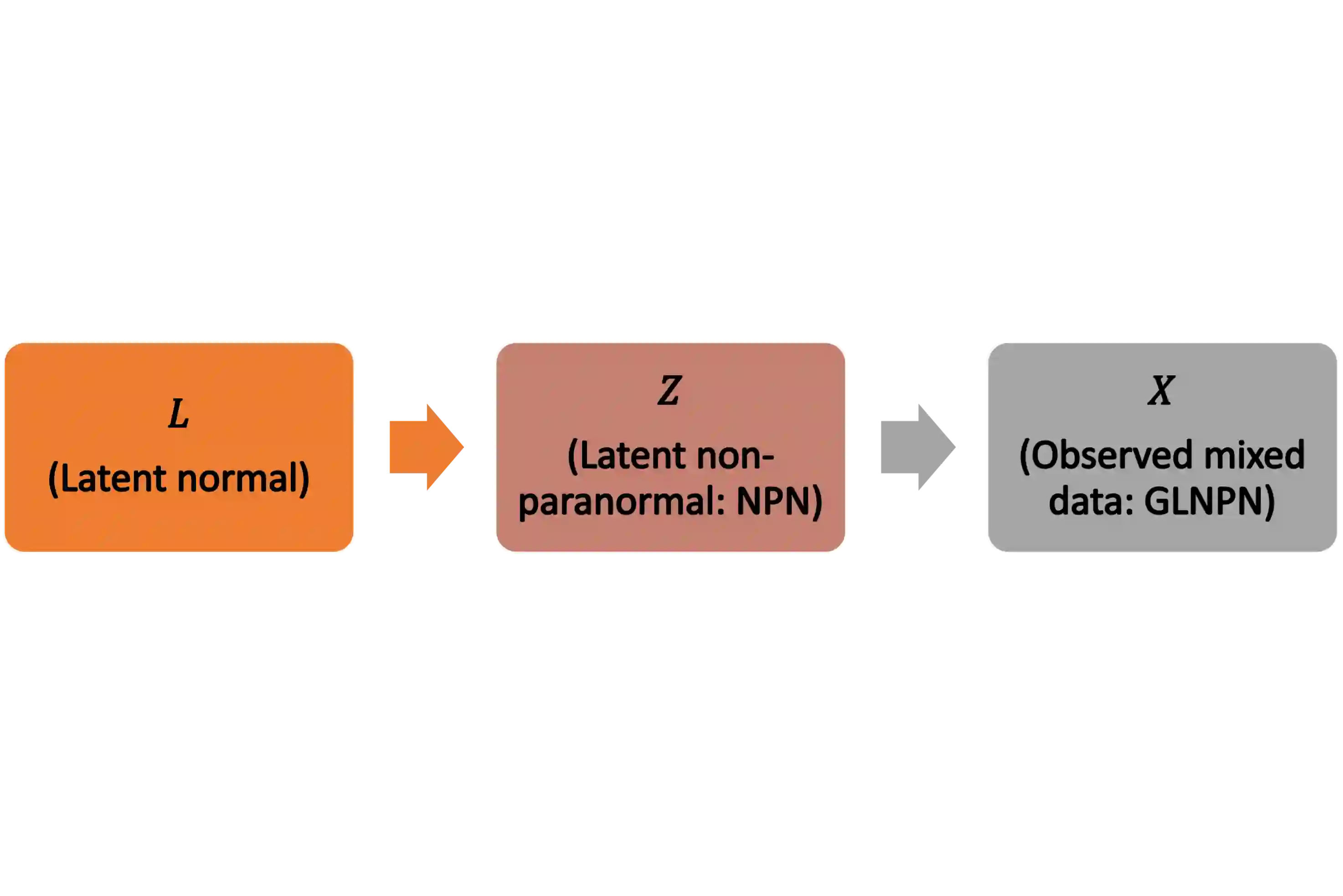
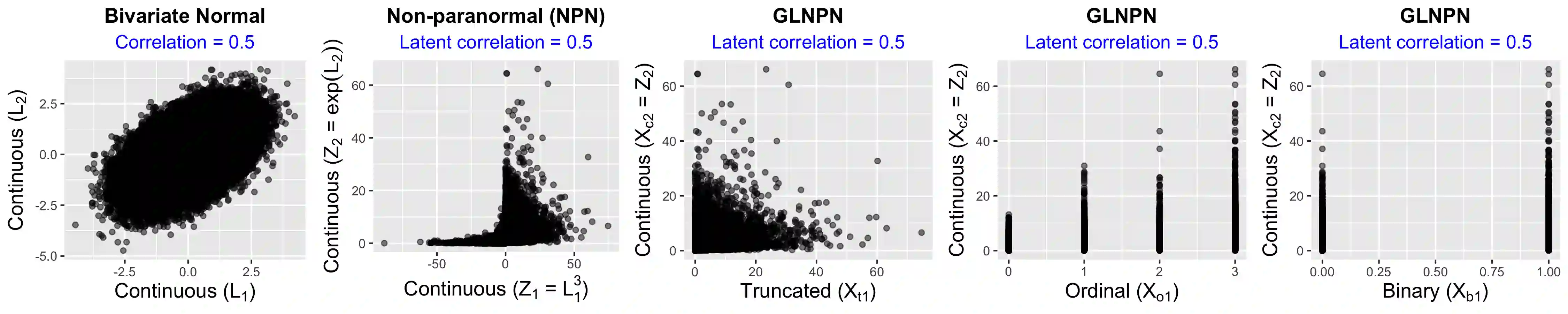
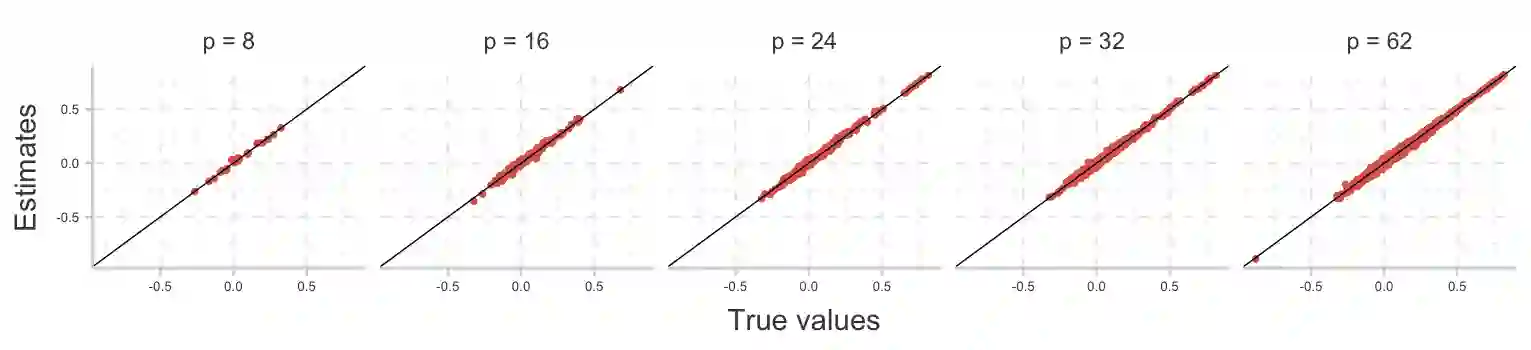
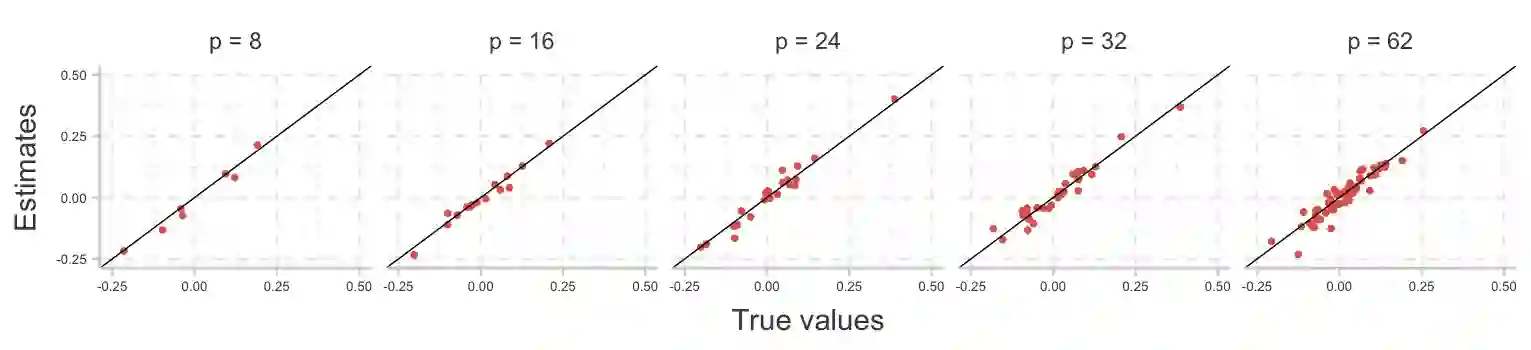
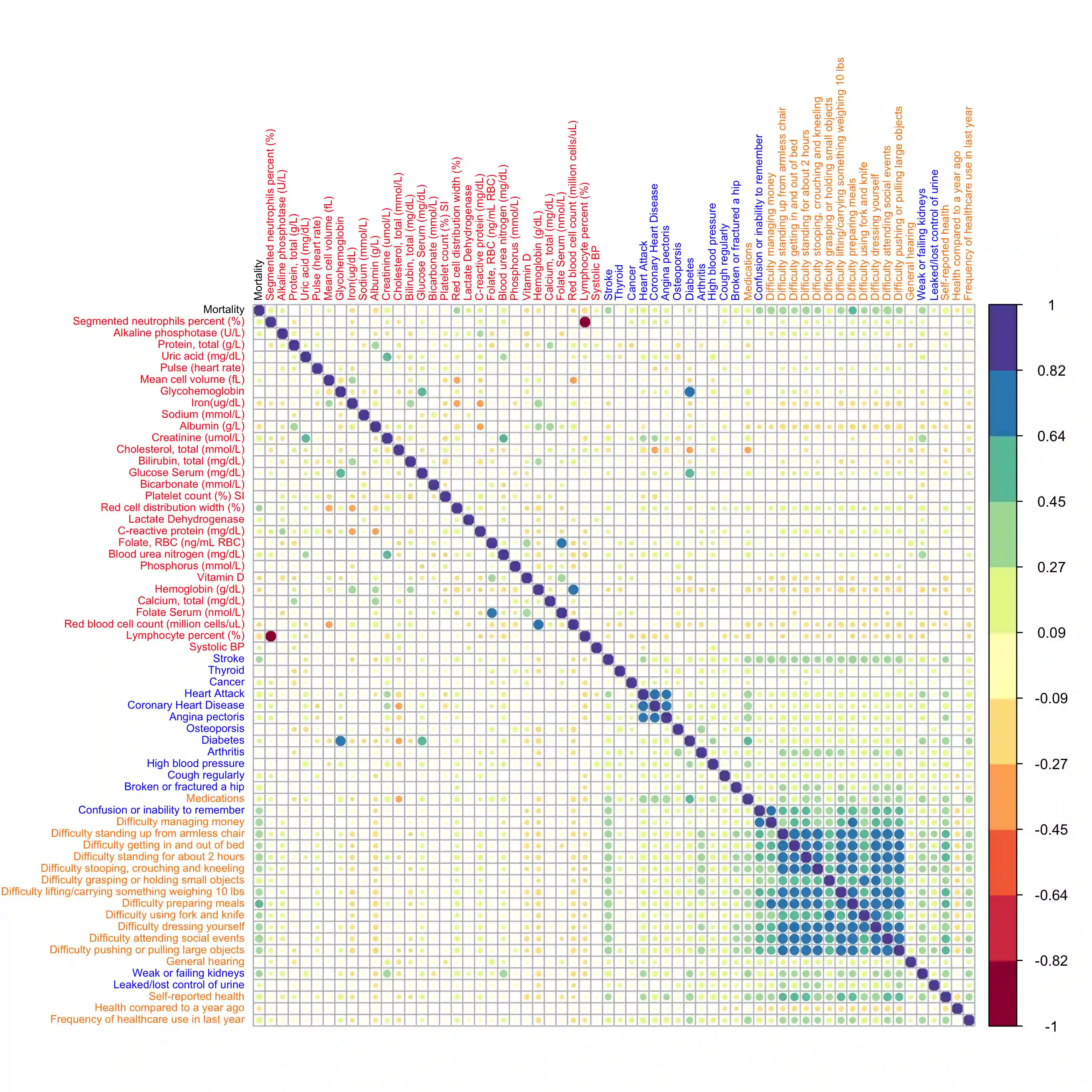
Clinical and epidemiological studies encode participant information in multivariate vectors with mixed type variables on continuous, truncated, ordinal, and binary scales. Semiparametric Gaussian Copula (SGC) assumes that observed data is generated by latent multivariate normal random variables which marginals are monotonically transformed and then truncated/ordinalized/binarized. In SGC, the latent correlation matrix fully determines the dependence structure and it is estimated through an inversion of ``bridges'' between Kendall's Tau rank correlations of observed variables and latent correlations. By employing SGC, we develop regression (SGC-Reg), principal component analysis (SGC-PCA), and principal component regression (SGC-PCR) for latent representations of observed data. To build our framework, we make several key contributions: i) establishing novel bridging results for general ordinal type variables, ii) developing regression estimation on the latent space and deriving asymptotic normality of estimators, iii) developing a computationally efficient algorithm that reduces calculation complexity of all steps including calculation of asymptotic covariance matrix from $O(n^4)$ to $O(n\log n)$, iv) developing methods to predict latent representations of observed data and perform imputation of missing data, and v) developing principal component analysis and principal component regression on the latent space. We apply our framework to study the association between a 5-year mortality and 61 frailty-related measures composed of 29 continuous, 17 ordinal, and 15 binary variables in 9478 participants of 1999-2010 waves of National Health and Nutrition Examination Survey (NHANES).
翻译:临床与流行病学研究通常将参与者信息编码为包含连续型、截断型、有序型及二元型变量的多元混合类型数据向量。半参数高斯Copula(SGC)假设观测数据由潜变量多元正态随机变量生成,这些潜变量的边际经过单调变换后,再经过截断/有序化/二元化处理。在SGC框架中,潜变量相关矩阵完全决定了变量间的依赖结构,其估计通过观测变量的Kendall's Tau秩相关与潜变量相关性之间的"桥接"反演实现。基于SGC,我们针对观测数据的潜变量表征开发了回归模型(SGC-Reg)、主成分分析(SGC-PCA)以及主成分回归(SGC-PCR)。为构建此框架,我们做出了以下关键贡献:一)建立适用于一般有序型变量的新型桥接理论;二)开发潜变量空间的回归估计方法并推导估计量的渐近正态性;三)提出计算高效算法,将包括渐近协方差矩阵计算在内的所有步骤计算复杂度从$O(n^4)$降至$O(n\log n)$;四)开发观测数据潜变量表征的预测方法及缺失数据插补技术;五)构建潜变量空间的主成分分析与主成分回归方法。我们将该框架应用于研究1999-2010年美国国家健康与营养调查(NHANES)9478名参与者中,61项衰弱相关指标(包含29个连续变量、17个有序变量和15个二元变量)与五年死亡率之间的关联关系。