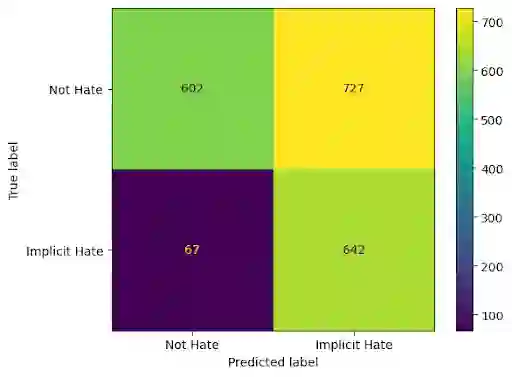
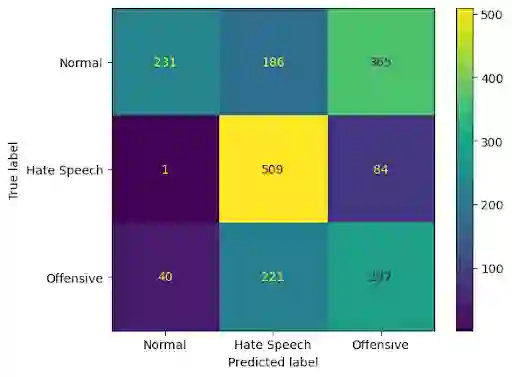
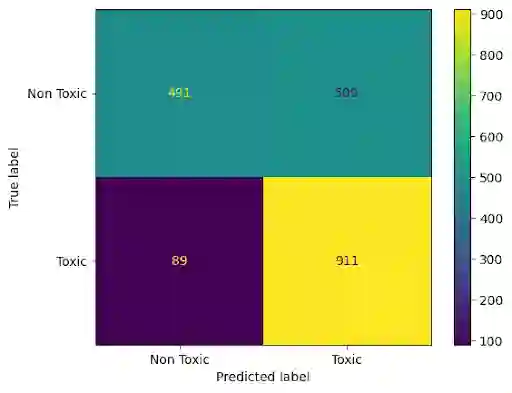
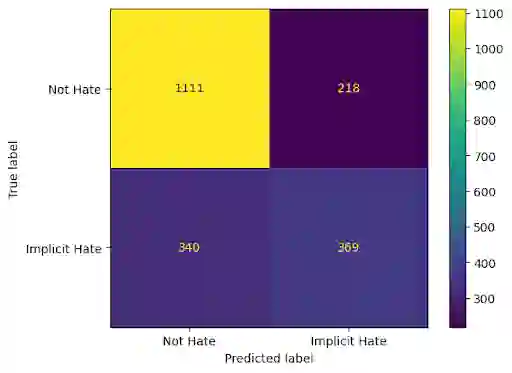
Recently efforts have been made by social media platforms as well as researchers to detect hateful or toxic language using large language models. However, none of these works aim to use explanation, additional context and victim community information in the detection process. We utilise different prompt variation, input information and evaluate large language models in zero shot setting (without adding any in-context examples). We select three large language models (GPT-3.5, text-davinci and Flan-T5) and three datasets - HateXplain, implicit hate and ToxicSpans. We find that on average including the target information in the pipeline improves the model performance substantially (~20-30%) over the baseline across the datasets. There is also a considerable effect of adding the rationales/explanations into the pipeline (~10-20%) over the baseline across the datasets. In addition, we further provide a typology of the error cases where these large language models fail to (i) classify and (ii) explain the reason for the decisions they take. Such vulnerable points automatically constitute 'jailbreak' prompts for these models and industry scale safeguard techniques need to be developed to make the models robust against such prompts.
翻译:近期,社交媒体平台及研究者已尝试利用大语言模型检测仇恨性或攻击性语言。然而,现有工作均未在检测过程中引入解释、额外语境及受害者社群信息。本研究通过设计不同提示变体、输入信息,并在零样本设定下(不添加任何上下文示例)评估大语言模型。我们选取了三种大语言模型(GPT-3.5、text-davinci 和 Flan-T5)及三个数据集——HateXplain、隐式仇恨数据集与 ToxicSpans。实验发现,在检测流程中加入目标信息后,模型性能较基线平均提升约20%-30%;在流程中融入理由/解释时,性能亦显著提升约10%-20%。此外,我们进一步提供了错误案例的类型学分析,揭示这些大语言模型在(i)分类任务及(ii)对其决策理由进行解释时的失效情形。此类脆弱点自动构成了针对这些模型的"越狱"提示,亟需开发工业级防护技术以增强模型对此类提示的鲁棒性。