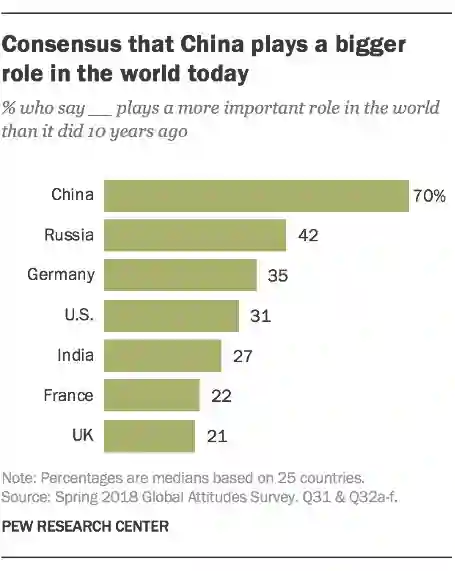
Charts play a vital role in data visualization, understanding data patterns, and informed decision-making. However, their unique combination of graphical elements (e.g., bars, lines) and textual components (e.g., labels, legends) poses challenges for general-purpose multimodal models. While vision-language models trained on chart data excel in comprehension, they struggle with generalization and require task-specific fine-tuning. To address these challenges, we propose ChartAssistant, a chart-based vision-language model for universal chart comprehension and reasoning. ChartAssistant leverages ChartSFT, a comprehensive dataset covering diverse chart-related tasks with basic and specialized chart types. It undergoes a two-stage training process, starting with pre-training on chart-to-table parsing to align chart and text, followed by multitask instruction-following fine-tuning. This approach enables ChartAssistant to achieve competitive performance across various chart tasks without task-specific fine-tuning. Experimental results demonstrate significant performance gains over the state-of-the-art UniChart method, outperforming OpenAI's GPT-4V(ision) on real-world chart data. The code and data are available at https://github.com/OpenGVLab/ChartAst.
翻译:图表在数据可视化、理解数据模式以及支持知情决策中发挥着至关重要的作用。然而,图表中图形元素(如条形图、折线图)与文本组件(如标签、图例)的独特组合,给通用多模态模型带来了挑战。尽管基于图表数据训练的视觉-语言模型在理解方面表现出色,但其在泛化方面存在困难,且需要针对特定任务进行微调。为应对这些挑战,我们提出了ChartAssistant,这是一种基于图表的视觉-语言模型,用于实现通用图表的理解与推理。ChartAssistant利用ChartSFT这一综合数据集,该数据集涵盖了与图表相关的多种任务,包含基础及专业图表类型。该模型采用两阶段训练流程:首先进行图表到表格的解析预训练,以对齐图表与文本;随后进行多任务指令遵循微调。这一方法使ChartAssistant能够在无需任务特定微调的情况下,在各种图表任务中取得具有竞争力的表现。实验结果表明,相比当前最先进的UniChart方法,该方法取得了显著的性能提升,并在真实图表数据上超越了OpenAI的GPT-4V(ision)。代码与数据可从 https://github.com/OpenGVLab/ChartAst 获取。