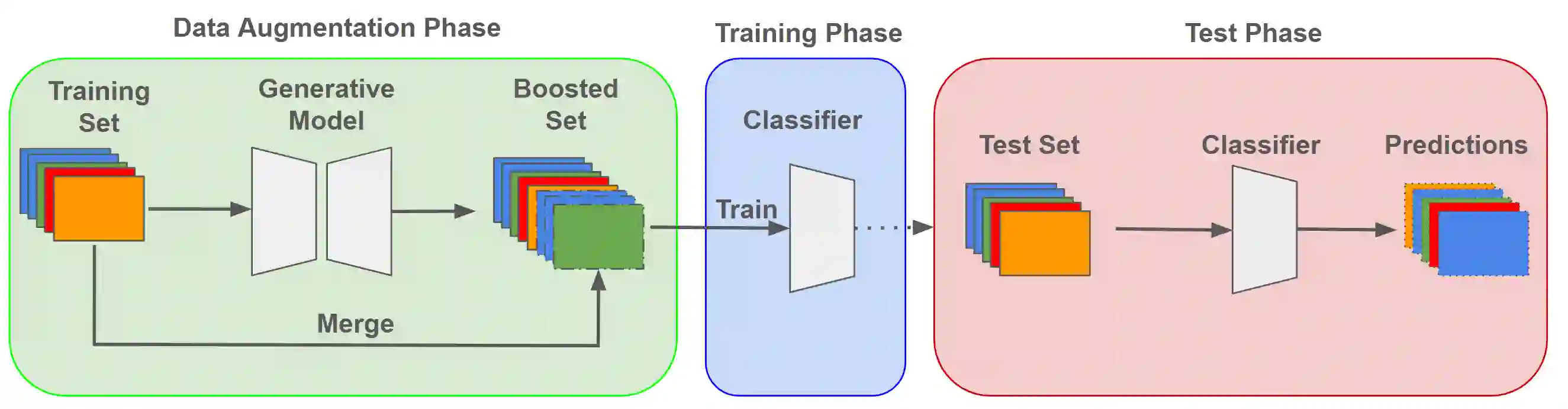
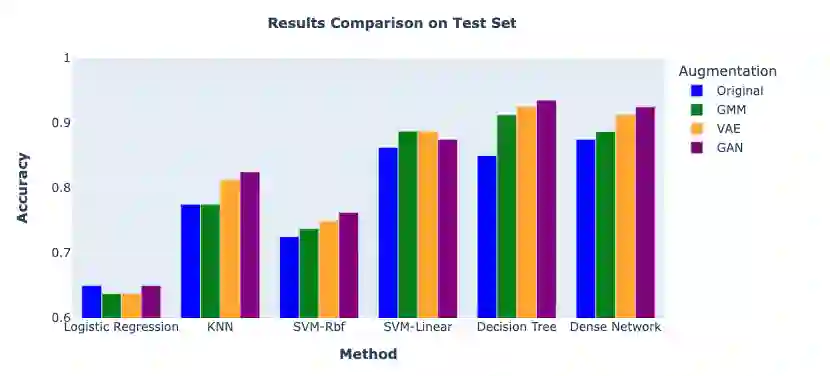
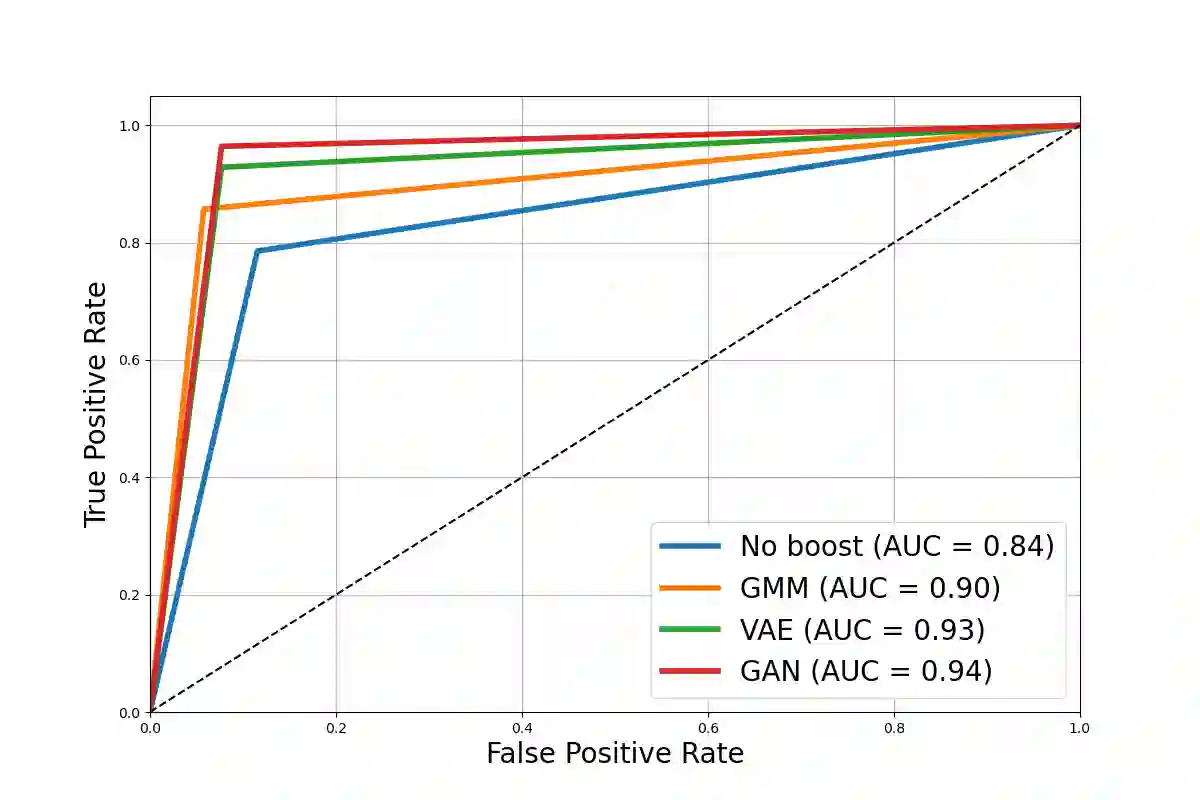
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.
翻译:在社交网络广告不断发展的背景下,数据的数量与准确性对预测模型的性能起着关键作用。然而,由于现实数据集的规模有限且可能存在偏差,稳健预测算法的开发常受到阻碍。本研究提出并探索了一种面向社交网络广告数据的生成式增强框架。该框架考察了三种用于数据增强的生成模型——生成对抗网络(GANs)、变分自编码器(VAEs)和高斯混合模型(GMMs),旨在丰富社交网络广告分析效能背景下数据的可用性与多样性。通过对特征空间进行合成扩展,我们发现数据增强能够定量提升多种分类器的性能。此外,我们比较了每种数据增强技术所带来的相对性能增益,为实践者选择适当技术以提升模型性能提供了启示。本文通过证明合成数据增强可缓解社交网络广告领域中因数据集规模小或不平衡带来的局限性,为相关文献作出了贡献。同时,本文还提供了对不同数据增强方法实用性的比较视角,从而指导实践者选择合适的技术以提升模型性能。