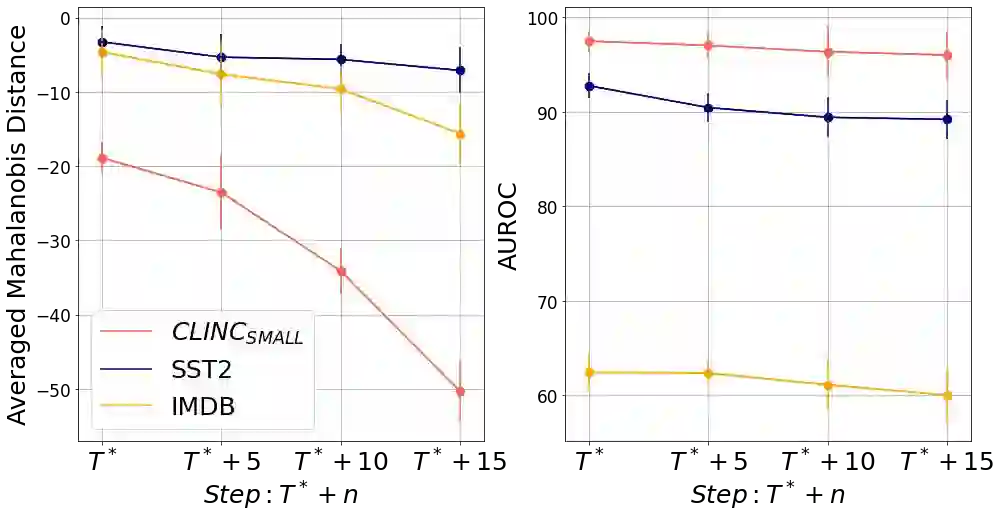
For real-world language applications, detecting an out-of-distribution (OOD) sample is helpful to alert users or reject such unreliable samples. However, modern over-parameterized language models often produce overconfident predictions for both in-distribution (ID) and OOD samples. In particular, language models suffer from OOD samples with a similar semantic representation to ID samples since these OOD samples lie near the ID manifold. A rejection network can be trained with ID and diverse outlier samples to detect test OOD samples, but explicitly collecting auxiliary OOD datasets brings an additional burden for data collection. In this paper, we propose a simple but effective method called Pseudo Outlier Exposure (POE) that constructs a surrogate OOD dataset by sequentially masking tokens related to ID classes. The surrogate OOD sample introduced by POE shows a similar representation to ID data, which is most effective in training a rejection network. Our method does not require any external OOD data and can be easily implemented within off-the-shelf Transformers. A comprehensive comparison with state-of-the-art algorithms demonstrates POE's competitiveness on several text classification benchmarks.
翻译:对于实际语言应用场景,检测分布外样本有助于警示用户或拒绝此类不可靠样本。然而,现代过参数化语言模型通常对分布内和分布外样本都产生过度自信的预测。特别地,语言模型在处理与分布内样本具有相似语义表征的分布外样本时表现不佳,因为这些分布外样本位于分布内流形附近。虽然可以通过使用分布内样本和多样化异常样本来训练拒绝网络以检测测试分布外样本,但显式收集辅助分布外数据集会带来额外的数据收集负担。本文提出一种简单有效的方法——伪异常暴露(POE),通过顺序遮蔽与分布内类别相关的词元来构建替代分布外数据集。POE引入的伪异常样本展现出与分布内数据相似的表征,这对训练拒绝网络最为有效。本方法无需任何外部分布外数据,且可便捷地在现成Transformer中实现。与现有最优算法的全面比较表明,POE在多个文本分类基准测试中具有竞争力。