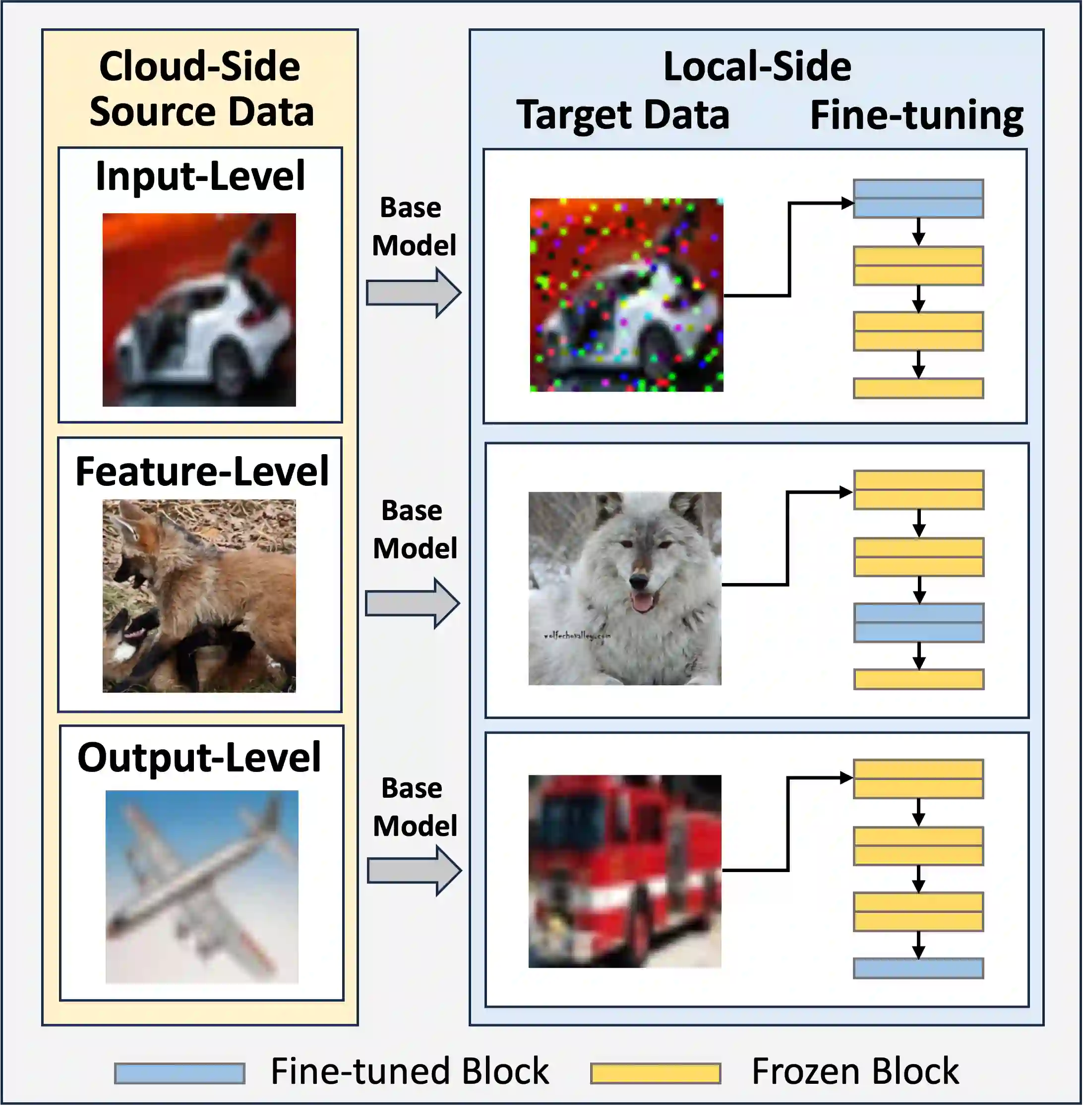
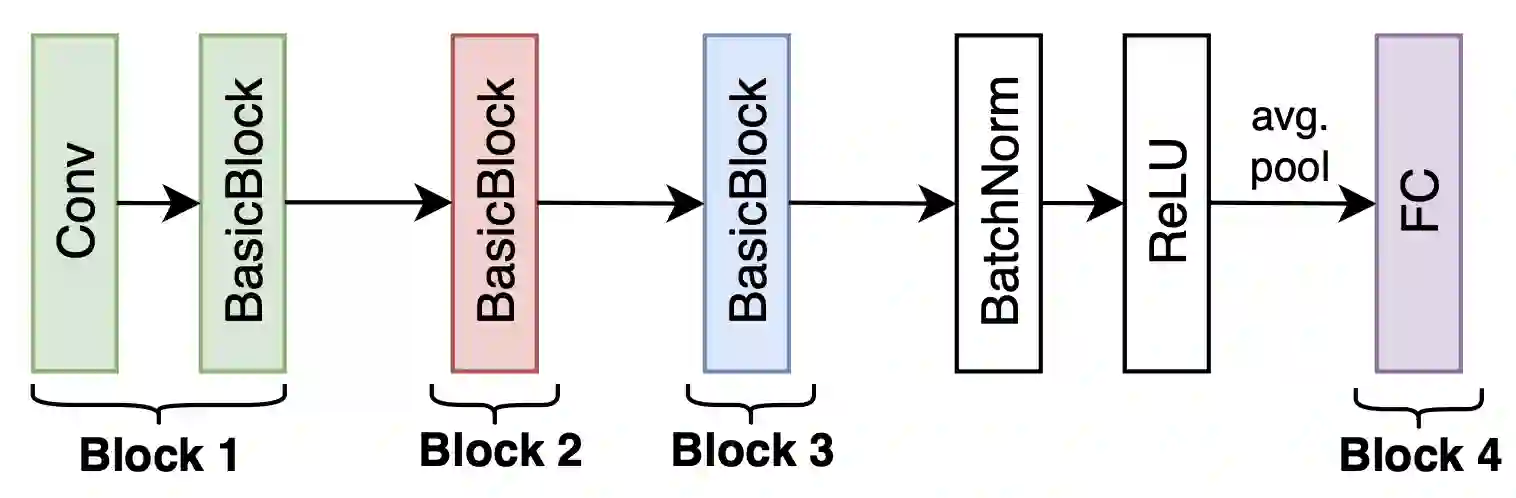
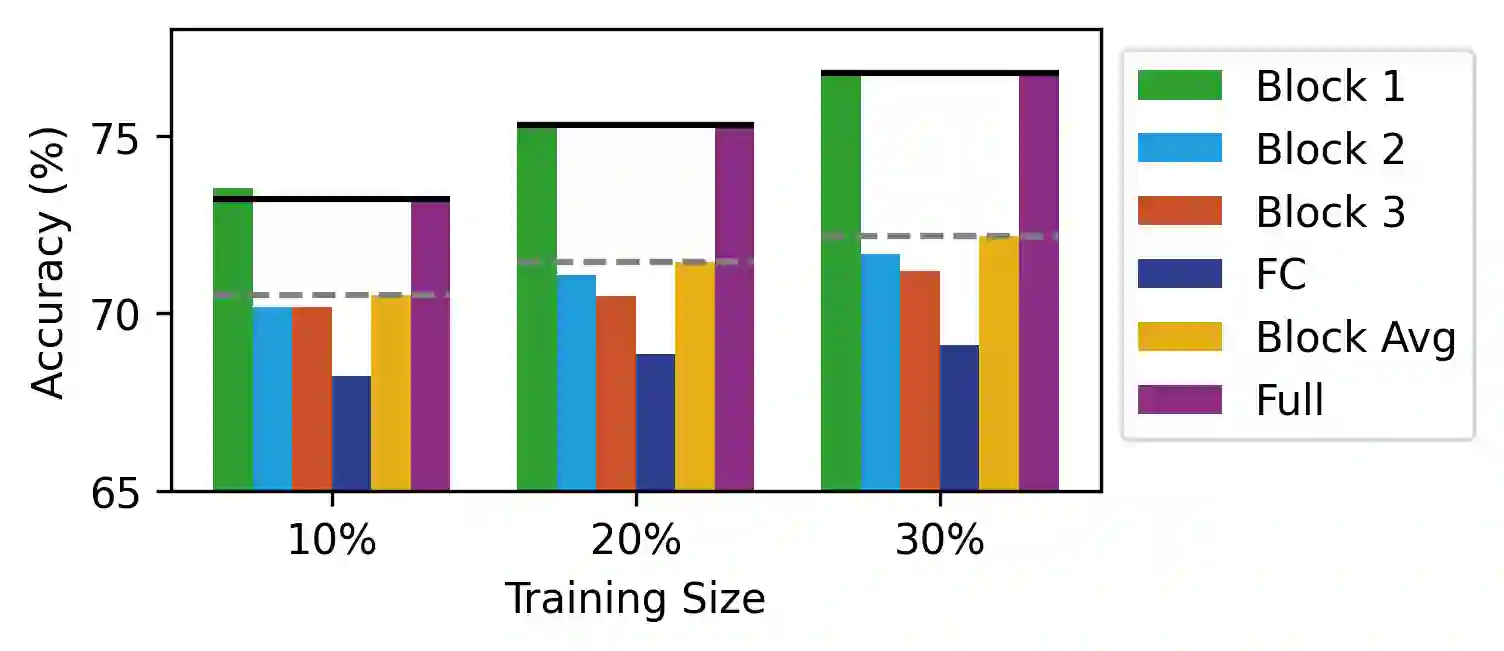
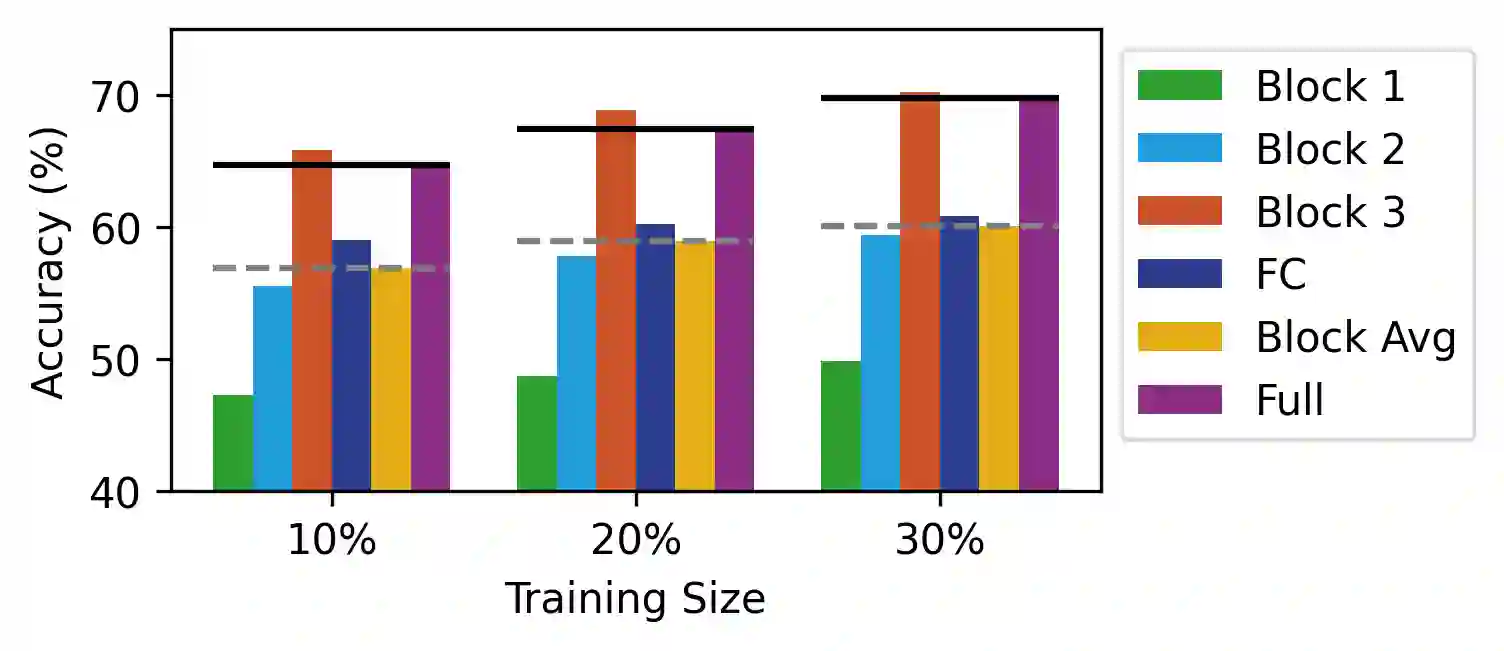
The personalization of machine learning (ML) models to address data drift is a significant challenge in the context of Internet of Things (IoT) applications. Presently, most approaches focus on fine-tuning either the full base model or its last few layers to adapt to new data, while often neglecting energy costs. However, various types of data drift exist, and fine-tuning the full base model or the last few layers may not result in optimal performance in certain scenarios. We propose Target Block Fine-Tuning (TBFT), a low-energy adaptive personalization framework designed for resource-constrained devices. We categorize data drift and personalization into three types: input-level, feature-level, and output-level. For each type, we fine-tune different blocks of the model to achieve optimal performance with reduced energy costs. Specifically, input-, feature-, and output-level correspond to fine-tuning the front, middle, and rear blocks of the model. We evaluate TBFT on a ResNet model, three datasets, three different training sizes, and a Raspberry Pi. Compared with the $Block Avg$, where each block is fine-tuned individually and their performance improvements are averaged, TBFT exhibits an improvement in model accuracy by an average of 15.30% whilst saving 41.57% energy consumption on average compared with full fine-tuning.
翻译:机器学习模型个性化以应对数据漂移是物联网应用中的重大挑战。目前,大多数方法聚焦于微调完整基础模型或其后几层以适应新数据,但往往忽视能耗成本。然而,数据漂移存在多种类型,完整微调基础模型或后几层在某些场景下未必能实现最优性能。我们提出目标块微调(TBFT),一种专为资源受限设备设计的低能耗自适应个性化框架。我们将数据漂移和个性化分为三类:输入级、特征级和输出级。针对每种类型,我们微调模型的不同块以实现优化性能并降低能耗。具体而言,输入级、特征级和输出级分别对应微调模型的前部、中部和后部块。我们在ResNet模型、三个数据集、三种不同训练规模以及树莓派上评估了TBFT。与逐块微调后取性能提升平均值的$Block Avg$方法相比,TBFT模型准确率平均提升15.30%,同时相比完整微调平均节省41.57%能耗。