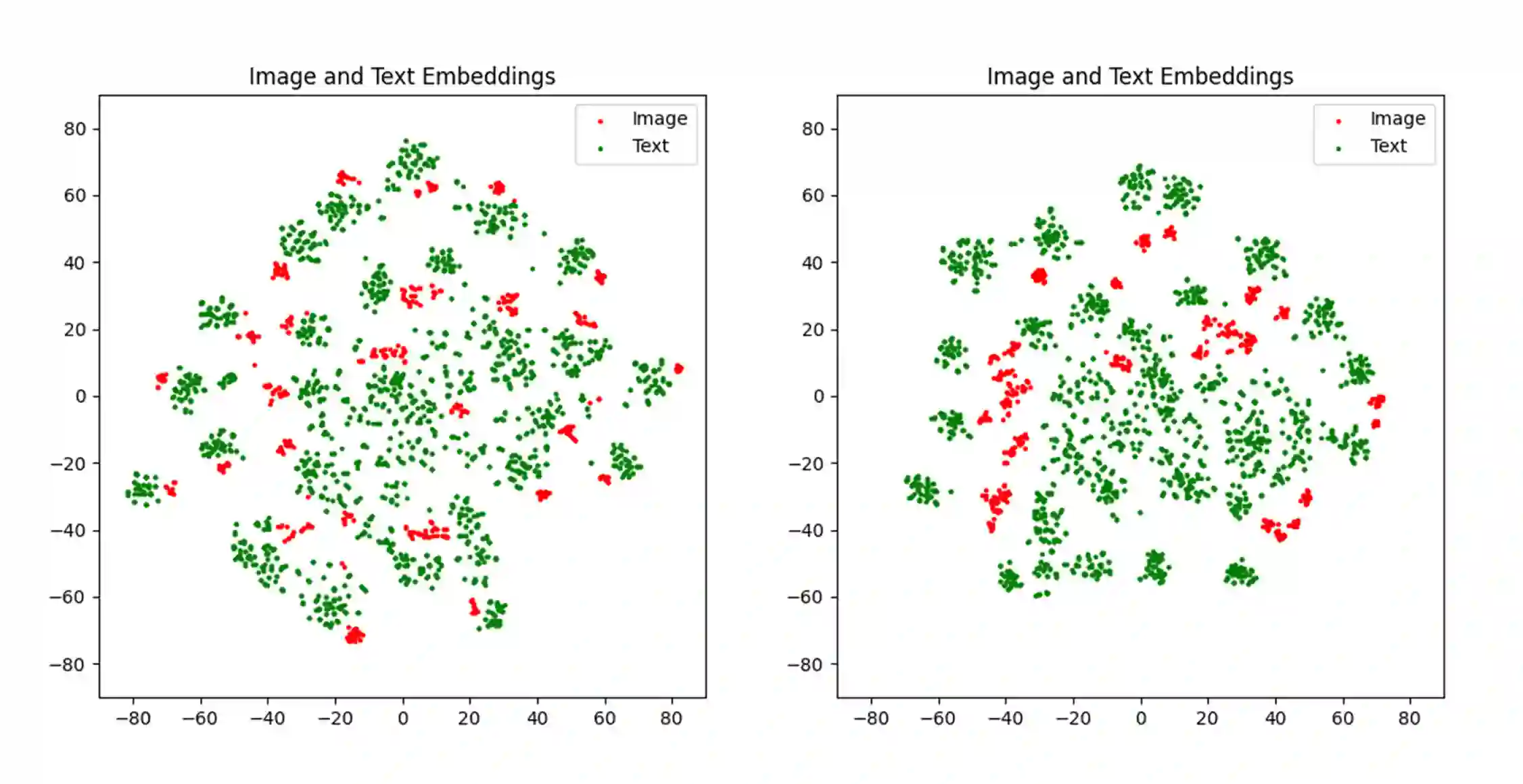
With the rise of Visual and Language Pretraining (VLP), an increasing number of downstream tasks are adopting the paradigm of pretraining followed by fine-tuning. Although this paradigm has demonstrated potential in various multimodal downstream tasks, its implementation in the remote sensing domain encounters some obstacles. Specifically, the tendency for same-modality embeddings to cluster together impedes efficient transfer learning. To tackle this issue, we review the aim of multimodal transfer learning for downstream tasks from a unified perspective, and rethink the optimization process based on three distinct objectives. We propose "Harmonized Transfer Learning and Modality Alignment (HarMA)", a method that simultaneously satisfies task constraints, modality alignment, and single-modality uniform alignment, while minimizing training overhead through parameter-efficient fine-tuning. Remarkably, without the need for external data for training, HarMA achieves state-of-the-art performance in two popular multimodal retrieval tasks in the field of remote sensing. Our experiments reveal that HarMA achieves competitive and even superior performance to fully fine-tuned models with only minimal adjustable parameters. Due to its simplicity, HarMA can be integrated into almost all existing multimodal pretraining models. We hope this method can facilitate the efficient application of large models to a wide range of downstream tasks while significantly reducing the resource consumption. Code is available at https://github.com/seekerhuang/HarMA.
翻译:随着视觉与语言预训练(VLP)的兴起,越来越多的下游任务开始采用预训练后微调的模式。尽管该范式已在多种多模态下游任务中展现出潜力,但其在遥感领域的应用仍面临一些障碍。具体而言,同模态嵌入倾向于聚集的现象阻碍了高效的迁移学习。为解决这一问题,我们从统一视角重新审视了多模态迁移学习在下游任务中的目标,并基于三个不同的优化目标重新思考了优化过程。我们提出了“协调迁移学习与模态对齐(HarMA)”方法,该方法能同时满足任务约束、模态对齐和单模态均匀对齐,并通过参数高效微调最小化训练开销。值得注意的是,在无需外部训练数据的情况下,HarMA在遥感领域的两个主流多模态检索任务中实现了最先进的性能。实验表明,HarMA仅需极少的可调参数,即可达到与全参数微调模型相当甚至更优的性能。由于其简洁性,HarMA几乎可以集成到所有现有的多模态预训练模型中。我们希望该方法能促进大模型在广泛下游任务中的高效应用,同时显著降低资源消耗。代码发布于 https://github.com/seekerhuang/HarMA。