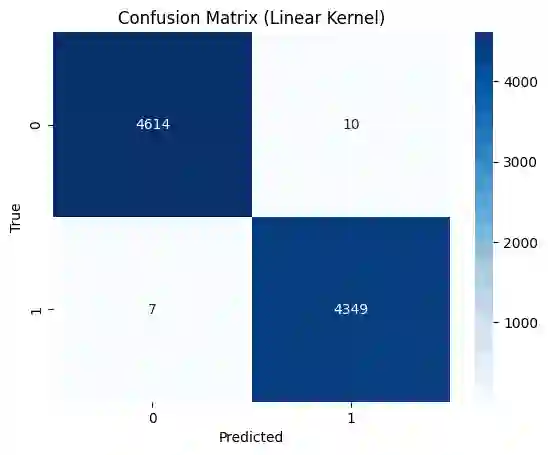
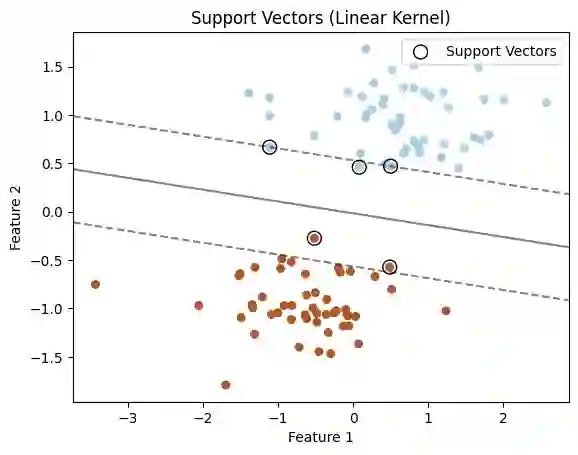
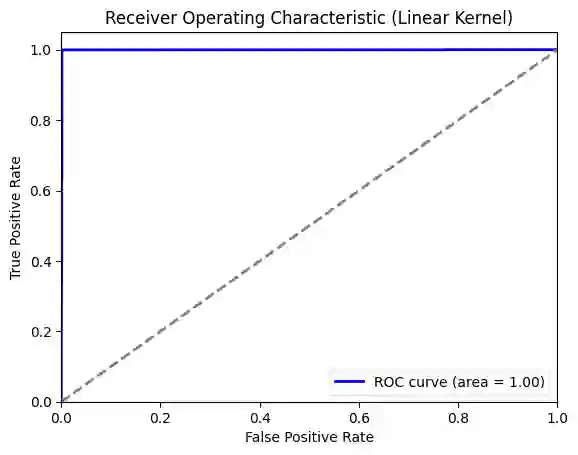
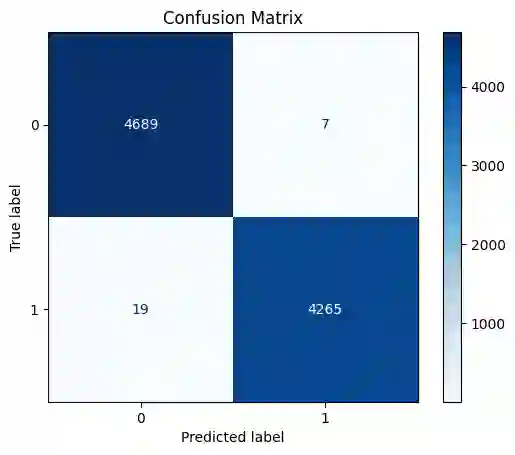
The rapid spread of misinformation, particularly through online platforms, underscores the urgent need for reliable detection systems. This study explores the utilization of machine learning and natural language processing, specifically Support Vector Machines (SVM) and BERT, to detect news that are fake. We employ three distinct text vectorization methods for SVM: Term Frequency Inverse Document Frequency (TF-IDF), Word2Vec, and Bag of Words (BoW) evaluating their effectiveness in distinguishing between genuine and fake news. Additionally, we compare these methods against the transformer large language model, BERT. Our comprehensive approach includes detailed preprocessing steps, rigorous model implementation, and thorough evaluation to determine the most effective techniques. The results demonstrate that while BERT achieves superior accuracy with 99.98% and an F1-score of 0.9998, the SVM model with a linear kernel and BoW vectorization also performs exceptionally well, achieving 99.81% accuracy and an F1-score of 0.9980. These findings highlight that, despite BERT's superior performance, SVM models with BoW and TF-IDF vectorization methods come remarkably close, offering highly competitive performance with the advantage of lower computational requirements.
翻译:在线平台中错误信息的迅速传播突显了对可靠检测系统的迫切需求。本研究探讨了利用机器学习与自然语言处理技术——特别是支持向量机(SVM)和BERT——来检测虚假新闻的方法。我们为SVM模型采用了三种不同的文本向量化方法:词频-逆文档频率(TF-IDF)、Word2Vec以及词袋模型(BoW),以评估它们在区分真实新闻与虚假新闻方面的有效性。此外,我们将这些方法与基于Transformer架构的大语言模型BERT进行了比较。我们的综合方法包括详细的预处理步骤、严格的模型实现以及全面的评估,以确定最有效的技术。结果表明,虽然BERT以99.98%的准确率和0.9998的F1分数取得了最优性能,但采用线性核函数与BoW向量化的SVM模型同样表现出色,达到了99.81%的准确率和0.9980的F1分数。这些发现强调,尽管BERT性能更优,但采用BoW和TF-IDF向量化方法的SVM模型表现极为接近,在提供高度竞争力的性能的同时,还具有计算需求更低的优势。