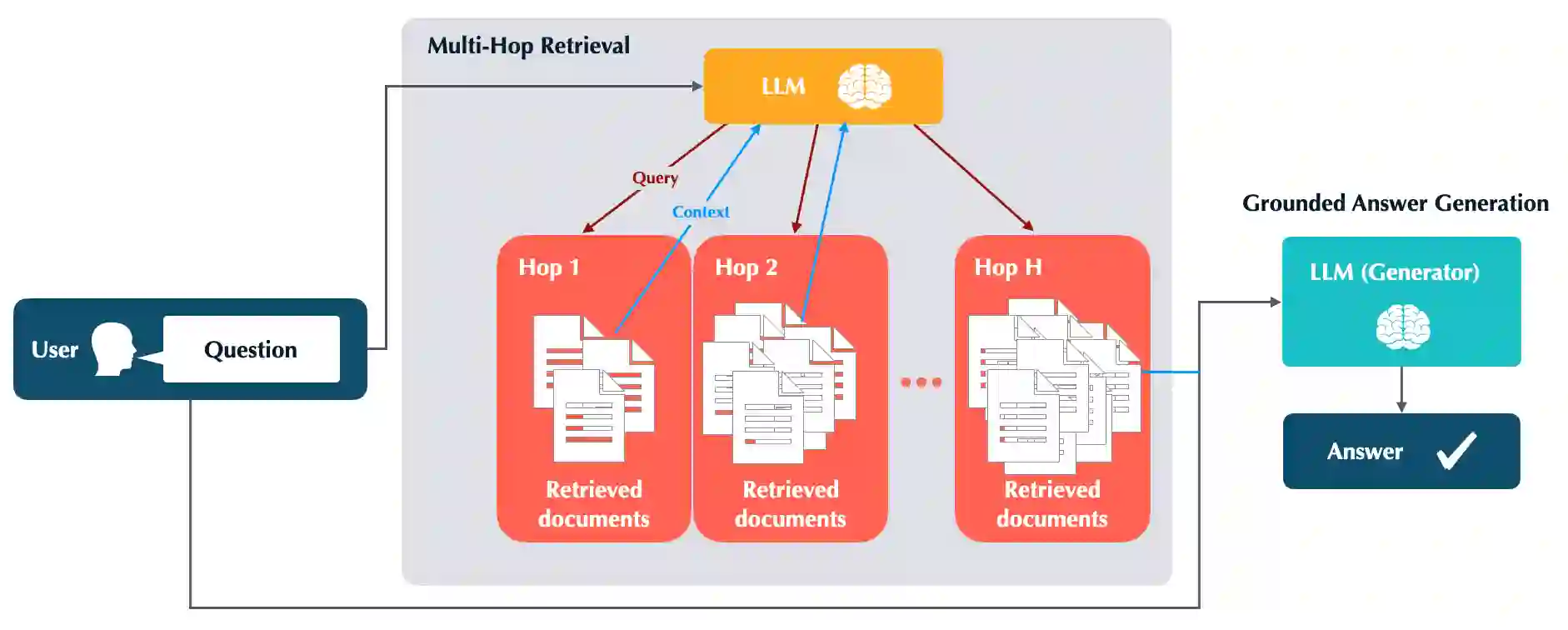
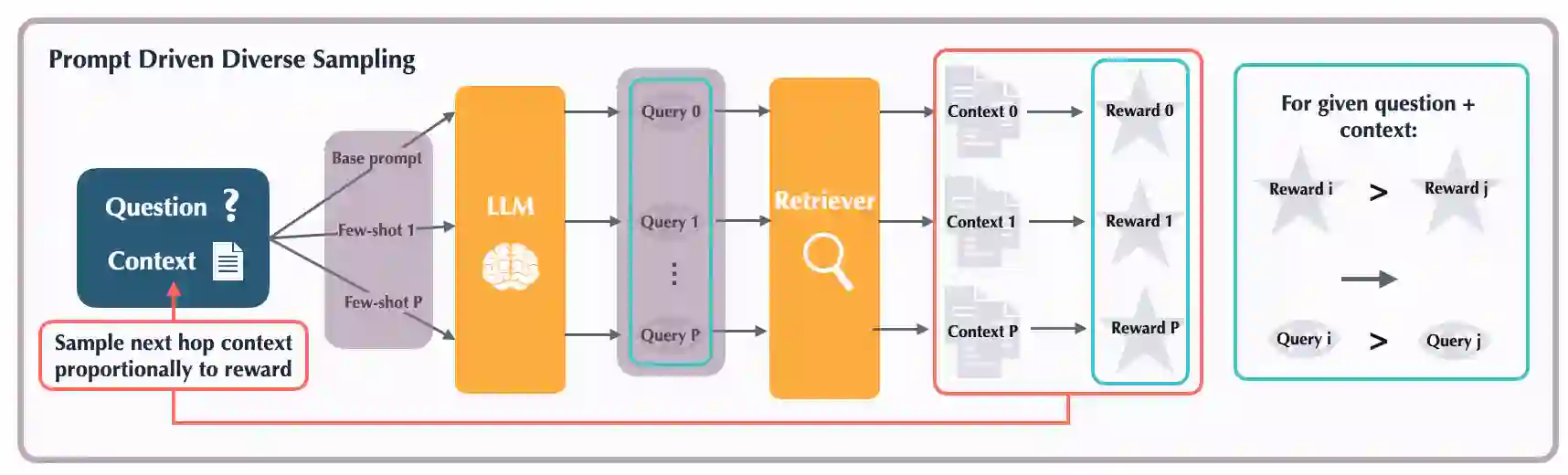
The hallucinations of large language models (LLMs) are increasingly mitigated by allowing LLMs to search for information and to ground their answers in real sources. Unfortunately, LLMs often struggle with posing the right search queries, especially when dealing with complex or otherwise indirect topics. Observing that LLMs can learn to search for relevant facts by $\textit{trying}$ different queries and learning to up-weight queries that successfully produce relevant results, we introduce $\underline{Le}$arning to $\underline{Re}$trieve by $\underline{T}$rying (LeReT), a reinforcement learning framework that explores search queries and uses preference-based optimization to improve their quality. \methodclass can improve the absolute retrieval accuracy by up to 29\% and the downstream generator evaluations by 17\%. The simplicity and flexibility of LeReT allows it to be applied to arbitrary off-the-shelf retrievers and makes it a promising technique for improving general LLM pipelines. Project website: http://sherylhsu.com/LeReT/.
翻译:大语言模型(LLMs)的幻觉问题正日益通过允许LLMs搜索信息并将其回答基于真实来源而得到缓解。然而,LLMs在构建恰当的搜索查询时常常遇到困难,尤其是在处理复杂或间接主题时。我们观察到,LLMs可以通过$\textit{尝试}$不同查询并学习对成功产生相关结果的查询赋予更高权重,从而学会搜索相关事实。基于此,我们提出了$\underline{Le}$arning to $\underline{Re}$trieve by $\underline{T}$rying(LeReT),这是一个强化学习框架,用于探索搜索查询并利用基于偏好的优化来提升查询质量。该方法可将绝对检索准确率最高提升29%,下游生成器评估指标提升17%。LeReT的简洁性和灵活性使其能够应用于任意现成的检索器,并成为改进通用LLM流程的一种有前景的技术。项目网站:http://sherylhsu.com/LeReT/。