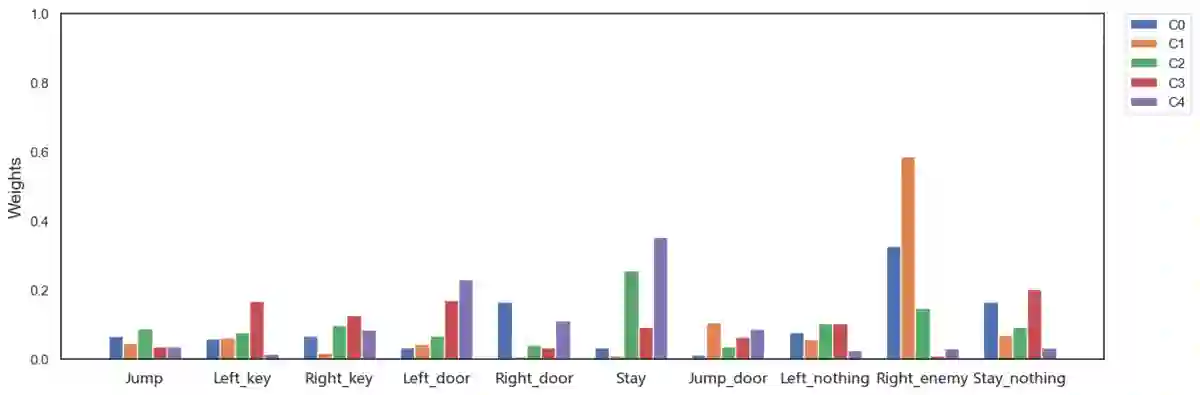
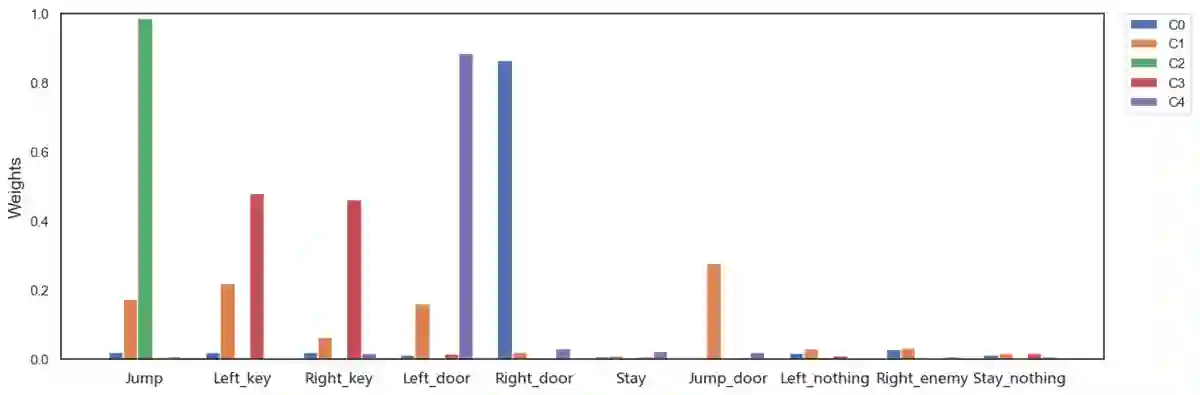
The limited priors required by neural networks make them the dominating choice to encode and learn policies using reinforcement learning (RL). However, they are also black-boxes, making it hard to understand the agent's behaviour, especially when working on the image level. Therefore, neuro-symbolic RL aims at creating policies that are interpretable in the first place. Unfortunately, interpretability is not explainability. To achieve both, we introduce Neurally gUided Differentiable loGic policiEs (NUDGE). NUDGE exploits trained neural network-based agents to guide the search of candidate-weighted logic rules, then uses differentiable logic to train the logic agents. Our experimental evaluation demonstrates that NUDGE agents can induce interpretable and explainable policies while outperforming purely neural ones and showing good flexibility to environments of different initial states and problem sizes.
翻译:神经网络所需先验知识有限,使其成为通过强化学习编码和学习策略的主要选择。然而,神经网络也是黑箱模型,难以理解智能体的行为,尤其是在图像层面进行决策时。因此,神经符号强化学习旨在优先构建具有可解释性的策略。但遗憾的是,可解释性并不等于可说明性。为实现两者兼顾,我们引入了神经引导可微逻辑策略(NUDGE)。NUDGE利用预训练的神经网络智能体引导候选加权逻辑规则的搜索,进而通过可微逻辑训练逻辑智能体。实验评估表明,NUDGE智能体能够归纳出既具可解释性又具可说明性的策略,同时其性能优于纯神经策略,并对不同初始状态和问题规模的环境展现出良好的适应性。