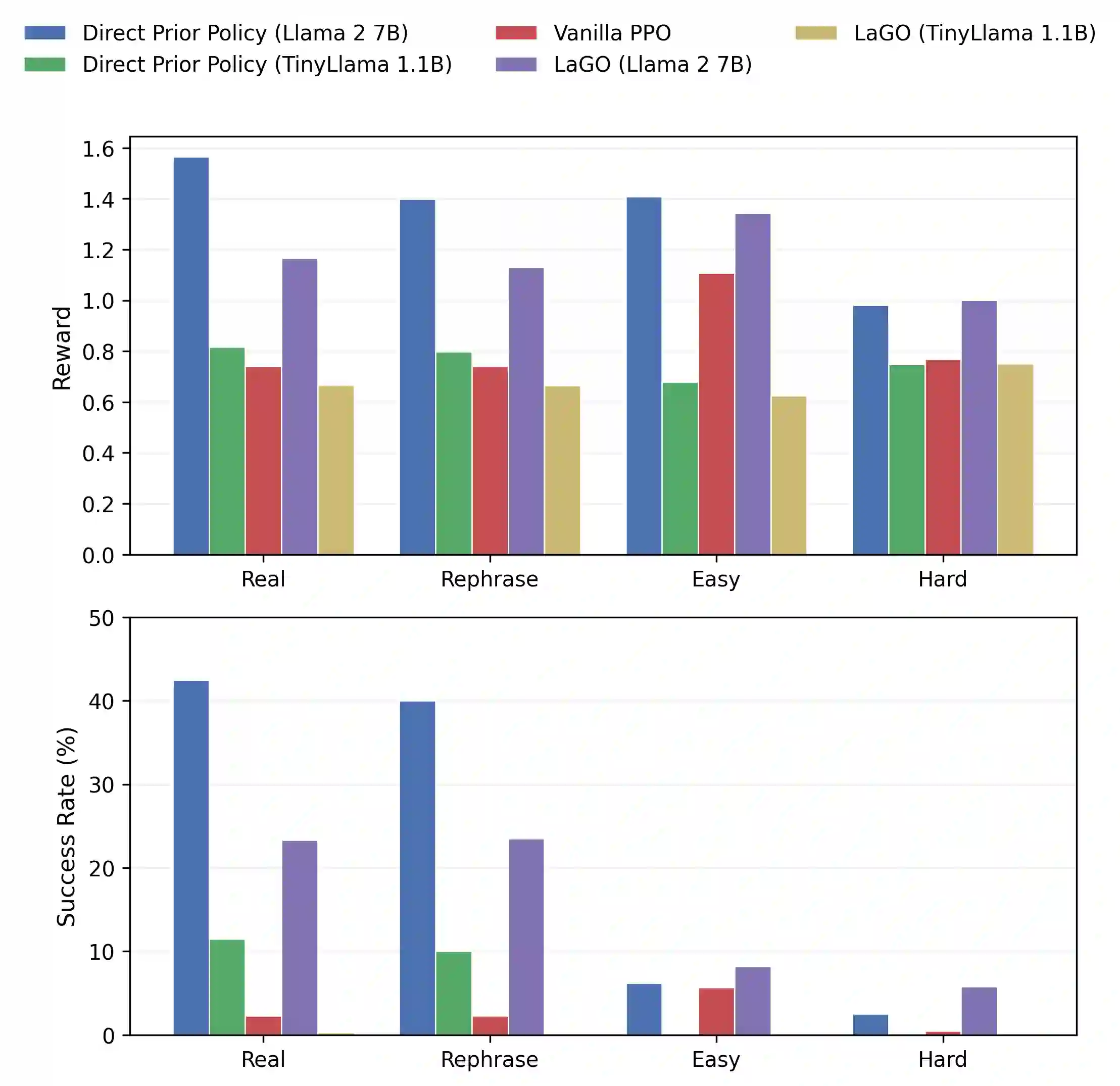
Large language models (LLMs) have shown strong potential for planning and sequential decision-making, but prior work often relies on using them as direct controllers, which requires precise action generation and can be unreliable in practice. This paper proposes Latent Action Guidance for Online Reinforcement Learning (LaGO), a framework that uses a pretrained LLM as a latent action prior to softly guide online policy optimization, rather than treating the LLM as an explicit planner or controller. Experiments on both a discrete-control benchmark, CLEVR-Robot, and a continuous-control benchmark, Meta-World, demonstrate that LaGO consistently improves both reward and success rate over Vanilla PPO. In particular, LaGO increases the average success rate from 15.1% to 27.2% on CLEVR-Robot and from 2.7% to 15.2% on Meta-World. Our analysis further shows that stronger pretrained LLMs provide more effective guidance, suggesting that LLM knowledge can improve planning and online decision-making.
翻译:暂无翻译