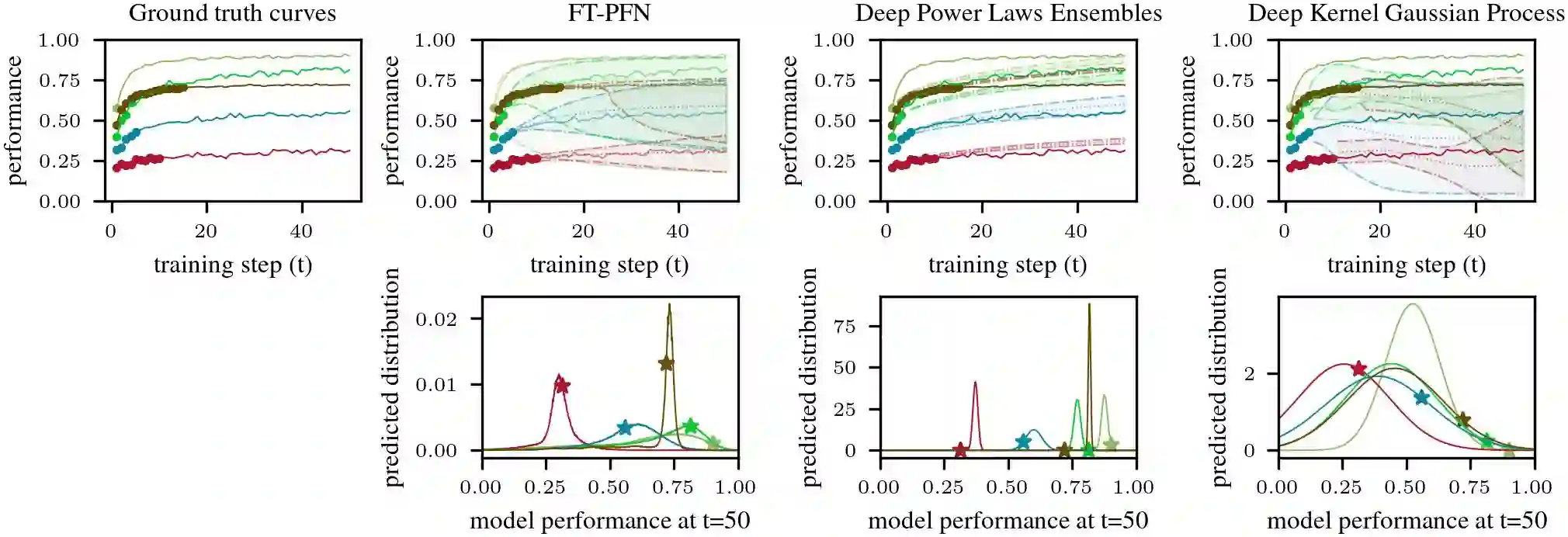
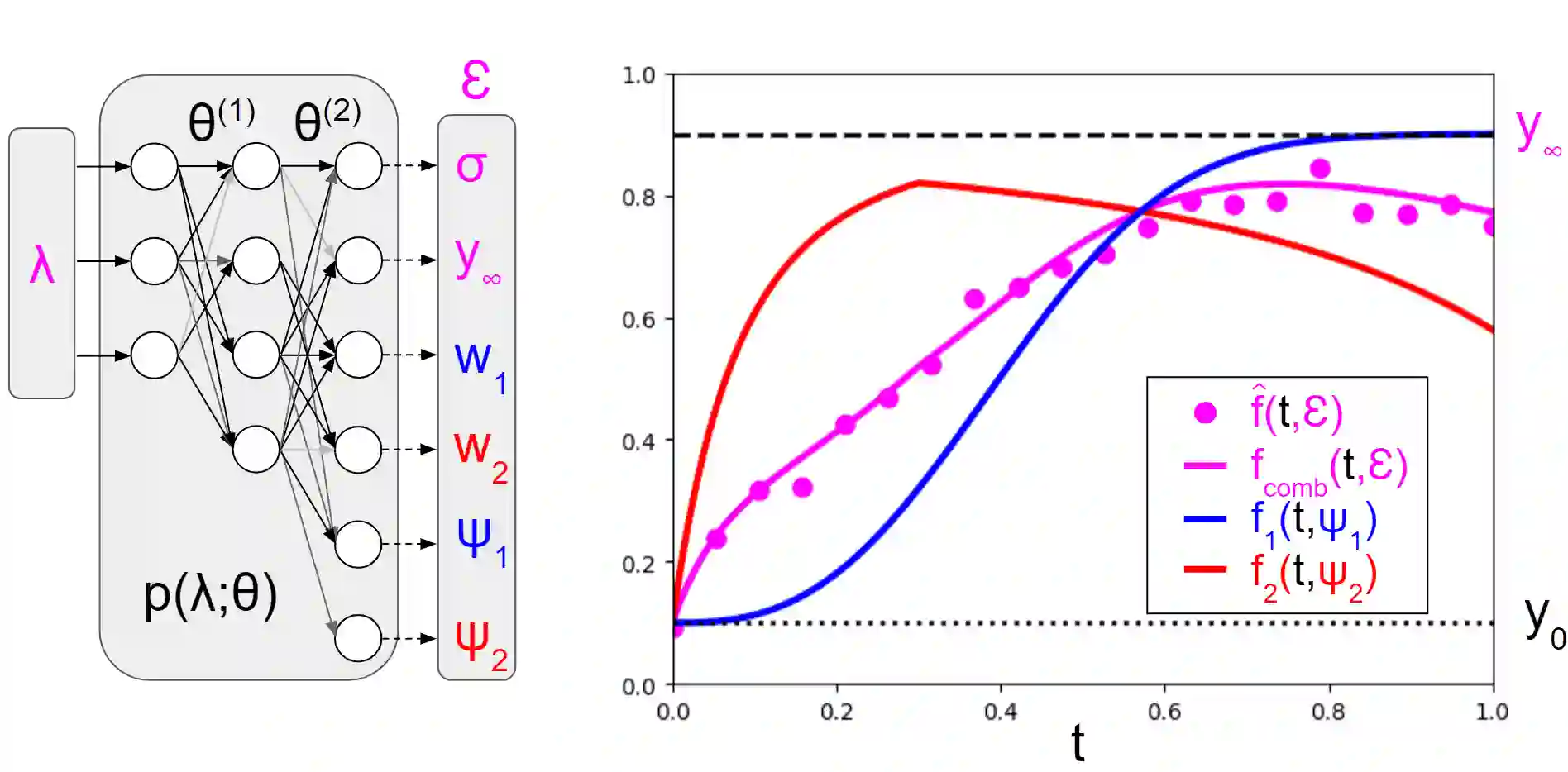
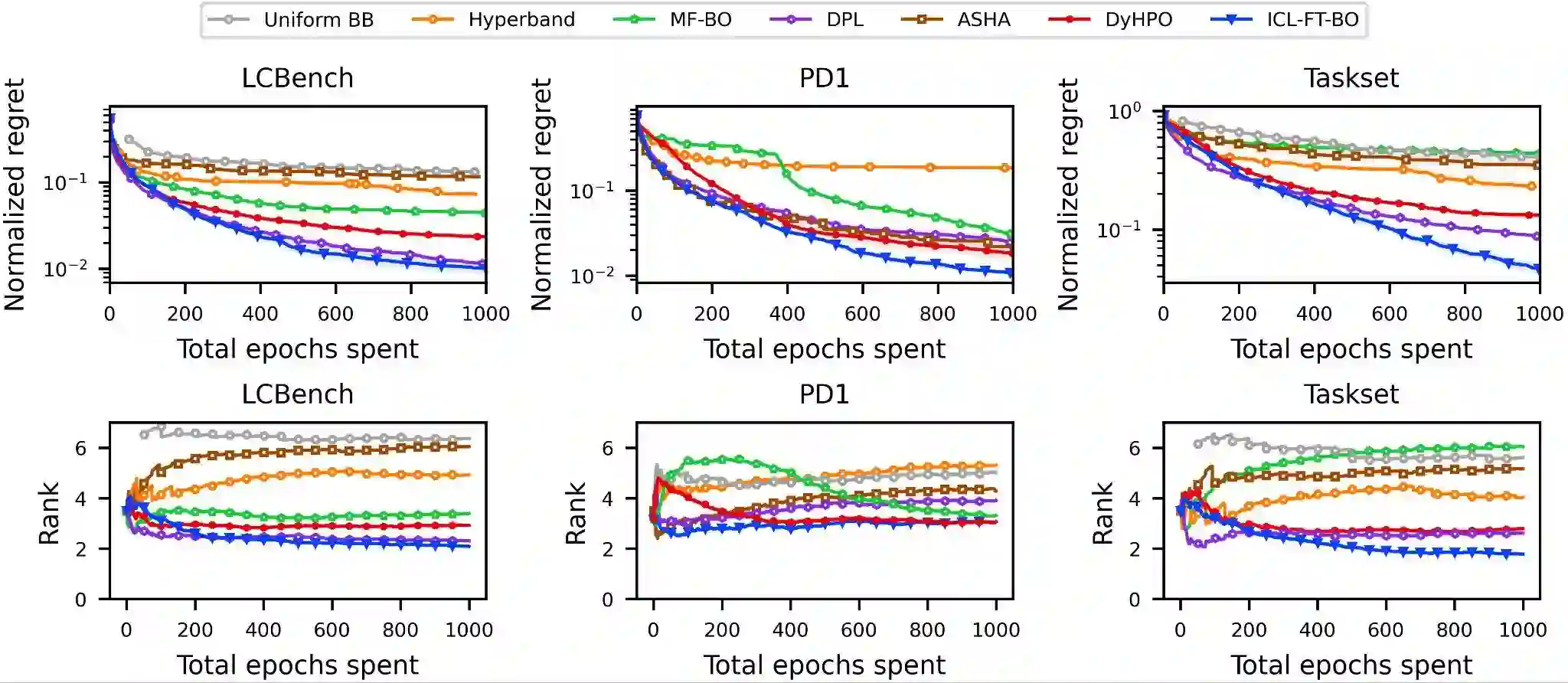
With the increasing computational costs associated with deep learning, automated hyperparameter optimization methods, strongly relying on black-box Bayesian optimization (BO), face limitations. Freeze-thaw BO offers a promising grey-box alternative, strategically allocating scarce resources incrementally to different configurations. However, the frequent surrogate model updates inherent to this approach pose challenges for existing methods, requiring retraining or fine-tuning their neural network surrogates online, introducing overhead, instability, and hyper-hyperparameters. In this work, we propose FT-PFN, a novel surrogate for Freeze-thaw style BO. FT-PFN is a prior-data fitted network (PFN) that leverages the transformers' in-context learning ability to efficiently and reliably do Bayesian learning curve extrapolation in a single forward pass. Our empirical analysis across three benchmark suites shows that the predictions made by FT-PFN are more accurate and 10-100 times faster than those of the deep Gaussian process and deep ensemble surrogates used in previous work. Furthermore, we show that, when combined with our novel acquisition mechanism (MFPI-random), the resulting in-context freeze-thaw BO method (ifBO), yields new state-of-the-art performance in the same three families of deep learning HPO benchmarks considered in prior work.
翻译:随着深度学习计算成本的不断增加,严重依赖黑箱贝叶斯优化的自动化超参数优化方法面临局限性。冻结-解冻贝叶斯优化提供了一种有前景的灰箱替代方案,能够将稀缺资源逐步战略性地分配给不同配置。然而,该方法固有的频繁替代模型更新给现有方法带来了挑战,需要在线重新训练或微调其神经网络替代模型,从而引入开销、不稳定性和超-超参数。在本工作中,我们提出FT-PFN,一种用于冻结-解冻风格贝叶斯优化的新型替代模型。FT-PFN是一种先验数据拟合网络,利用Transformer的上下文内学习能力,通过单次前向传播高效且可靠地进行贝叶斯学习曲线外推。我们在三个基准套件上的实证分析表明,FT-PFN的预测比先前工作中使用的深度高斯过程和深度集成替代模型更准确,且速度快10至100倍。此外,我们证明,当与我们的新型采集机制(MFPI-random)相结合时,所得到的上下文内冻结-解冻贝叶斯优化方法在先前工作考虑的三个深度学习超参数优化基准系列上均取得了新的最优性能。