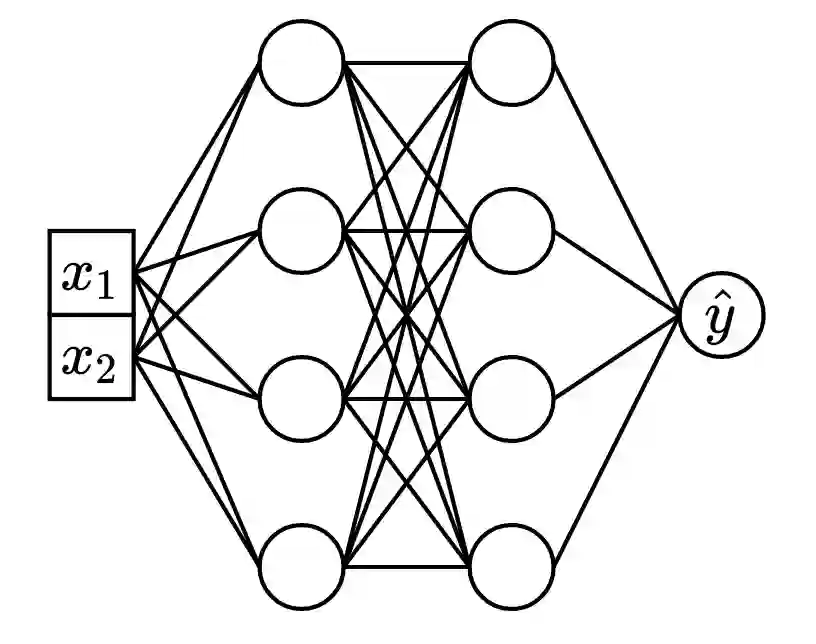
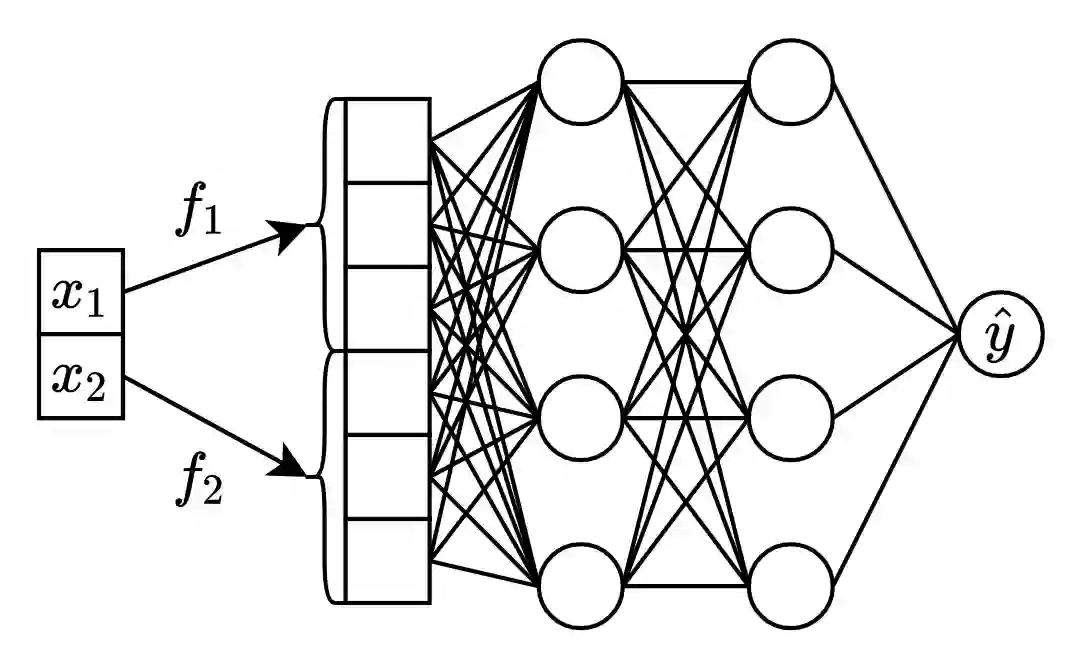
Recently, Transformer-like deep architectures have shown strong performance on tabular data problems. Unlike traditional models, e.g., MLP, these architectures map scalar values of numerical features to high-dimensional embeddings before mixing them in the main backbone. In this work, we argue that embeddings for numerical features are an underexplored degree of freedom in tabular DL, which allows constructing more powerful DL models and competing with GBDT on some traditionally GBDT-friendly benchmarks. We start by describing two conceptually different approaches to building embedding modules: the first one is based on a piecewise linear encoding of scalar values, and the second one utilizes periodic activations. Then, we empirically demonstrate that these two approaches can lead to significant performance boosts compared to the embeddings based on conventional blocks such as linear layers and ReLU activations. Importantly, we also show that embedding numerical features is beneficial for many backbones, not only for Transformers. Specifically, after proper embeddings, simple MLP-like models can perform on par with the attention-based architectures. Overall, we highlight embeddings for numerical features as an important design aspect with good potential for further improvements in tabular DL.
翻译:近年来,类似Transformer的深度架构在表格数据问题上展现出强劲性能。与传统模型(如MLP)不同,这些架构在主干网络中混合数值特征之前,会先将其标量值映射至高维嵌入。本文指出,数值特征嵌入在表格深度学习(DL)中是一个尚未充分探索的自由度,它能构建更强大的DL模型,并在某些传统上适合梯度提升决策树(GBDT)的基准测试中与之竞争。我们首先描述两种概念上不同的嵌入模块构建方法:第一种基于标量值的分段线性编码,第二种利用周期激活函数。接着通过实验证明,与基于线性层和ReLU激活函数等传统模块的嵌入相比,这两种方法能显著提升性能。重要的是,我们还发现数值特征嵌入对多种主干网络有益,而不仅限于Transformer。具体而言,经过适当嵌入后,简单的类MLP模型可与基于注意力的架构性能相当。总体而言,我们强调数值特征嵌入是表格深度学习中的重要设计考虑,具有进一步改进的潜力。