
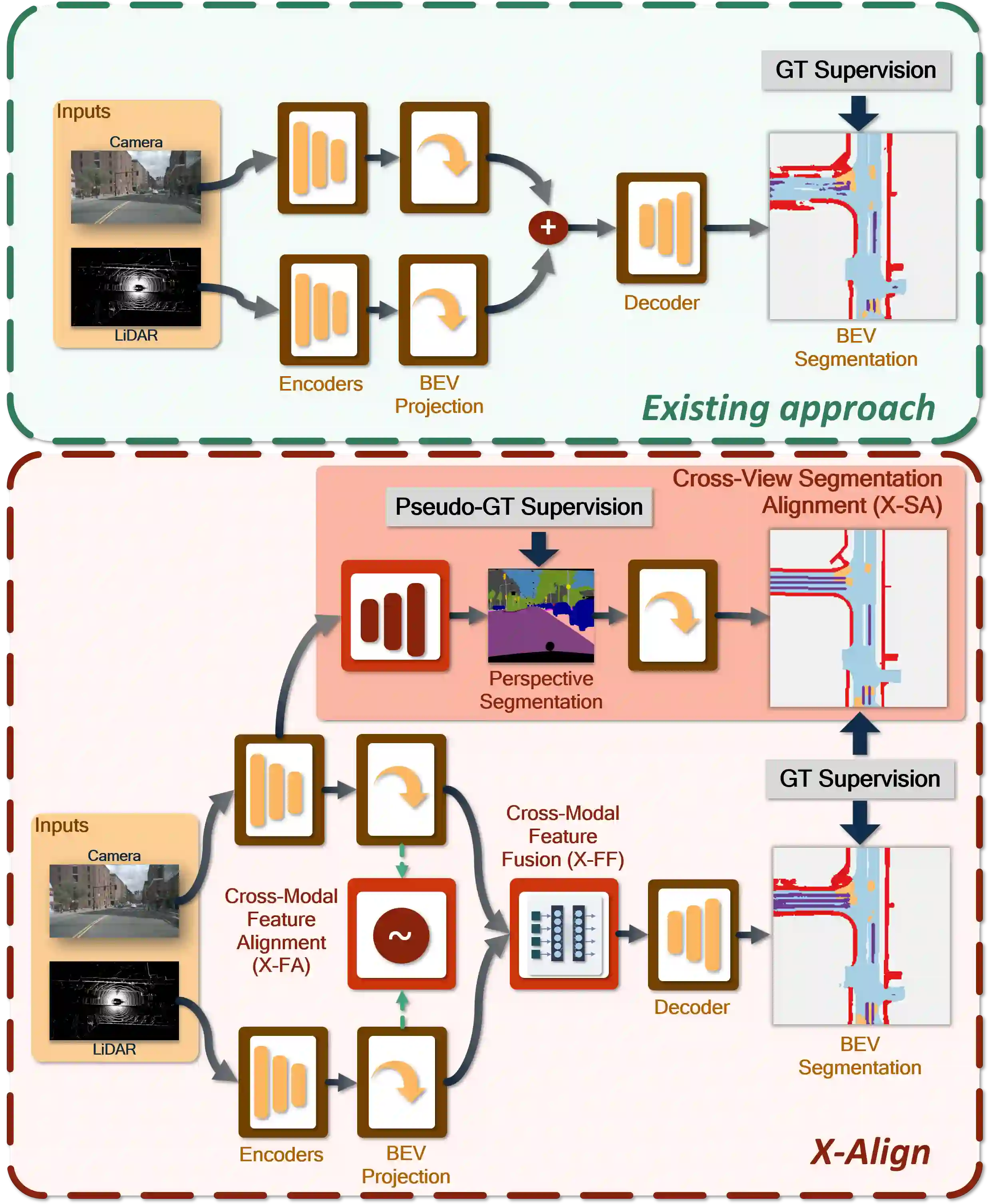
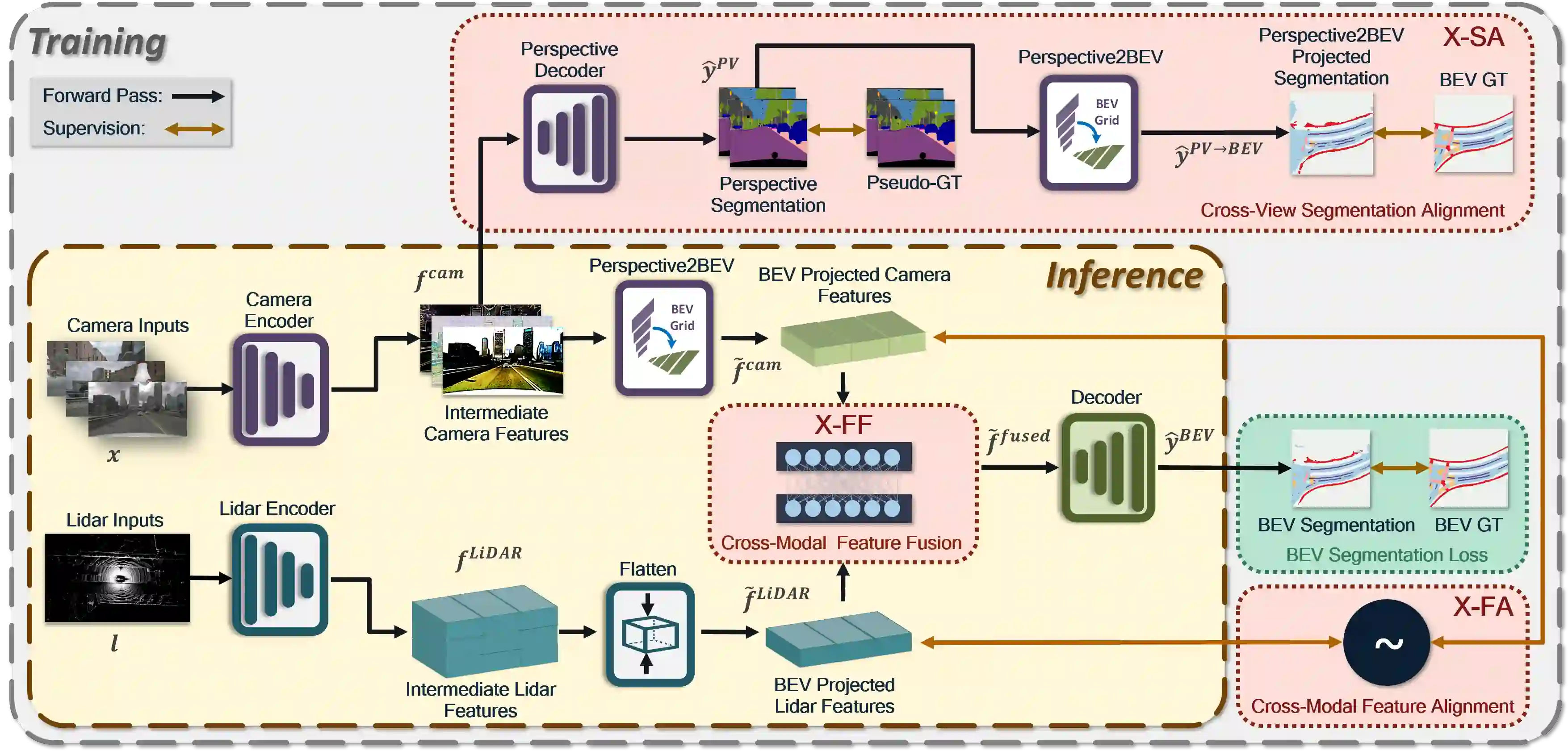
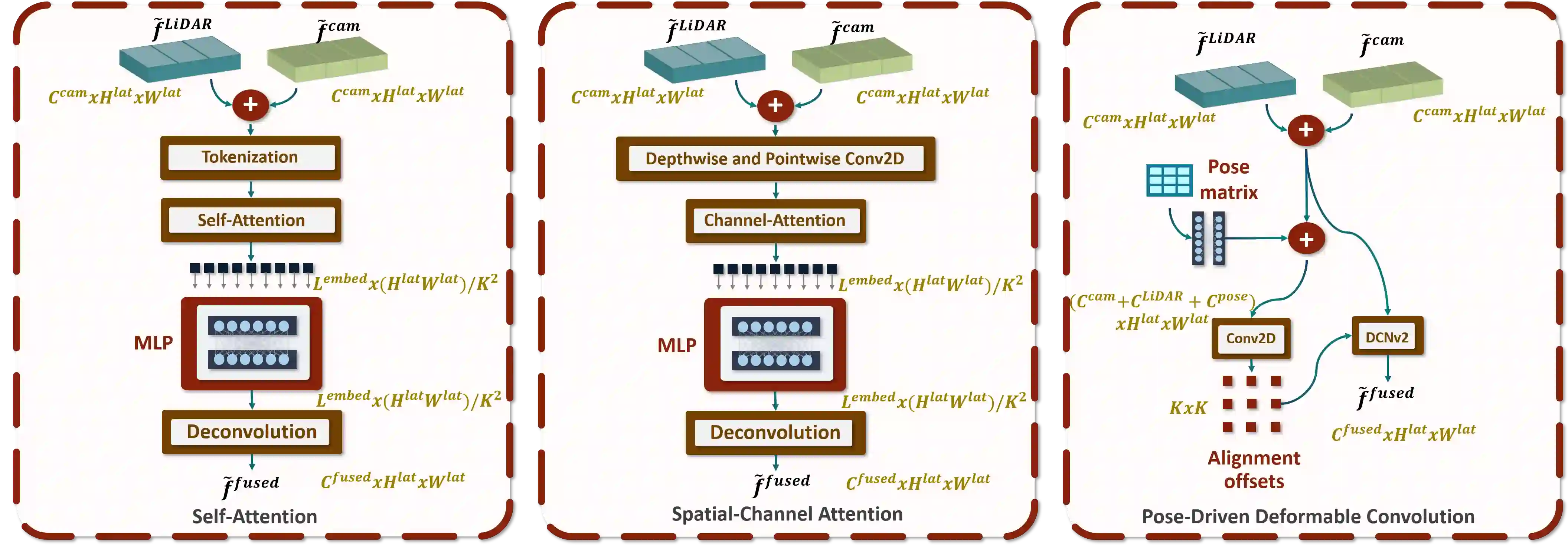
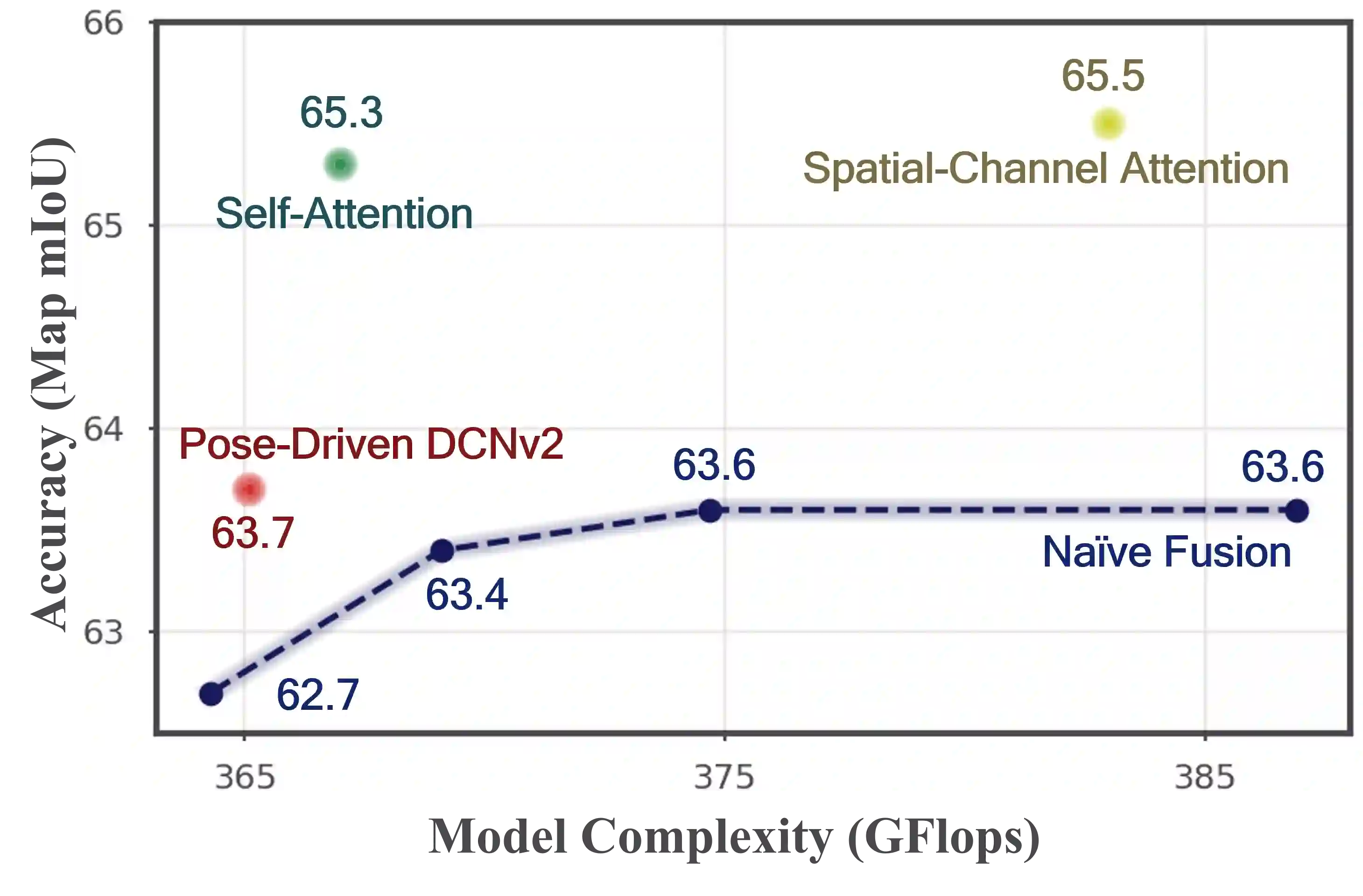
Bird's-eye-view (BEV) grid is a typical representation of the perception of road components, e.g., drivable area, in autonomous driving. Most existing approaches rely on cameras only to perform segmentation in BEV space, which is fundamentally constrained by the absence of reliable depth information. The latest works leverage both camera and LiDAR modalities but suboptimally fuse their features using simple, concatenation-based mechanisms. In this paper, we address these problems by enhancing the alignment of the unimodal features in order to aid feature fusion, as well as enhancing the alignment between the cameras' perspective view (PV) and BEV representations. We propose X-Align, a novel end-to-end cross-modal and cross-view learning framework for BEV segmentation consisting of the following components: (i) a novel Cross-Modal Feature Alignment (X-FA) loss, (ii) an attention-based Cross-Modal Feature Fusion (X-FF) module to align multi-modal BEV features implicitly, and (iii) an auxiliary PV segmentation branch with Cross-View Segmentation Alignment (X-SA) losses to improve the PV-to-BEV transformation. We evaluate our proposed method across two commonly used benchmark datasets, i.e., nuScenes and KITTI-360. Notably, X-Align significantly outperforms the state-of-the-art by 3 absolute mIoU points on nuScenes. We also provide extensive ablation studies to demonstrate the effectiveness of the individual components.
翻译:鸟瞰视图(BEV)网格是自动驾驶中道路组件(如可行驶区域)感知的典型表征。现有方法大多仅依靠摄像头在BEV空间中进行分割,这从根本上受限于缺乏可靠的深度信息。最新的研究同时利用摄像头和激光雷达模态,但通过简单的基于拼接的机制进行次优的特征融合。本文通过增强单模态特征的对齐以促进特征融合,并强化摄像头透视视图(PV)与BEV表征之间的对齐来解决这些问题。我们提出X-Align,一种新颖的端到端跨模态跨视图学习框架,用于BEV分割,包含以下组件:(i)新颖的跨模态特征对齐(X-FA)损失函数,(ii)基于注意力的跨模态特征融合(X-FF)模块以隐式对齐多模态BEV特征,以及(iii)带有交叉视图分割对齐(X-SA)损失的辅助PV分割分支,以改进PV到BEV的转换。我们在两个常用基准数据集(即nuScenes和KITTI-360)上评估了所提方法。值得注意的是,X-Align在nuScenes上的平均交并比(mIoU)显著超越现有技术水平达3个绝对百分点。我们还提供了大量的消融研究以证明各组件的有效性。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem
