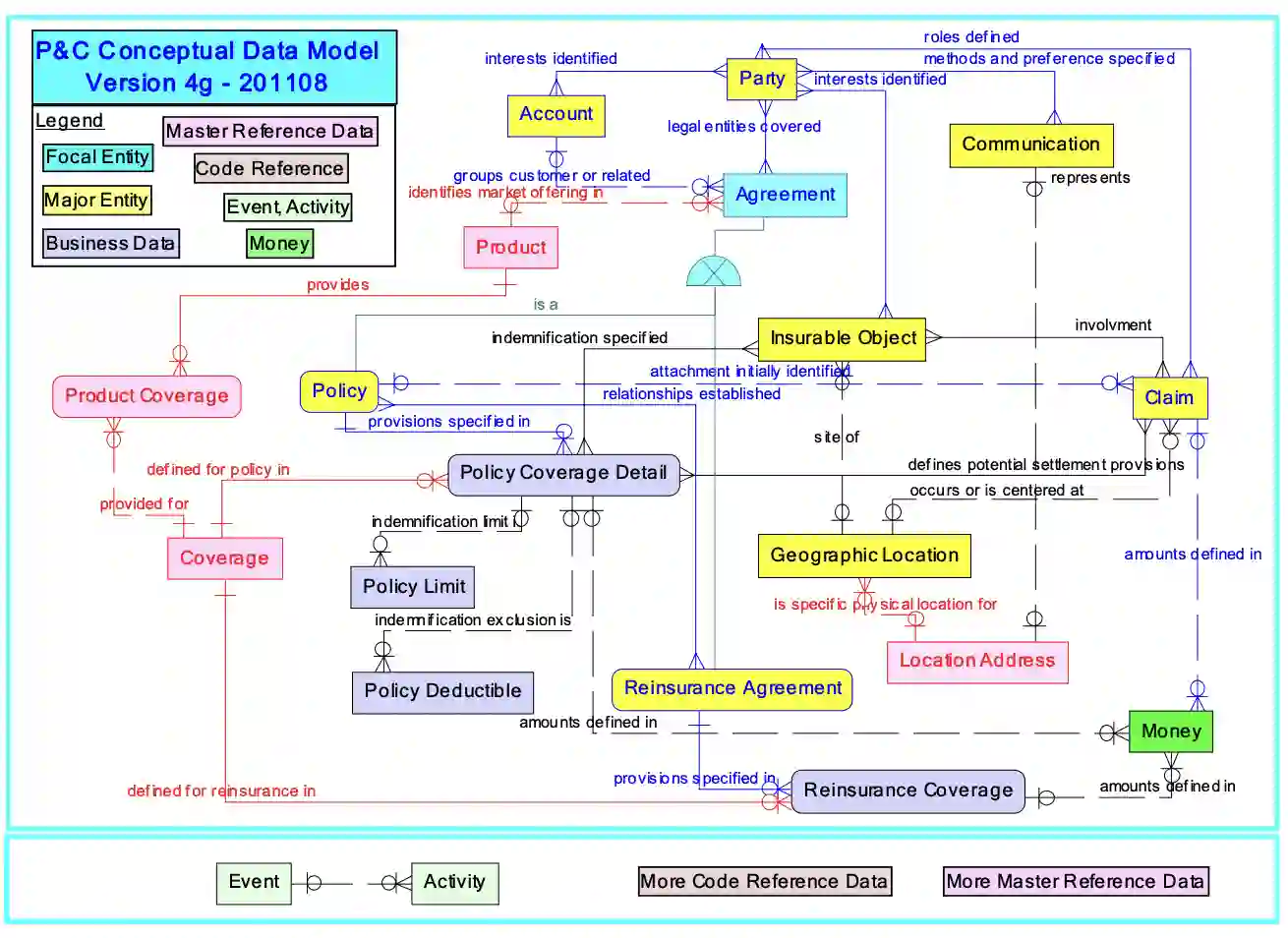
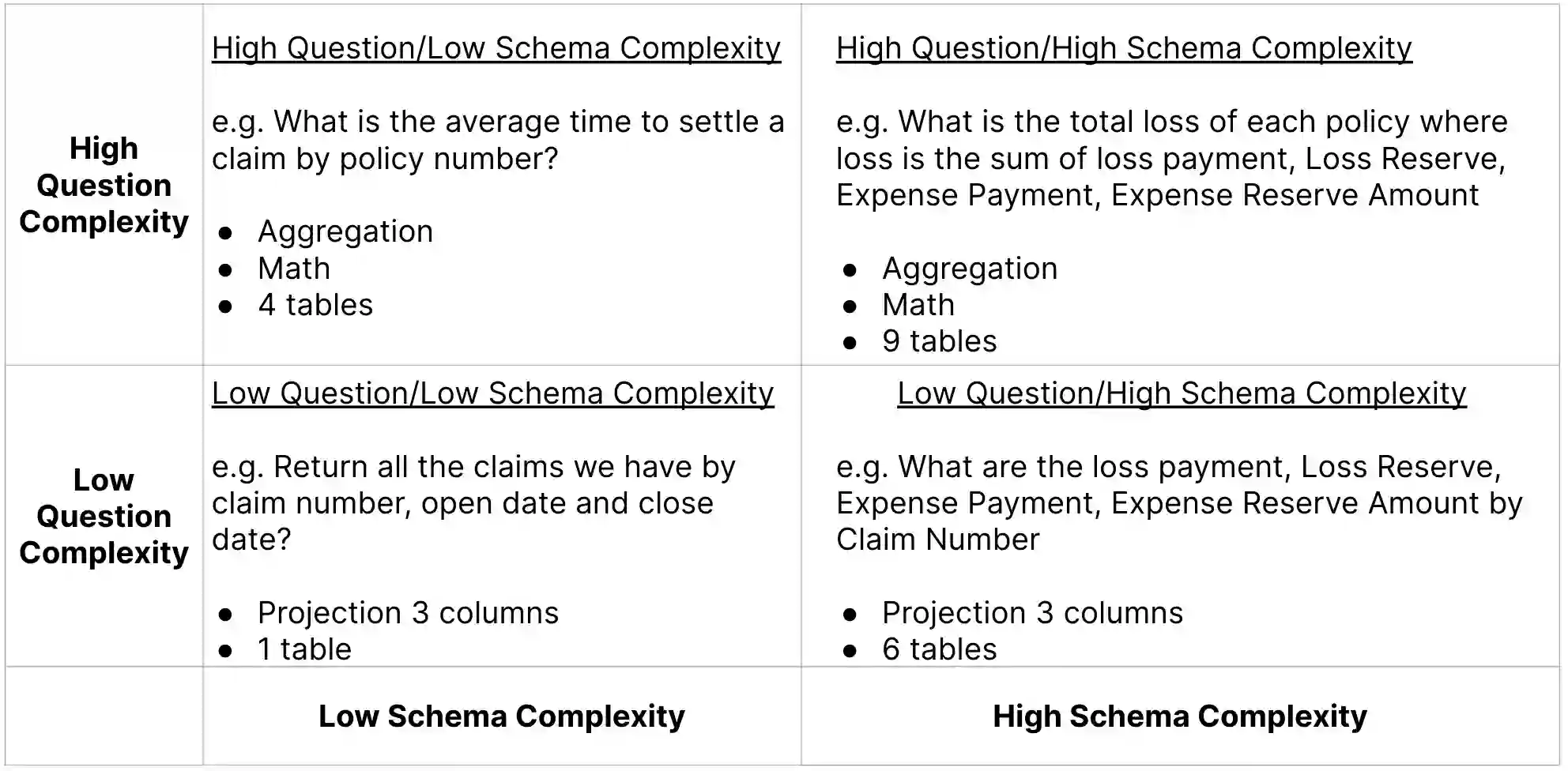
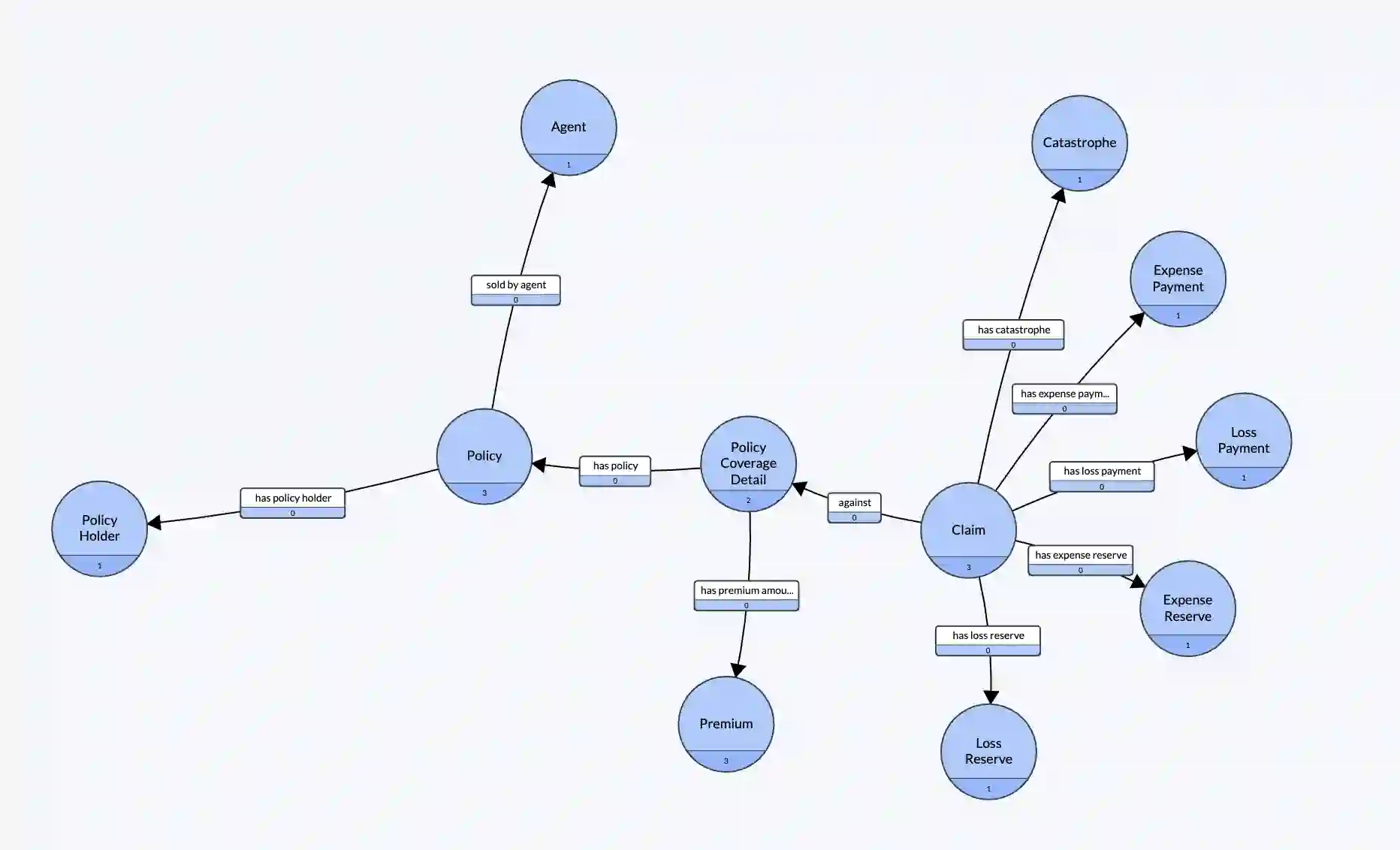
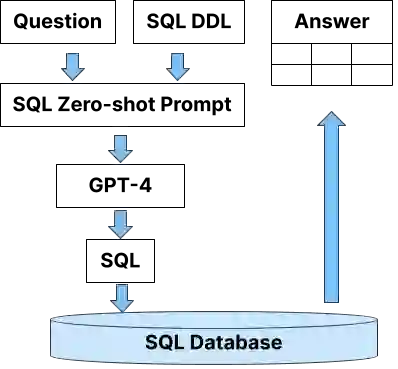
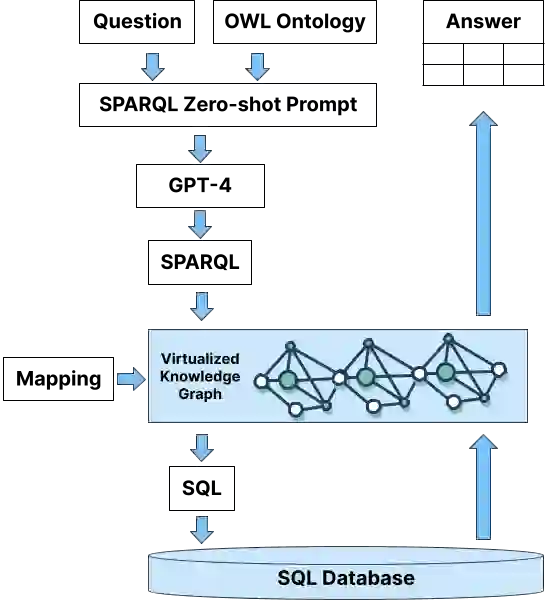
Enterprise applications of Large Language Models (LLMs) hold promise for question answering on enterprise SQL databases. However, the extent to which LLMs can accurately respond to enterprise questions in such databases remains unclear, given the absence of suitable Text-to-SQL benchmarks tailored to enterprise settings. Additionally, the potential of Knowledge Graphs (KGs) to enhance LLM-based question answering by providing business context is not well understood. This study aims to evaluate the accuracy of LLM-powered question answering systems in the context of enterprise questions and SQL databases, while also exploring the role of knowledge graphs in improving accuracy. To achieve this, we introduce a benchmark comprising an enterprise SQL schema in the insurance domain, a range of enterprise queries encompassing reporting to metrics, and a contextual layer incorporating an ontology and mappings that define a knowledge graph. Our primary finding reveals that question answering using GPT-4, with zero-shot prompts directly on SQL databases, achieves an accuracy of 16%. Notably, this accuracy increases to 54% when questions are posed over a Knowledge Graph representation of the enterprise SQL database. Therefore, investing in Knowledge Graph provides higher accuracy for LLM powered question answering systems.
翻译:大型语言模型(LLM)在企业应用中对SQL数据库进行问答具有潜力。然而,由于缺乏适用于企业环境的Text-to-SQL基准测试,LLM在面对企业数据库问题时能否准确回答仍不明确。此外,知识图谱(KG)通过提供业务上下文来增强基于LLM的问答能力,其潜力尚不为人所充分理解。本研究旨在评估基于LLM的问答系统在企业问题和SQL数据库背景下的准确性,同时探索知识图谱在提升准确性中的作用。为此,我们引入了一个基准,包括保险领域的企业SQL模式、从报表到指标的企业查询范围,以及包含定义知识图谱的本体和映射的上下文层。我们的主要发现是,使用GPT-4直接对SQL数据库进行零样本提示的问答准确率为16%。值得注意的是,当问题基于企业SQL数据库的知识图谱表示提出时,准确率提升至54%。因此,投资知识图谱可为基于LLM的问答系统提供更高的准确性。