
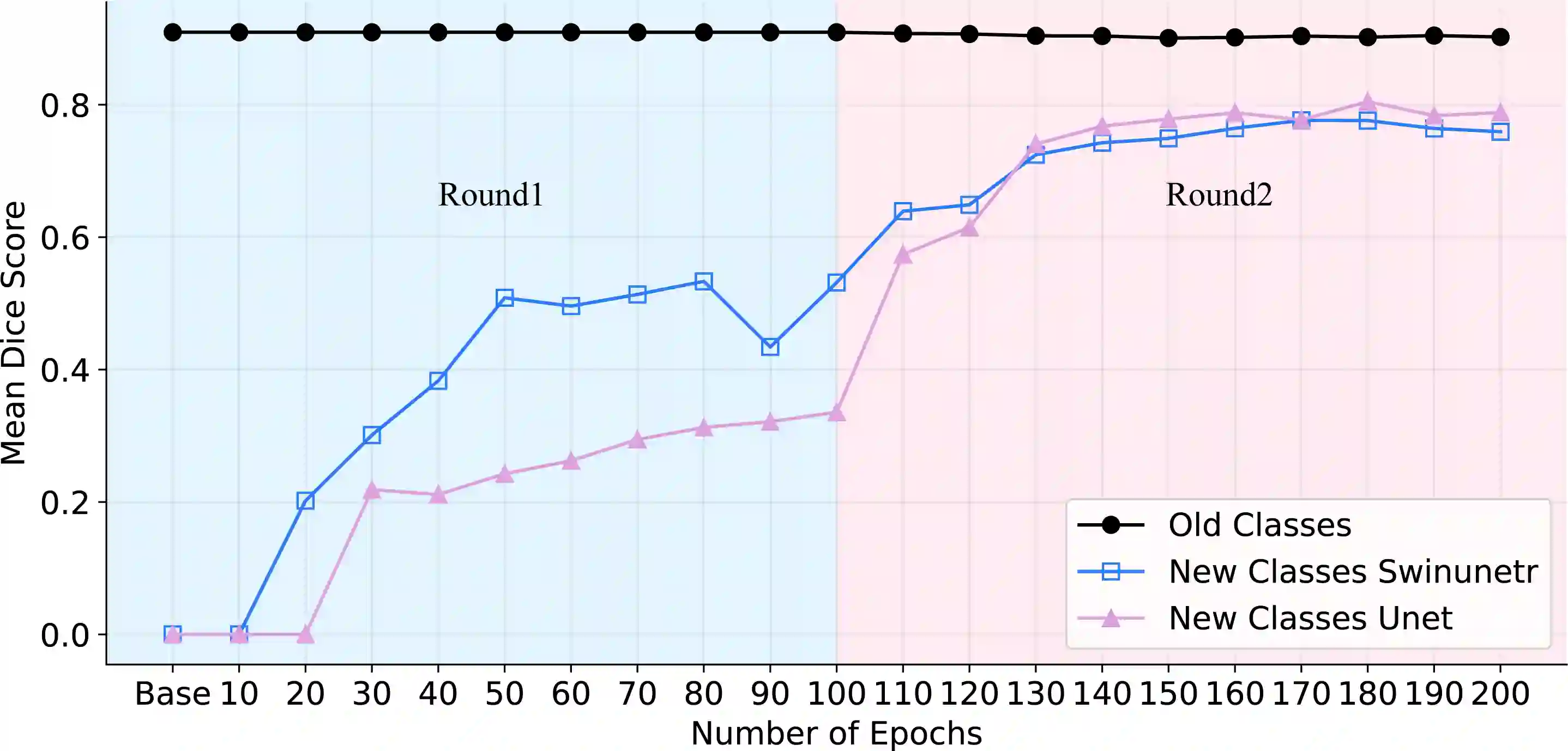
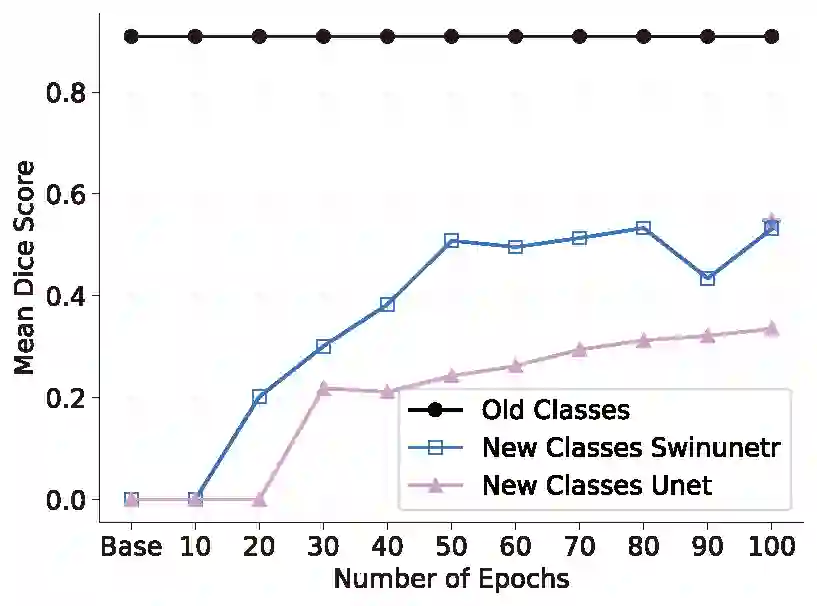
Interactive segmentation, an integration of AI algorithms and human expertise, premises to improve the accuracy and efficiency of curating large-scale, detailed-annotated datasets in healthcare. Human experts revise the annotations predicted by AI, and in turn, AI improves its predictions by learning from these revised annotations. This interactive process continues to enhance the quality of annotations until no major revision is needed from experts. The key challenge is how to leverage AI predicted and expert revised annotations to iteratively improve the AI. Two problems arise: (1) The risk of catastrophic forgetting--the AI tends to forget the previously learned classes if it is only retrained using the expert revised classes. (2) Computational inefficiency when retraining the AI using both AI predicted and expert revised annotations; moreover, given the dominant AI predicted annotations in the dataset, the contribution of newly revised annotations--often account for a very small fraction--to the AI training remains marginal. This paper proposes Continual Tuning to address the problems from two perspectives: network design and data reuse. Firstly, we design a shared network for all classes followed by class-specific networks dedicated to individual classes. To mitigate forgetting, we freeze the shared network for previously learned classes and only update the class-specific network for revised classes. Secondly, we reuse a small fraction of data with previous annotations to avoid over-computing. The selection of such data relies on the importance estimate of each data. The importance score is computed by combining the uncertainty and consistency of AI predictions. Our experiments demonstrate that Continual Tuning achieves a speed 16x greater than repeatedly training AI from scratch without compromising the performance.
翻译:交互式分割融合了人工智能算法与人类专业经验,旨在提升医疗领域大规模精细标注数据集的构建精度与效率。人类专家修正AI预测的标注,而AI则通过从这些修正标注中学习来优化预测结果。这种交互过程持续提升标注质量,直至专家无需进行重大修正。关键挑战在于如何利用AI预测标注与专家修正标注来迭代优化AI模型,其中存在两个核心问题:(1)灾难性遗忘风险——若仅使用专家修正的类别进行再训练,AI会遗忘先前学习过的类别;(2)计算效率低下——使用AI预测标注与专家修正标注联合再训练时,由于数据集中预测标注占主导地位,新修正标注(通常仅占极小比例)对模型训练的贡献微乎其微。本文提出持续调优方法,从网络架构与数据重用两个维度解决上述问题。首先设计共享网络处理所有类别,并附加面向特定类别的独立网络。为缓解遗忘问题,我们冻结先前学习类别的共享网络,仅更新修正类别的特定网络。其次,通过重用少量包含历史标注的数据来避免过度计算,这些数据的选择基于各数据重要度评估,其评分由AI预测的不确定性和一致性共同计算得出。实验表明,持续调优方法在保持同等性能的前提下,训练速度比从零开始重复训练AI提升16倍。

相关内容

Source: Apple - iOS 8


