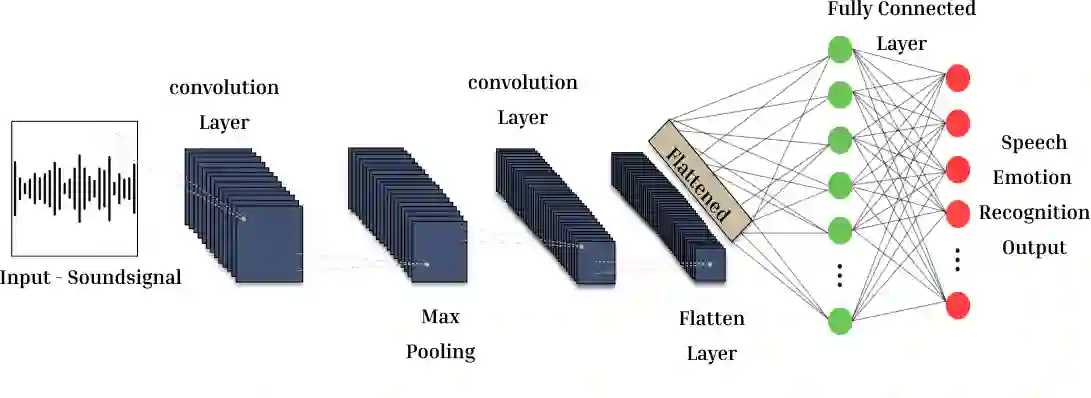
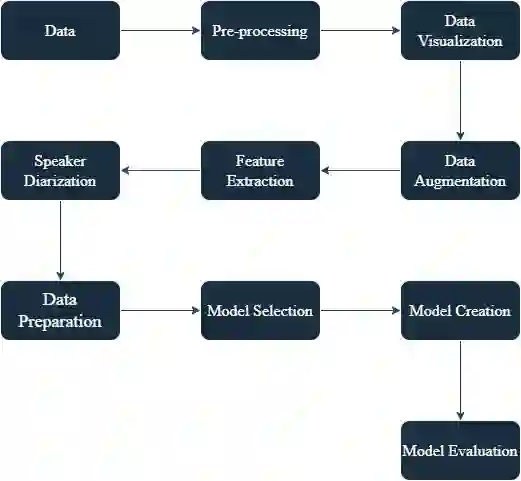
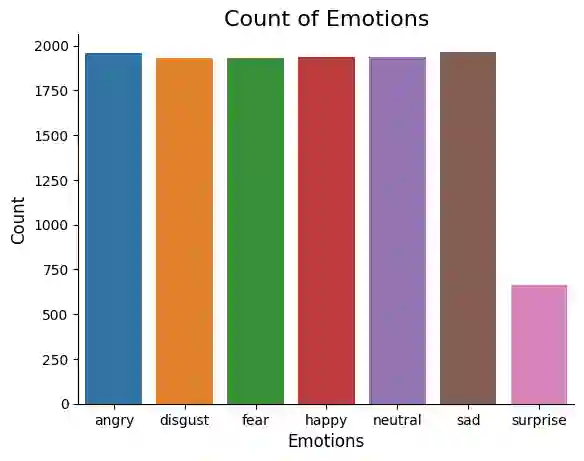
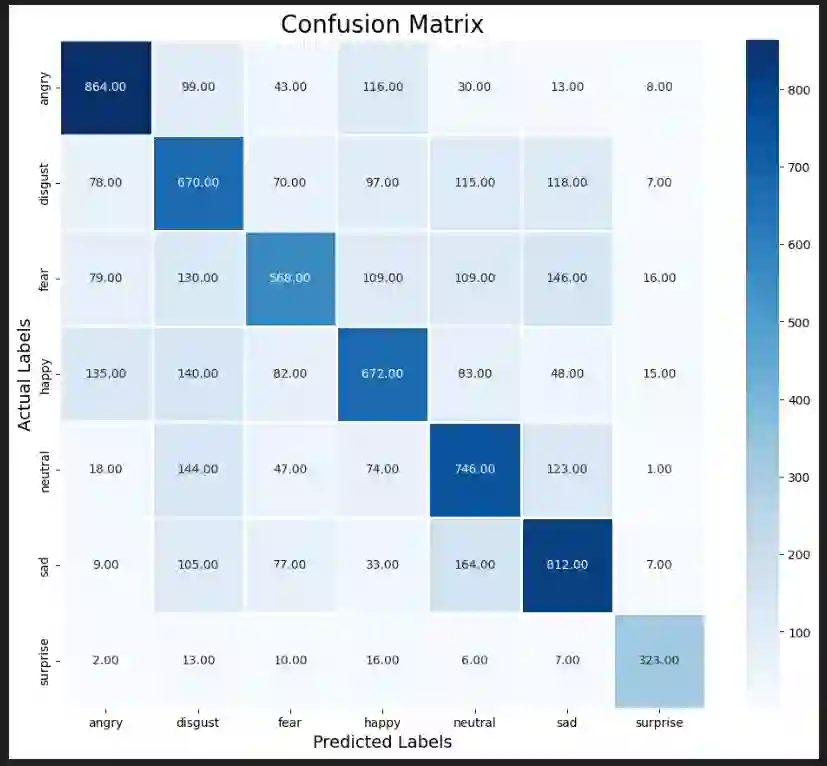
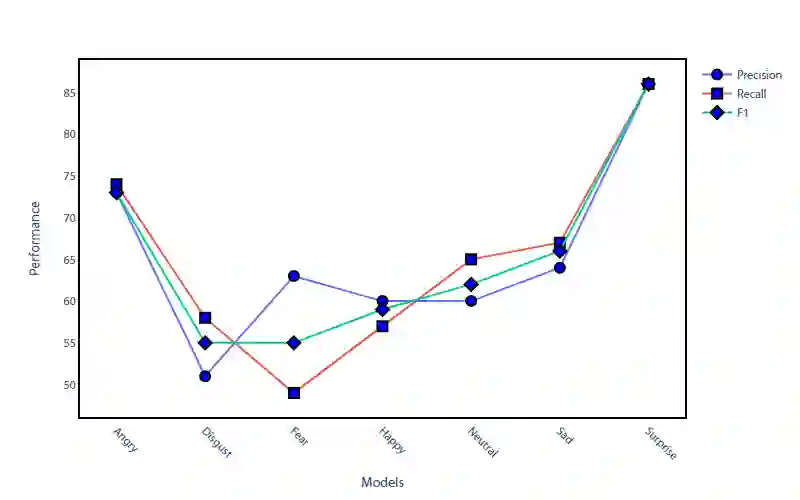
In the era of advanced artificial intelligence and human-computer interaction, identifying emotions in spoken language is paramount. This research explores the integration of deep learning techniques in speech emotion recognition, offering a comprehensive solution to the challenges associated with speaker diarization and emotion identification. It introduces a framework that combines a pre-existing speaker diarization pipeline and an emotion identification model built on a Convolutional Neural Network (CNN) to achieve higher precision. The proposed model was trained on data from five speech emotion datasets, namely, RAVDESS, CREMA-D, SAVEE, TESS, and Movie Clips, out of which the latter is a speech emotion dataset created specifically for this research. The features extracted from each sample include Mel Frequency Cepstral Coefficients (MFCC), Zero Crossing Rate (ZCR), Root Mean Square (RMS), and various data augmentation algorithms like pitch, noise, stretch, and shift. This feature extraction approach aims to enhance prediction accuracy while reducing computational complexity. The proposed model yields an unweighted accuracy of 63%, demonstrating remarkable efficiency in accurately identifying emotional states within speech signals.
翻译:在先进人工智能与人机交互时代,识别口语中的情感至关重要。本研究探索了深度学习技术在语音情感识别中的集成应用,针对说话人日志与情感识别面临的挑战提供了全面解决方案。本文提出一个框架,该框架结合了现有说话人日志流水线和基于卷积神经网络(CNN)构建的情感识别模型,以实现更高精度。所提出的模型基于五个语音情感数据集(即RAVDESS、CREMA-D、SAVEE、TESS和Movie Clips)进行训练,其中Movie Clips是专为本研究创建的语音情感数据集。从每个样本提取的特征包括梅尔频率倒谱系数(MFCC)、过零率(ZCR)、均方根(RMS)以及多种数据增强算法(如音调、噪声、拉伸和移位)。这种特征提取方法旨在提高预测准确率的同时降低计算复杂度。所提模型取得了63%的非加权准确率,展现了在语音信号中准确识别情感状态的显著效能。