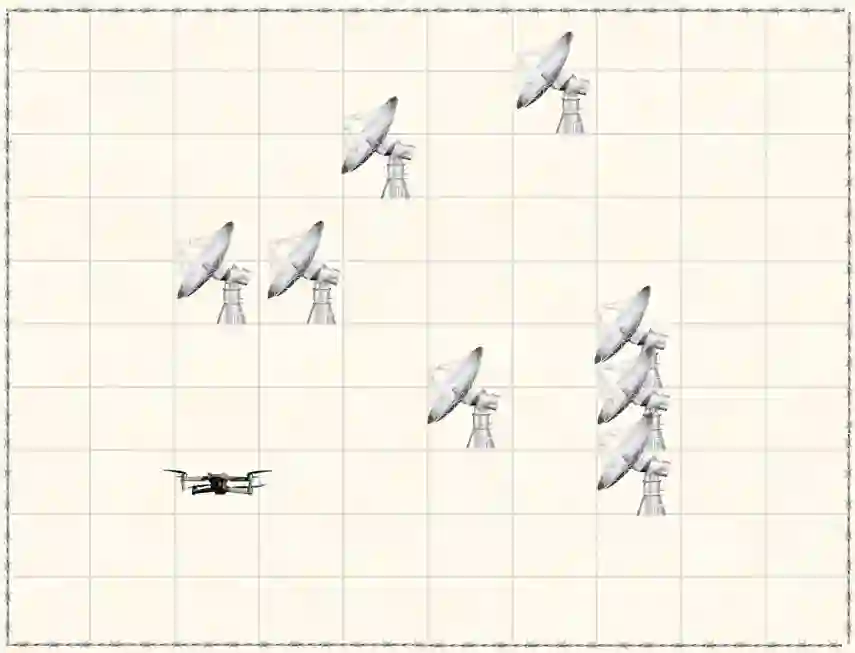
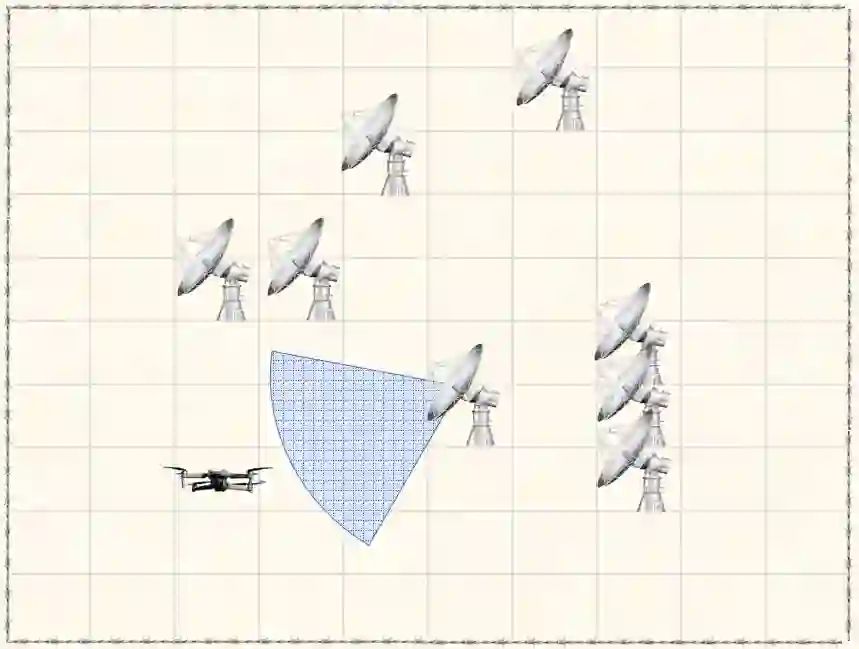
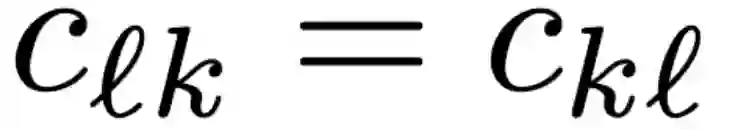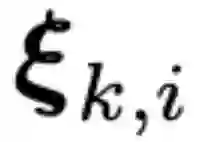Most works on multi-agent reinforcement learning focus on scenarios where the state of the environment is fully observable. In this work, we consider a cooperative policy evaluation task in which agents are not assumed to observe the environment state directly. Instead, agents can only have access to noisy observations and to belief vectors. It is well-known that finding global posterior distributions under multi-agent settings is generally NP-hard. As a remedy, we propose a fully decentralized belief forming strategy that relies on individual updates and on localized interactions over a communication network. In addition to the exchange of the beliefs, agents exploit the communication network by exchanging value function parameter estimates as well. We analytically show that the proposed strategy allows information to diffuse over the network, which in turn allows the agents' parameters to have a bounded difference with a centralized baseline. A multi-sensor target tracking application is considered in the simulations.
翻译:大多数多智能体强化学习研究侧重于环境状态完全可观测的场景。本文考虑一种合作式策略评估任务,其中智能体不直接观测环境状态,而仅能获取含噪观测值和信念向量。众所周知,在多智能体环境下求全局后验分布通常属于NP难问题。为此,我们提出一种完全分散的信念形成策略,该策略依赖个体更新和通信网络上的局部交互。除交换信念外,智能体还通过通信网络交换值函数参数估计值。我们通过理论分析表明,所提策略能使信息在网络中扩散,从而使智能体的参数与集中式基线保持有界差异。仿真实验中考虑了一种多传感器目标跟踪应用场景。