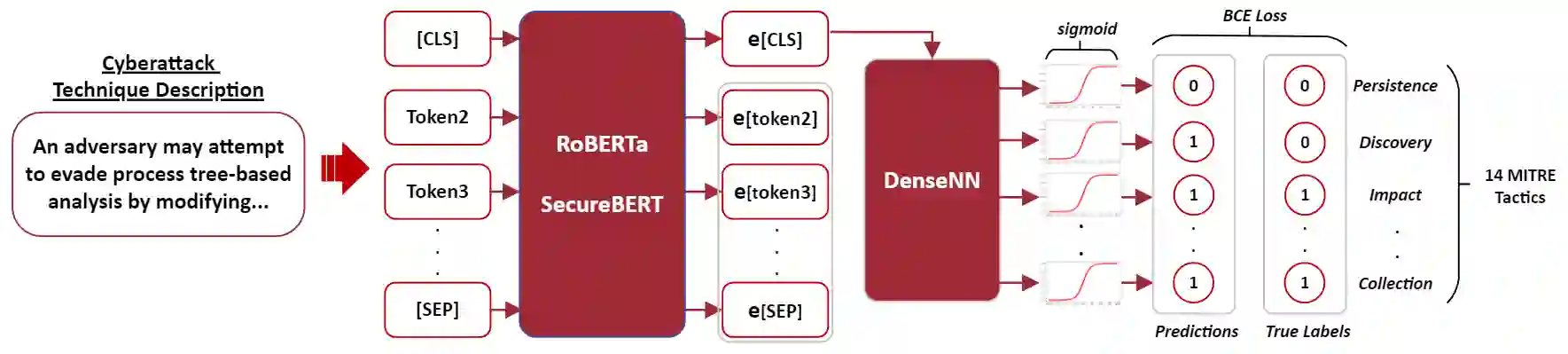
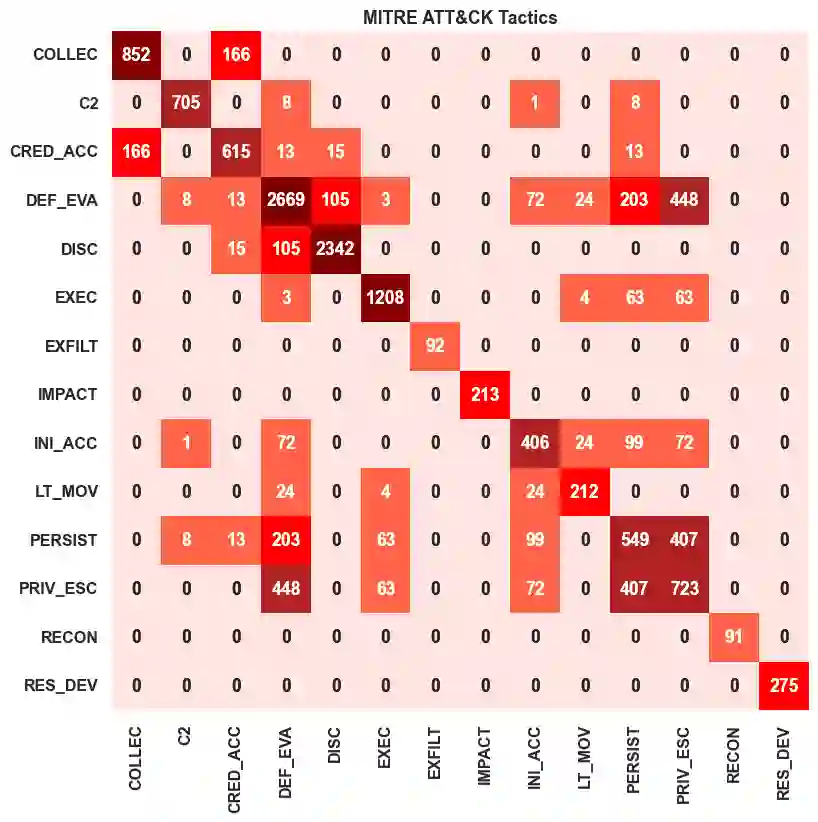
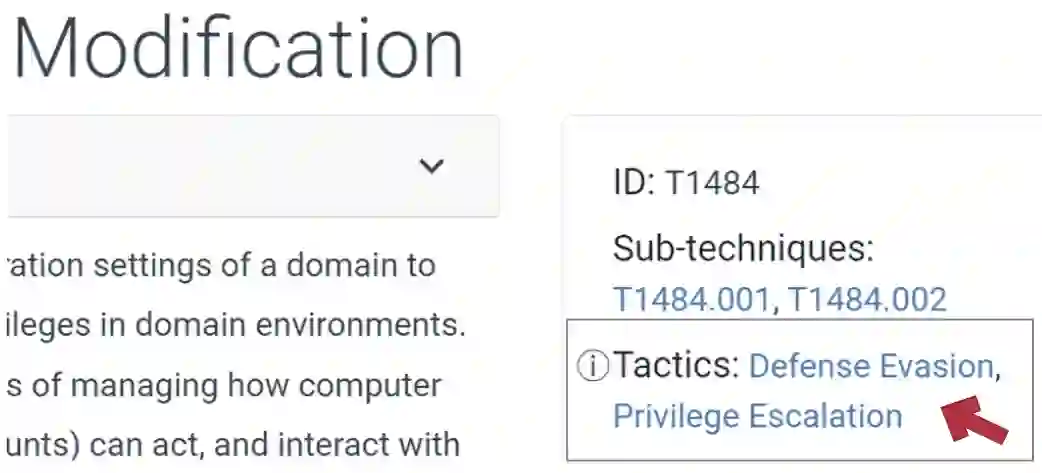
Tactics, Techniques, and Procedures (TTPs) outline the methods attackers use to exploit vulnerabilities. The interpretation of TTPs in the MITRE ATT&CK framework can be challenging for cybersecurity practitioners due to presumed expertise, complex dependencies, and inherent ambiguity. Meanwhile, advancements with Large Language Models (LLMs) have led to recent surge in studies exploring its uses in cybersecurity operations. This leads us to question how well encoder-only (e.g., RoBERTa) and decoder-only (e.g., GPT-3.5) LLMs can comprehend and summarize TTPs to inform analysts of the intended purposes (i.e., tactics) of a cyberattack procedure. The state-of-the-art LLMs have shown to be prone to hallucination by providing inaccurate information, which is problematic in critical domains like cybersecurity. Therefore, we propose the use of Retrieval Augmented Generation (RAG) techniques to extract relevant contexts for each cyberattack procedure for decoder-only LLMs (without fine-tuning). We further contrast such approach against supervised fine-tuning (SFT) of encoder-only LLMs. Our results reveal that both the direct-use of decoder-only LLMs (i.e., its pre-trained knowledge) and the SFT of encoder-only LLMs offer inaccurate interpretation of cyberattack procedures. Significant improvements are shown when RAG is used for decoder-only LLMs, particularly when directly relevant context is found. This study further sheds insights on the limitations and capabilities of using RAG for LLMs in interpreting TTPs.
翻译:战术、技术与程序(TTP)描述了攻击者利用漏洞的方法。由于预设专业知识、复杂依赖关系及内在歧义性,MITRE ATT&CK框架中TTP的解读对网络安全从业者而言颇具挑战。与此同时,大型语言模型(LLMs)的进展推动了网络安全应用中相关研究的热潮。这引发我们思考:编码器专用模型(如RoBERTa)与解码器专用模型(如GPT-3.5)能否有效理解并总结TTP,从而向分析师揭示网络攻击程序的目标意图(即战术)。最新LLMs易产生"幻觉"——提供不准确信息,这在网络安全等关键领域尤为棘手。为此,我们提出采用检索增强生成(RAG)技术,为解码器专用LLMs(无需微调)提取每个网络攻击程序的相关上下文。进一步将此类方法与编码器专用LLMs的监督微调(SFT)进行对比。结果表明:直接使用解码器专用LLMs(即其预训练知识)与编码器专用LLMs的监督微调均存在对网络攻击程序的错误解读。当RAG应用于解码器专用LLMs时,尤其在找到直接相关上下文的情况下,性能显著提升。本研究进一步揭示了RAG在LLMs解读TTP中的能力边界与局限性。