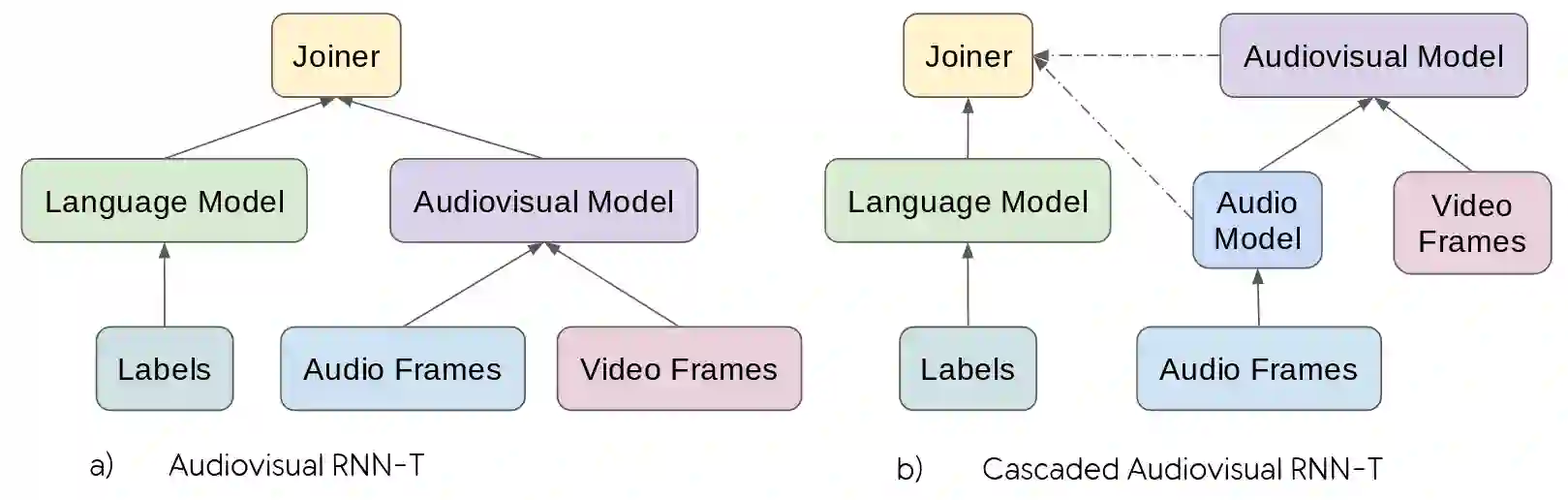
It has been shown that learning audiovisual features can lead to improved speech recognition performance over audio-only features, especially for noisy speech. However, in many common applications, the visual features are partially or entirely missing, e.g.~the speaker might move off screen. Multi-modal models need to be robust: missing video frames should not degrade the performance of an audiovisual model to be worse than that of a single-modality audio-only model. While there have been many attempts at building robust models, there is little consensus on how robustness should be evaluated. To address this, we introduce a framework that allows claims about robustness to be evaluated in a precise and testable way. We also conduct a systematic empirical study of the robustness of common audiovisual speech recognition architectures on a range of acoustic noise conditions and test suites. Finally, we show that an architecture-agnostic solution based on cascades can consistently achieve robustness to missing video, even in settings where existing techniques for robustness like dropout fall short.
翻译:已有研究表明,相比于仅基于音频的特征,学习视听特征能提升语音识别性能,尤其在噪声环境下效果更为显著。然而在许多常见应用中,视觉特征会部分或完全缺失(例如说话者可能移出画面)。多模态模型需具备鲁棒性:视频帧的缺失不应导致视听模型的性能劣于单一模态的纯音频模型。尽管已有诸多构建鲁棒模型的尝试,但关于鲁棒性评估方法尚未形成共识。为此,我们提出一个可精确且可验证地评估鲁棒性声明的框架。我们还在多种声学噪声条件和测试集上,对常见视听语音识别架构的鲁棒性进行了系统性实证研究。最后,我们证明基于级联的架构无关解决方案能稳定实现视频缺失下的鲁棒性,甚至在dropout等现有鲁棒性技术失效的场景中依然有效。