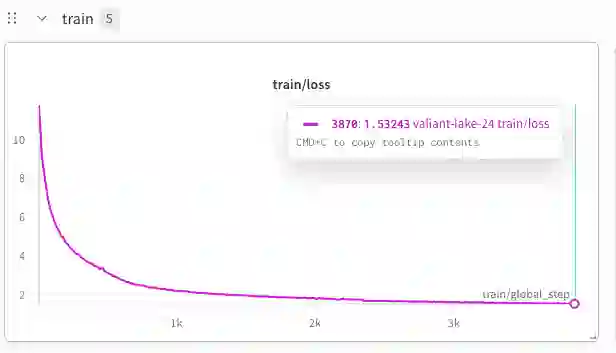
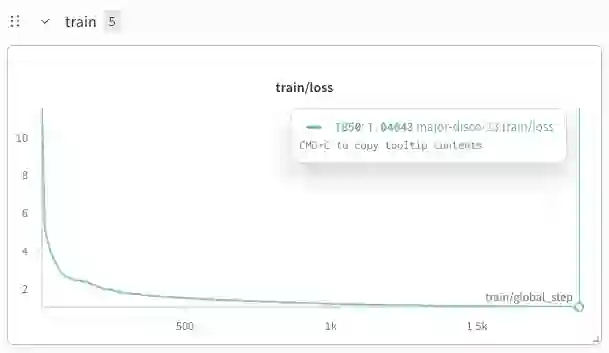
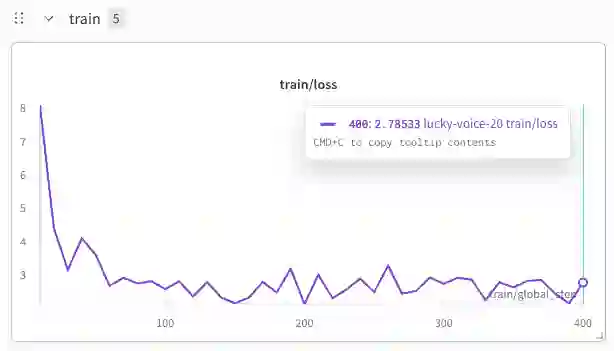
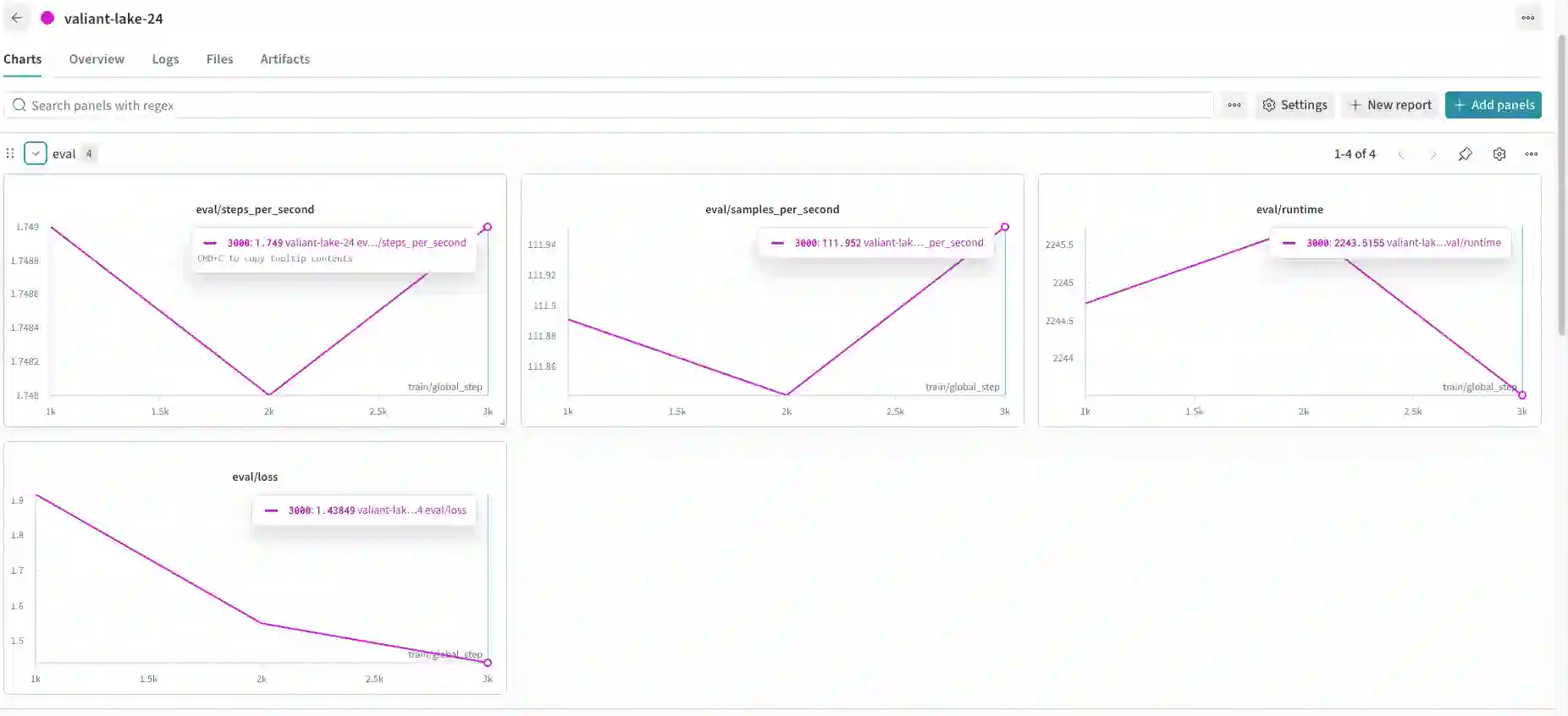
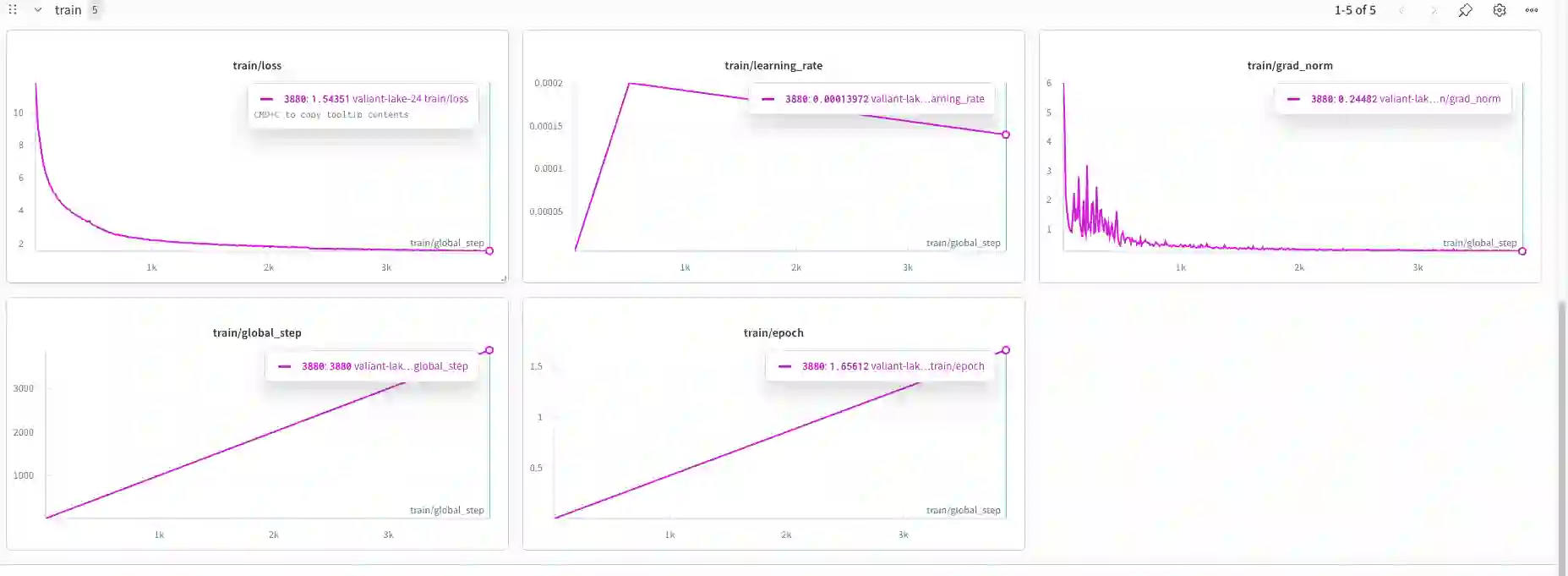
While frontier large language models demonstrate strong reasoning and mathematical capabilities, the practical process of training domain-specialized scientific language models from raw sources remains under-documented. In this work, we present a detailed case study of training a 1.36B-parameter scientific language model directly from raw arXiv LaTeX sources spanning mathematics, computer science, and theoretical physics. We describe an end-to-end pipeline covering metadata filtering, archive validation, LaTeX extraction, text normalization, domain-aware tokenization, and dense transformer training under constrained compute (2xA100 GPUs). Through 24 experimental runs, we analyze training stability, scaling behavior, data yield losses, and infrastructure bottlenecks. Our findings highlight how preprocessing decisions significantly affect usable token volume, how tokenization impacts symbolic stability, and how storage and I/O constraints can rival compute as limiting factors. We further analyze convergence dynamics and show stable training behavior in a data-rich regime (52B pretraining tokens). Rather than proposing a novel architecture, this work provides an engineering-grounded, transparent account of training a small scientific language model from scratch. We hope these insights support researchers operating under moderate compute budgets who seek to build domain-specialized models.
翻译:尽管前沿大语言模型展现出强大的推理与数学能力,但从原始资料训练领域专业化科学语言模型的实际过程仍缺乏充分记录。本研究通过详细案例,展示了直接基于涵盖数学、计算机科学与理论物理的原始arXiv LaTeX源码训练一个1.36B参数科学语言模型的全过程。我们描述了一个端到端流程,涵盖元数据过滤、归档验证、LaTeX提取、文本规范化、领域感知分词以及在有限算力(2×A100 GPU)下的稠密Transformer训练。通过24组实验运行,我们分析了训练稳定性、缩放行为、数据产出损耗及基础设施瓶颈。研究发现突出表明:预处理决策显著影响可用标记量,分词策略影响符号稳定性,存储与I/O限制可能成为与计算资源同等重要的制约因素。我们进一步分析了收敛动态,并展示了在数据充足场景(520亿预训练标记)下稳定的训练行为。本研究未提出新颖架构,而是提供了一份基于工程实践、透明公开的从小规模构建科学语言模型的完整训练记录。我们希望这些见解能为在中等算力预算下寻求构建领域专用模型的研究者提供支持。