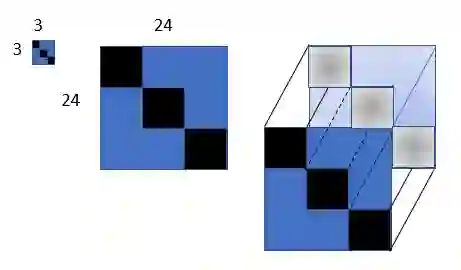
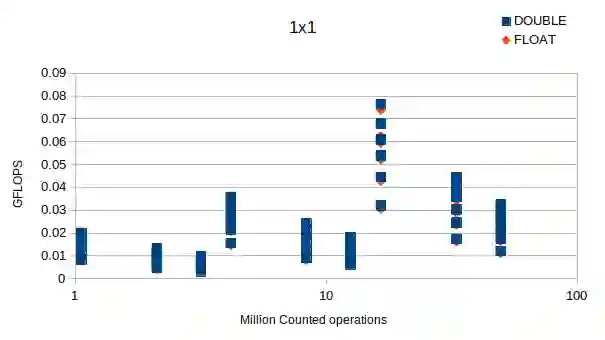
Nowadays, increasingly larger Deep Neural Networks (DNNs) are being developed, trained, and utilized. These networks require significant computational resources, putting a strain on both advanced and limited devices. Our solution is to implement {\em weight block sparsity}, which is a structured sparsity that is friendly to hardware. By zeroing certain sections of the convolution and fully connected layers parameters of pre-trained DNN models, we can efficiently speed up the DNN's inference process. This results in a smaller memory footprint, faster communication, and fewer operations. Our work presents a vertical system that allows for the training of convolution and matrix multiplication weights to exploit 8x8 block sparsity on a single GPU within a reasonable amount of time. Compilers recognize this sparsity and use it for both data compaction and computation splitting into threads. Blocks like these take full advantage of both spatial and temporal locality, paving the way for fast vector operations and memory reuse. By using this system on a Resnet50 model, we were able to reduce the weight by half with minimal accuracy loss, resulting in a two-times faster inference speed. We will present performance estimates using accurate and complete code generation for AIE2 configuration sets (AMD Versal FPGAs) with Resnet50, Inception V3, and VGG16 to demonstrate the necessary synergy between hardware overlay designs and software stacks for compiling and executing machine learning applications.
翻译:如今,深度神经网络(DNNs)的规模日益增大,其开发、训练与应用均需消耗大量计算资源,这对高端设备与资源受限设备均构成压力。我们的解决方案是实施权重块稀疏化,这是一种对硬件友好的结构化稀疏方法。通过对预训练DNN模型中卷积层和全连接层参数的特定部分进行置零处理,我们能够有效加速DNN的推理过程,从而实现更小的内存占用、更快的通信速度以及更少的运算量。本研究提出了一套垂直系统,可在单GPU上于合理时间内完成卷积与矩阵乘法权重的训练,以利用8x8块稀疏特性。编译器能够识别这种稀疏模式,并将其同时用于数据压缩和计算任务拆分为线程。此类块结构充分利用了空间局部性与时间局部性,为快速向量运算和内存复用铺平了道路。在Resnet50模型上应用本系统,我们成功将权重减少一半且精度损失极小,推理速度因此提升两倍。我们将通过为AIE2配置集(AMD Versal FPGAs)生成精确完整的代码,结合Resnet50、Inception V3和VGG16模型进行性能评估,以展示硬件覆盖设计与软件栈在编译和执行机器学习应用时所需的协同效应。