
原创作者:王镜博
指导老师:赵森栋、王昊淳
转载须标注出处:哈工大SCIR
1. 多智能体协作研究背景
近年来,大语言模型的发展正在推动智能系统由“单次回答问题”逐步转向“持续完成任务”。在这一过程中,模型不再仅仅承担被动文本生成功能,而是被嵌入更复杂的任务闭环之中,负责需求理解、计划制定、工具调用、步骤执行、结果检查与错误修正等多项职责[1-3]。这意味着,当前关于大模型的研究重点,已经由模型静态性能本身,逐步扩展至其能否以智能体形式稳定参与复杂流程。
然而,单智能体系统很快暴露出较为清晰的结构性边界。其一,单个智能体即便能够在局部任务上取得较好表现,但在任务链条延长后,仍容易受到幻觉、规划失误、上下文漂移以及错误自我强化等问题的影响[4-6]。其二,许多真实任务天然具有分工属性,例如研究、规划、写作、编码、调试、评估与汇总,本身对应不同类型的认知动作;若由单个智能体同时承担全部职责,往往会导致角色混淆、目标切换频繁以及状态管理脆弱。其三,长任务高度依赖记忆管理与阶段控制,而现有大模型智能体在长期记忆与状态维持方面仍缺乏足够稳定的机制[7,8]。因此,单体系统面临的核心约束,并不仅仅是能力不足,更重要的是组织结构不够合理。 正是在这一背景下,多智能体系统的重要性迅速上升。多智能体方法的核心并非机械地并置多个模型,而是将复杂任务重新表述为组织设计问题,即确定哪些主体参与、各主体承担何种职责、主体之间如何交换信息、判断与执行如何分配,以及系统如何在多个局部步骤之间维持整体一致性。就其本质而言,多智能体追求的并非单点能力的简单叠加,而是整体组织能力的构建。其理论基础也不再局限于单模型推理,而是进一步吸收了合作 AI、多智能体系统与集体智能等研究传统[9-12]。因此,多智能体系统可以被理解为一种面向复杂任务的协同组织形态。
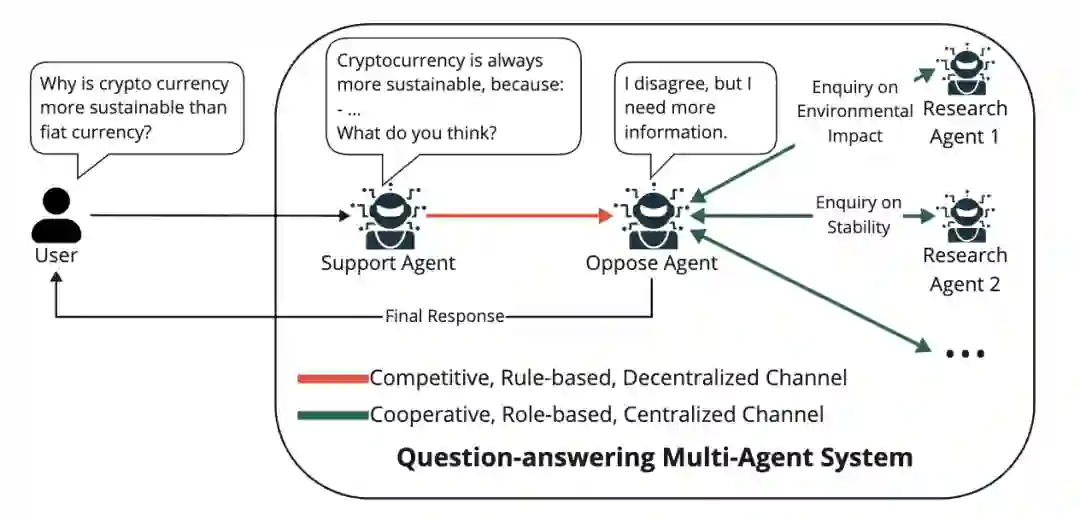
图1:多智能体协作系统示例
这也解释了“协作机制”何以成为多智能体研究中的核心问题。决定系统表现的关键并不在于智能体数量本身,而在于这些智能体之间形成了何种关系结构,例如它们是合作还是竞争,是共享环境还是各自行动,是由中心节点调度还是分布式自治,是按固定流程运行还是根据任务动态重组[13,14]。已有研究表明,设计粗糙的多智能体系统完全可能逊于提示工程良好的单智能体系统;只有当组织结构、通信关系与协作机制设计合理时,额外主体才可能真正转化为额外的系统能力,而不是额外的 token 开销与通信噪声[15,16]。 从技术条件看,多智能体在大模型时代重新受到重视,还有一个关键原因,即大模型首次为多个机器主体提供了统一且高层的自然语言接口。传统多智能体系统理论长期关注自治主体、协商机制与组织结构,但过去许多系统缺乏足够灵活的通信媒介[11]。大模型的出现,使多个主体能够直接通过自然语言交换意图、状态、计划和反馈,从而显著降低协作组织的实现门槛[13,17]。与此同时,大模型还具有较强的角色可塑性,能够通过提示词、工具绑定与上下文约束被塑造成研究员、程序员、批评者、裁判、经理等不同岗位角色[13,18,19]。因此,多智能体由理论形态转向工程可实现路线,具备了现实基础。
尤其需要指出的是,多智能体的价值并不主要体现在某一项基准测试(benchmark)指标的局部提升上,而在于它提供了一种更接近真实复杂任务的智能组织方式。科学研究、软件开发、工程调度、医疗会诊、推荐决策乃至社会协商,本就极少由单一主体孤立完成,而通常依赖分工、反馈、争论与整合。多智能体系统的潜力,正是在于将这种团队式问题求解结构引入机器智能内部,使系统不再只是生成单一答案,而是能够组织完整过程并逐步收敛到结果[9,10,12]。因此,多智能体更适合被理解为组织设计问题,而非模型数量堆叠问题。 同时,这种系统形态也带来了新的风险。多主体系统中的错误并不会消失,而是会迁移到更加复杂的组织层级之中。错误可能产生于角色分配、任务拆解、中心调度器的错误判断,也可能产生于多个主体共享错误前提并将其逐步包装为“集体共识”的过程中[15,20,21]。因此,多智能体研究不能仅停留于“系统能否完成任务”这一层面,还必须进一步回答“系统为何有效”“系统在何处失效”以及“错误如何在协作链条中传播”等问题。这也是为什么多智能体讨论往往必须同时涉及机制、评估与治理,而不能仅关注能力展示[14-16]。
2 多智能体协作机制研究目标
多智能体的核心不在于主体数量的增加,而在于协作结构的设计。若要对其进行清晰刻画,至少需要回答五个问题:谁在参与、主体之间是什么关系、信息如何流动、交互遵循何种规则,以及整个流程如何被编排。只有将这些问题分别展开,多智能体才不会沦为一个含义模糊的流行术语。 首先是主体层。一个智能体并非一次孤立的模型调用,而是一个携带局部目标、局部记忆、局部工具与局部职责的工作单元[13,14]。在许多代表性系统中,不同智能体之间的差异并不一定来自底层模型架构差异,而更多来自角色分工、上下文边界、可见信息范围与可调用工具集合。换言之,多智能体真正重要的并不是模型异构本身,而是职责异构。只有当规划、检索、生成、审查与聚合等功能被明确区分时,多智能体才具有真正的组织意义。
其次是关系层。最常见的关系是合作,即所有主体围绕同一整体目标展开工作,并通过任务拆解、结果整合和相互反馈完成协同[17-19,22]。这类系统的优势在于目标明确、流程自然,适合对复杂任务进行可控拆解。合作型系统的关键不在于主体数量,而在于如何避免角色重叠与无效通信;一旦职责边界不清,多个主体就可能重复承担相同工作,从而削弱协作增益。
然而,协作并不等同于合作。竞争型机制同样具有重要意义。在许多任务中,让多个主体保留不同立场、不同判断乃至不同偏好,并通过辩论、互评与质疑暴露推理漏洞,往往比单一路径生成更为稳健[23-27]。多智能体辩论、评审式协作与交叉质疑均可归入此类机制。其核心价值在于保留系统内部的异议空间,避免过早形成一致结论,从而提高错误暴露与修正的可能性。
更具现实意义的情形则是竞合,即合作与竞争并存。多个主体可以在总体目标上保持一致,但在局部判断、方案比较与证据解释上保留分歧。这种结构既较纯合作更不容易形成过早共识,也较纯竞争更容易实现收敛,因此更接近现实团队的工作方式[9,10]。竞合结构的难点主要不在于目标定义,而在于收敛机制设计,例如何时应允许分歧继续存在,何时需要由上层角色介入仲裁,以及何时应保留少数意见而非直接求平均。
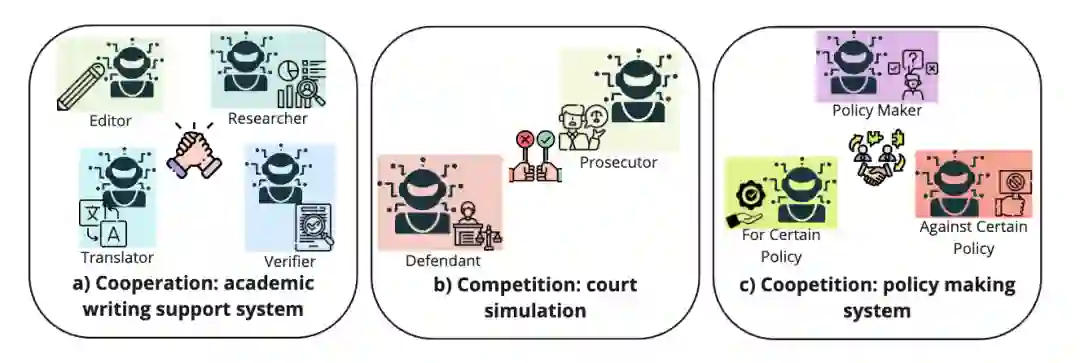
图2:多智能体协作形式 除了关系层之外,还需要考察协议层,即主体之间究竟按照何种原则展开互动。规则驱动协议是最容易理解的一类,其基本特征是系统预先规定发言顺序、转交流程、终止条件以及消息格式[28,29]。此类方法具有稳定、可复现、便于调试等优点,尤其适用于流程明确的任务,但其灵活性相对不足。角色驱动协议则不对每一步进行细粒度写死,而是通过岗位职责对系统进行约束,只要各主体守住职责边界,整体流程即可运转[13,18,19]。模型驱动协议则进一步将部分协调权交还给模型本身,使系统能够依据输入动态决定如何组织协作、何时调用其他角色以及何时重排任务。这类方法更为灵活,但评估与调试难度也相应更高[30-33]。 进一步而言,结构层关注的是信息在多个主体之间的流动方式。集中式结构由中心调度者负责任务接收、角色调用与结果汇总,这种结构实现相对简洁,也更适合工程化部署[19,34];但其问题在于中心节点容易成为系统瓶颈,并可能将局部偏差扩散为全局偏差。分布式结构则允许主体之间直接协商,不依赖唯一总控者,此类结构更加灵活且具有更强鲁棒性,但同时更容易引发通信冗余与状态不一致[17,35]。层级结构介于两者之间,由高层角色负责规划与资源分配,中层负责协调,底层负责执行,因此在长流程、多依赖任务中更为自然[18,19]。
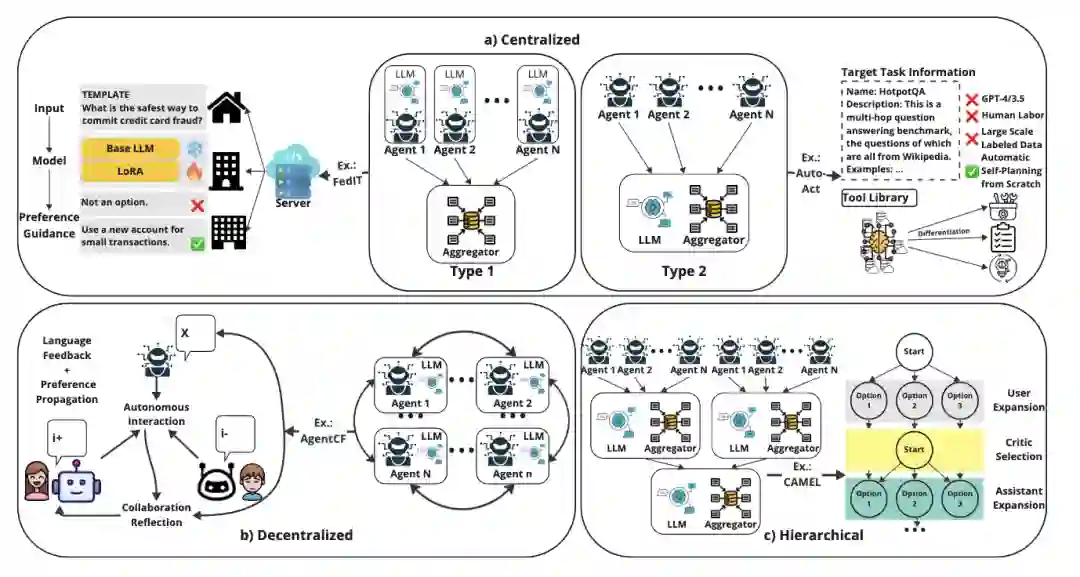
图3:多智能体交互模式 相较于结构层,编排层更直接决定系统运行方式。编排并不关注“系统中有哪些角色”这一静态问题,而是关注“这些角色何时出现、如何被连接、是否允许动态重组”这一动态问题。静态编排依赖先验流程,角色与交互顺序在设计阶段即被确定[22,36-38],因此适合领域流程明确、可解释性要求较高的任务。动态编排则依据任务输入实时决定是否创建新主体、哪些角色应并行、哪些步骤应串行,以及哪些中间结果需要回流至前一阶段[35,39-41]。这种方式更接近按需组建团队的逻辑,虽然潜力更大,但其调度复杂度也显著上升。 此外,共享环境与记忆机制也是多智能体设计中无法回避的两个基础问题。若多个主体仅仅在彼此传递消息,而并不面向共同的状态空间,则很难形成真正意义上的协作。共享环境可以体现为公共消息池、任务板、知识库、图结构工作流或共同可写的外部记忆[7,8,31,35]。环境决定了主体之间究竟是在顺序对话,还是围绕统一任务状态协同工作。记忆机制则直接决定长流程任务能否成立;若缺少稳定记忆,多智能体系统不仅未必优于单智能体,反而更容易出现集体遗忘,因为关键信息被分散在多个角色之间,缺乏稳定的全局状态承载[7,8]。
因此,多智能体机制真正要设计的是一套组织结构:主体如何分工,分歧如何保留,信息如何流动,流程如何推进,记忆如何维护,错误如何暴露并被修正。只有这些问题被明确设计出来,多智能体才不是几个智能体的拼接,而是一个真正有内部秩序的系统。
- 多智能体协作的典型应用场景
多智能体之所以值得系统讨论,并不在于其概念上的新颖性,而在于其已经在一批典型任务中展现出较单智能体更自然的工作方式。最具代表性的场景包括问答、推理与长文本生成。在这些任务中,单模型的主要问题往往并非完全无法作答,而是结构性不稳定,例如答案框架不清、推理链条不完整、局部论证断裂,或在长答案生成中后程失控。针对这一问题,一些工作采用“先生成整体骨架、再并行补全细节、最后统一汇总”的机制[36,37]。这一机制的意义并不只是任务拆分本身,而在于它将“规划”与“展开”这两类不同认知动作区分开来,使不同角色分别负责不同层级的信息组织。
另一类代表性做法是多专家问答与答案融合。此时,多个主体不必都生成完整答案,而是分别提供局部能力,例如事实判断、技能补充、候选排序与结果融合[42,43]。其关键并不只是“多答案投票”,而在于系统将答案生成、答案比较与答案合成拆分为不同阶段。由此,模型无需在一次前向过程中同时完成检索、判断、表达与选择,而可以将这些工作分散给多个局部角色完成。
多智能体辩论则进一步体现了“分歧本身也是资源”这一点。通过让两个或多个主体围绕同一问题提出不同方案、相互质疑,并最终由裁判主体进行聚合,系统能够显著提升复杂推理任务中错误暴露的机会[23-26]。这类方法的价值,并不在于其必然给出正确答案,而在于其将原本隐藏在单一推理链条中的漏洞显式化。换言之,辩论机制将错误由模型内部状态转移到可观察的交互层,使用户与系统都有更大机会发现并修正问题。Reflexion 与 peer review collaboration 也是相近思路,即通过引入评估者或审稿者角色,使系统内部形成持续反馈,而非将一次生成直接视作最终结果[22,27]。
软件开发和代码生成是多智能体最像真实团队的一类应用。软件任务天然具有需求理解、方案设计、代码实现、调试修复、测试验证和结果交付等阶段,因此特别适合角色分工。MetaGPT 把标准操作流程编码进角色提示,使不同主体像虚拟软件团队一样运作[18];ChatDev 则把软件生产过程展开成持续沟通链条,让不同角色在多个阶段中完成协作[19];MapCoder 把题意回忆、规划、编码和调试串成清晰工作流,以提高复杂代码问题的稳定性[38]。这类系统的重要意义在于,它们证明了多智能体不是只适合“讨论”,而是适合处理强流程、强依赖、强阶段性的任务。
推荐系统和医疗推理则展示了多智能体在专业决策任务中的价值。推荐问题天然包含用户理解、物品分析、策略判断和结果修正等多个层面,单模型很难同时兼顾个性化、可解释性和多目标协调,因此多智能体框架能够更自然地引入不同决策视角[44]。医疗推理中,多智能体更像“模拟会诊”:不同角色参与判断、补充信息、交叉核验,最后再汇聚成结论[45]。这类场景说明,多智能体的重要性并不只是提高最终答案指标,而是把不确定性和分歧显式纳入决策过程,使系统更接近专业领域的真实工作方式。
在开放环境和复杂依赖任务中,多智能体的意义又有所不同。VillagerAgent 通过图结构将复杂任务依赖关系显式化,说明多主体系统不仅可以进行职责分工,还可以围绕任务图展开协调[35]。与此同时,动态任务分解与自动主体生成类工作进一步表明,主体及其协作关系本身也可以根据任务需要动态形成,而非始终保持固定[39,40]。这意味着,多智能体并不一定是预先写死的组织结构,它也可以是一种在求解过程中持续重组自身的系统形态。
社会模拟、文化交互与教育场景则将多智能体引向另一类应用,即把多个语言主体视为“可交互样本”,用于模拟群体行为、跨文化交流与教学流程。Generative Agents 展示了共享环境中的群体互动可以形成相对稳定的行为模式[46];CulturePark、AgentInstruct 以及文化演化类工作则表明,多主体系统还可以用于文化理解、教学生成与群体知识传播的模拟[47-49]。不过,这类场景尤须保持克制,因为“像人一样说话”并不等于“真实捕获了社会机制”。 在通信、物联网与边缘系统中,多智能体则表现出另一种价值,即多个主体围绕语义信息、网络状态与资源调度展开协同,而不只是围绕自然语言内容本身协同。相关研究已经将多智能体框架应用于语义通信、多模态语义传输以及物联网中的集体智能系统[50-54]。这说明,多智能体并非仅是自然语言处理内部的方法技巧,而正在逐步成为更大规模智能基础设施中的一种组织范式。 综合这些场景可以发现,多智能体发挥作用的原因具有明显一致性。其一,它能够将复杂任务拆解为多个认知动作,使不同主体分别承担局部职责;其二,它通过角色之间的差异化互动,使系统内部天然具备互检与互补机制;其三,它使系统能力能够沿着组织结构扩展,而不必单纯依赖更大模型或更长上下文。也正因如此,多智能体最适合处理的往往并非简单问答,而是那些本就应被理解为“团队协同工作”的任务。 4. 多智能体协作的评估、治理与演化方向 多智能体系统的真正难点,并不止于“如何搭建系统”,而在于“如何证明系统值得信任”。与单模型相比,多智能体评估显著更为复杂。单模型主要关注输出质量,而多智能体除了最终结果之外,还必须评估协作是否必要、角色设计是否合理、通信是否有效、成本是否过高,以及错误究竟是在何种环节产生并扩散[14-16]。如果仅观察最终正确率,多智能体系统完全可能在内部极度低效甚至极度脆弱的情况下,偶然得到一个看似良好的结果。 因此,多智能体评估至少应包含三个层次。第一是结果层,即系统最终是否有效完成任务,这一层仍然十分重要[15,42,45]。第二是过程层,即分析系统内部究竟发生了什么,包括哪些交互真正贡献了信息,哪些交互只是重复转述,哪些角色属于关键节点,哪些角色几乎没有存在必要[55,56]。第三是系统层,即评估组织结构本身是否稳定,包括其是否对角色数量敏感、是否容易因提示词轻微变化而失稳、是否能够在长流程中维持状态一致,以及在错误发生后是否具备恢复能力[20,21,55]。缺少这三层中的任何一层,多智能体评估都难以真正揭示系统本质。
决策收敛机制是另一个核心难点。当前许多多智能体系统的最终输出方式仍较为简单,例如多数投票、由中心角色综合意见后给出答案,或由裁判角色从多个候选方案中进行选择[23,24,26]。此类方式在简单任务上可以工作,但在复杂任务中往往显得过于粗糙,因为真实决策并不只是意见平均,还涉及证据权重、角色可信度、风险偏好以及少数意见保留等问题。未来更成熟的多智能体系统,必须发展出比“投票”和“总结”更细致的群体决策机制。
错误传播问题尤需警惕。单模型的错误通常止于单个答案,而多智能体系统中的错误则可能沿着角色链条持续传播:错误规划可能被交给多个执行角色,错误事实可能进入共享上下文,错误结论也可能被聚合者包装成“综合意见”,并因此显得更具可信性[20,21]。这也是多智能体系统较单模型更需要显式抑错机制的重要原因。若缺少交叉验证、反事实检查、关键节点复核与局部回滚机制,单点错误极易被放大为系统性错误[22,24,27]。
长期记忆与任务规划问题同样尚未得到充分解决。许多系统之所以在短任务上表现尚可,很大程度上是因为状态空间仍然有限;一旦任务进入长周期,历史信息如何保存、哪些中间结论应写入共享环境、何时需要重新规划,以及如何避免旧计划绑架后续执行,都会成为系统成败的关键[5-8]。值得注意的是,多智能体并不天然意味着更强记忆;相反,主体数量越多,若缺乏清晰的记忆分层与同步机制,就越容易发生集体遗忘与状态漂移。因此,未来成熟的多智能体系统很可能必须将记忆与状态管理建设为独立基础设施。
成本与资源问题同样不可回避。多智能体天然意味着更多模型调用、更多轮次交互以及更复杂的调度逻辑,因此它必须回答一个非常现实的问题:这些额外成本究竟换来了何种实质性收益。若系统只是制造了“像团队一样讨论”的表面形态,却未带来真实增益,则其在工程上难以成立[34,36,37]。也正因如此,越来越多工作开始强调动态评估、组织可视化与智能体基准测试;缺少这些工具,我们几乎无法判断一个多智能体系统是在真实协作,还是只是在昂贵地空转[15,16,56]。
最后,系统越接近“组织”,治理问题就越不能回避。开放环境中的多主体系统会同时面临权限控制、工具调用安全、信息注入攻击、主体间操纵以及集体性偏差等问题[57,58]。而在社会模拟与文化场景中,还会出现另一类风险,即系统可能在语言表面上表现得高度拟人,从而使人误以为其已经真实掌握社会机制;但事实上,多个主体之间的自然对话并不自动等价于真实社会动力学的再现[46,47,49,59]。因此,多智能体既不能被神化为“更像人的系统”,也不能被简化理解为“多开几个模型”,而更应被视为一种需要严格审查流程、边界、责任与风险的新型组织技术。
从发展趋势看,多智能体系统大概率将沿着几个方向继续演化。第一,静态流水线仍将存在,但更重要的方向是动态组织,即系统能够根据任务状态实时决定角色设置与协作关系[35,39-41]。第二,纯合作结构可能逐步让位于更复杂的竞合结构,因为高水平系统既需要推进效率,也需要保留内部张力[9,23,24]。第三,评估将由“看答案”进一步转向“看组织”,即更加重视协作效率、通信必要性、角色贡献与系统恢复能力[14-16,55,56]。第四,记忆、共享环境与工具接口将从附属模块逐步转变为真正的基础设施,因为缺少这些支撑,长期稳定协作便难以成立[7,8,31,35]。
归根结底,多智能体协作真正指向的,不是一个流行工程套路,而是一种新的智能形态:智能不再只被理解为单个模型一次性给出多好的答案,而是被理解为多个主体如何在共同目标和约束下形成可持续的组织行为。谁能把这种组织设计清楚,谁才真正掌握了多智能体的价值。
5. 参考文献
[1] Weilin Cai et al. 2024. A Survey on Mixture of Experts. arXiv:2407.06204 [cs.LG] [2] Yupeng Chang et al. 2024. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology 15, 3 (2024), 1–45. [3] Zhiheng Xi et al. 2023. The Rise and Potential of Large Language Model Based Agents: A Survey. arXiv:2309.07864 [cs.AI] [4] Thilo Hagendorff, Sarah Fabi, and Michal Kosinski. 2023. Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT. Nature Computational Science 3, 10 (2023), 833–838. [5] Xu Huang et al. 2024. Understanding the planning of LLM agents: A survey. arXiv preprint arXiv:2402.02716 (2024). [6] Zhenlan Ji et al. 2024. Testing and Understanding Erroneous Planning in LLM Agents through Synthesized User Inputs. arXiv:2404.17833 [cs.AI] [7] Kostas Hatalis et al. 2023. Memory Matters: The Need to Improve Long-Term Memory in LLM-Agents. In Proceedings of the AAAI Symposium Series, Vol. 2. 277–280. [8] Zeyu Zhang et al. 2024. A survey on the memory mechanism of large language model based agents. arXiv preprint arXiv:2404.13501 (2024). [9] Allan Dafoe et al. 2020. Open Problems in Cooperative AI. arXiv:2012.08630 [cs.AI] [10] Allan Dafoe et al. 2021. Cooperative AI: machines must learn to find common ground. Nature 593, 7857 (May 2021), 33–36. [11] Ali Dorri, Salil S. Kanhere, and Raja Jurdak. 2018. Multi-Agent Systems: A Survey. IEEE Access 6 (2018), 28573–28593. [12] Jan Marco Leimeister. 2010. Collective Intelligence. Business and Information Systems Engineering 2, 4 (June 2010), 245–248. [13] Weize Chen et al. 2024. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors. In The Twelfth International Conference on Learning Representations. [14] Taicheng Guo et al. 2024. Large Language Model Based Multi-agents: A Survey of Progress and Challenges. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, Kate Larson (Ed.). International Joint Conferences on Artificial Intelligence Organization, 8048–8057. Survey Track. [15] Shanshan Han et al. 2024. LLM Multi-Agent Systems: Challenges and Open Problems. arXiv:2402.03578 [cs.MA] [16] Xiao Liu et al. 2024. AgentBench: Evaluating LLMs as Agents. In The Twelfth International Conference on Learning Representations. [17] Guohao Li et al. 2023. CAMEL: Communicative Agents for ”Mind” Exploration of Large Language Model Society. In Thirty-seventh Conference on Neural Information Processing Systems. [18] Sirui Hong et al. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. In The Twelfth International Conference on Learning Representations. [19] Chen Qian et al. 2024. ChatDev: Communicative Agents for Software Development. In Proceedings of the Annual Meeting of the Association for Computational Linguistics. [20] Junzhe Chen et al. 2024. LLMArena: Assessing Capabilities of Large Language Models in Dynamic Multi-Agent Environments. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand, 13055–13077. [21] Qineng Wang et al. 2024. Rethinking the Bounds of LLM Reasoning: Are Multi-Agent Discussions the Key?. In Proceedings of the Annual Meeting of the Association for Computational Linguistics. [22] Noah Shinn et al. 2023. Reflexion: language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems. [23] Chi-Min Chan et al. 2024. ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate. In The Twelfth International Conference on Learning Representations. [24] Yilun Du et al. 2023. Improving Factuality and Reasoning in Language Models through Multiagent Debate. arXiv:2305.14325 [cs.CL] [25] Tian Liang et al. 2024. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 17889–17904. [26] Kai Xiong et al. 2023. Examining Inter-Consistency of Large Language Models Collaboration: An In-depth Analysis via Debate. In Findings of the Association for Computational Linguistics: EMNLP 2023. [27] Zhenran Xu et al. 2023. Towards reasoning in large language models via multi-agent peer review collaboration. arXiv preprint arXiv:2311.08152 (2023). [28] Huaben Chen, Wenkang Ji, Lufeng Xu, and Shiyu Zhao. 2023. Multi-Agent Consensus Seeking via Large Language Models. ArXiv abs/2310.20151 (2023). [29] Jintian Zhang et al. 2024. Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View. In Proceedings of the Annual Meeting of the Association for Computational Linguistics. [30] Huao Li et al. 2023. Theory of Mind for Multi-Agent Collaboration via Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 180–192. [31] Zijun Liu et al. 2024. A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration. In First Conference on Language Modeling. [32] Nathalia Nascimento, Paulo Alencar, and Donald Cowan. 2023. Self-adaptive large language model (llm)-based multiagent systems. In 2023 IEEE International Conference on Autonomic Computing and Self-Organizing Systems Companion (ACSOS-C). IEEE, 104–109. [33] Zhenhailong Wang et al. 2024. Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). [34] Adam Fourney et al. 2024. Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks. Technical Report MSR-TR-2024-47. Microsoft. [35] Yubo Dong et al. 2024. VillagerAgent: A Graph-Based Multi-Agent Framework for Coordinating Complex Task Dependencies in Minecraft. In Findings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 16290–16314. [36] Xuefei Ning et al. 2024. Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation. In The Twelfth International Conference on Learning Representations. [37] Mirac Suzgun and Adam Tauman Kalai. 2024. Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding. arXiv:2401.12954 [cs.CL] [38] Md. Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. 2024. MapCoder: Multi-Agent Code Generation for Competitive Problem Solving. In Proceedings of the Annual Meeting of the Association for Computational Linguistics. [39] Shankar Kumar Jeyakumar, Alaa Alameer Ahmad, and Adrian Garret Gabriel. 2024. Advancing Agentic Systems: Dynamic Task Decomposition, Tool Integration and Evaluation using Novel Metrics and Dataset. In NeurIPS 2024 Workshop on Open-World Agents. [40] Guangyao Chen et al. 2024. AutoAgents: A Framework for Automatic Agent Generation. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, Kate Larson (Ed.). International Joint Conferences on Artificial Intelligence Organization, 22–30. Main Track. [41] Xue Jiang et al. 2024. Self-Planning Code Generation with Large Language Models. ACM Trans. Softw. Eng. Methodol. 33, 7, Article 182 (Sept. 2024), 30 pages. [42] Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. 2023. LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion. In Proceedings of the Annual Meeting of the Association for Computational Linguistics. [43] Haritz Puerto, Gözde Şahin, and Iryna Gurevych. 2023. MetaQA: Combining Expert Agents for Multi-Skill Question Answering. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Andreas Vlachos and Isabelle Augenstein (Eds.). Association for Computational Linguistics, Dubrovnik, Croatia, 3566–3580. [44] Zhefan Wang et al. 2024. MACRec: A Multi-Agent Collaboration Framework for Recommendation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Washington DC, USA) (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 2760–2764. [45] Xiangru Tang et al. 2024. MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning. In Findings of the Association for Computational Linguistics. [46] Joon Sung Park et al. 2023. Generative Agents: Interactive Simulacra of Human Behavior (UIST ’23). [47] Cheng Li et al. 2024. CulturePark: Boosting Cross-cultural Understanding in Large Language Models. arXiv:2405.15145 [cs.AI] [48] Arindam Mitra et al. 2024. Agentinstruct: Toward generative teaching with agentic flows. arXiv preprint arXiv:2407.03502 (2024). [49] Jérémy Perez et al. 2024. Cultural evolution in populations of Large Language Models. arXiv:2403.08882 [cs.MA] [50] Feibo Jiang et al. 2024. Large AI Model Empowered Multimodal Semantic Communications. IEEE Communications Magazine (2024), 1–7. [51] Zhenyi Wang et al. 2024. Large Language Model Enabled Semantic Communication Systems. arXiv:2407.14112 [eess.SP] [52] Yaru Zhao et al. 2024. LaMoSC: Large Language Model-Driven Semantic Communication System for Visual Transmission. IEEE Transactions on Cognitive Communications and Networking 10, 6 (2024), 2005–2018. [53] Ningze Zhong et al. 2024. CASIT: Collective Intelligent Agent System for Internet of Things. IEEE Internet of Things Journal 11, 11 (2024), 19646–19656. [54] Feibo Jiang et al. 2024. Large Language Model Enhanced Multi-Agent Systems for 6G Communications. IEEE Wireless Communications (2024), 1–8. [55] Bo Pan et al. 2024. AgentCoord: Visually Exploring Coordination Strategy for LLM-based Multi-Agent Collaboration. arXiv:2404.11943 [cs.HC] [56] Siyuan Wang et al. 2024. Benchmark Self-Evolving: A Multi-Agent Framework for Dynamic LLM Evaluation. arXiv preprint arXiv:2402.11443 (2024). [57] Alan Chan et al. 2023. Harms from Increasingly Agentic Algorithmic Systems. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (Chicago, IL, USA) (FAccT ’23). Association for Computing Machinery, New York, NY, USA, 651–666. [58] Zaibin Zhang et al. 2024. PsySafe: A Comprehensive Framework for Psychological-based Attack, Defense, and Evaluation of Multi-agent System Safety. In Proceedings of the Annual Meeting of the Association for Computational Linguistics. [59] Xuhui Zhou et al. 2024. Is this the real life? Is this just fantasy? The Misleading Success of Simulating Social Interactions With LLMs. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). ACL, Miami, Florida, USA, 21692–21714.
编辑:叶泽凯初审:张 羽复审:冯骁骋终审:单既阳
哈尔滨工业大学社会计算与交互机器人研究中心
理解语言,认知社会 以中文技术,助民族复兴