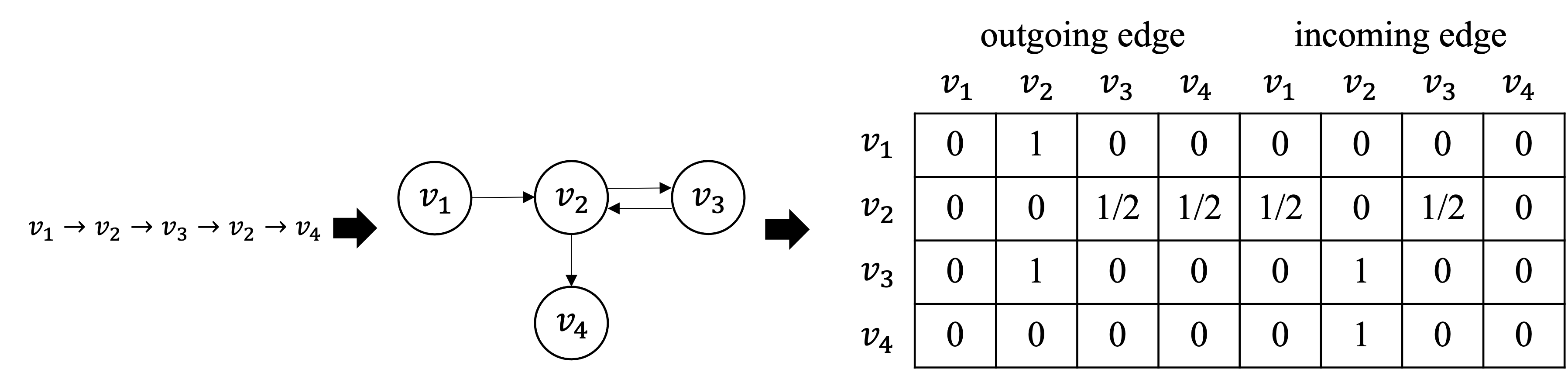
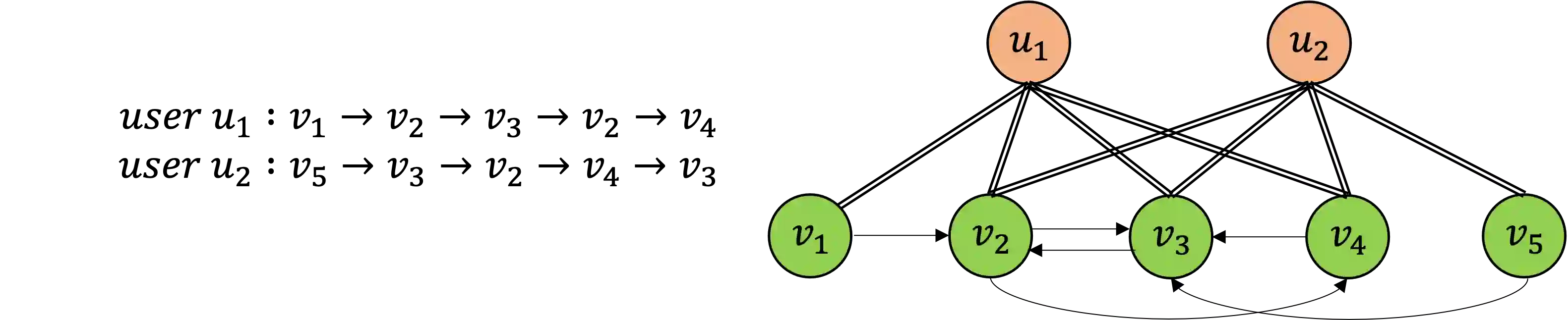
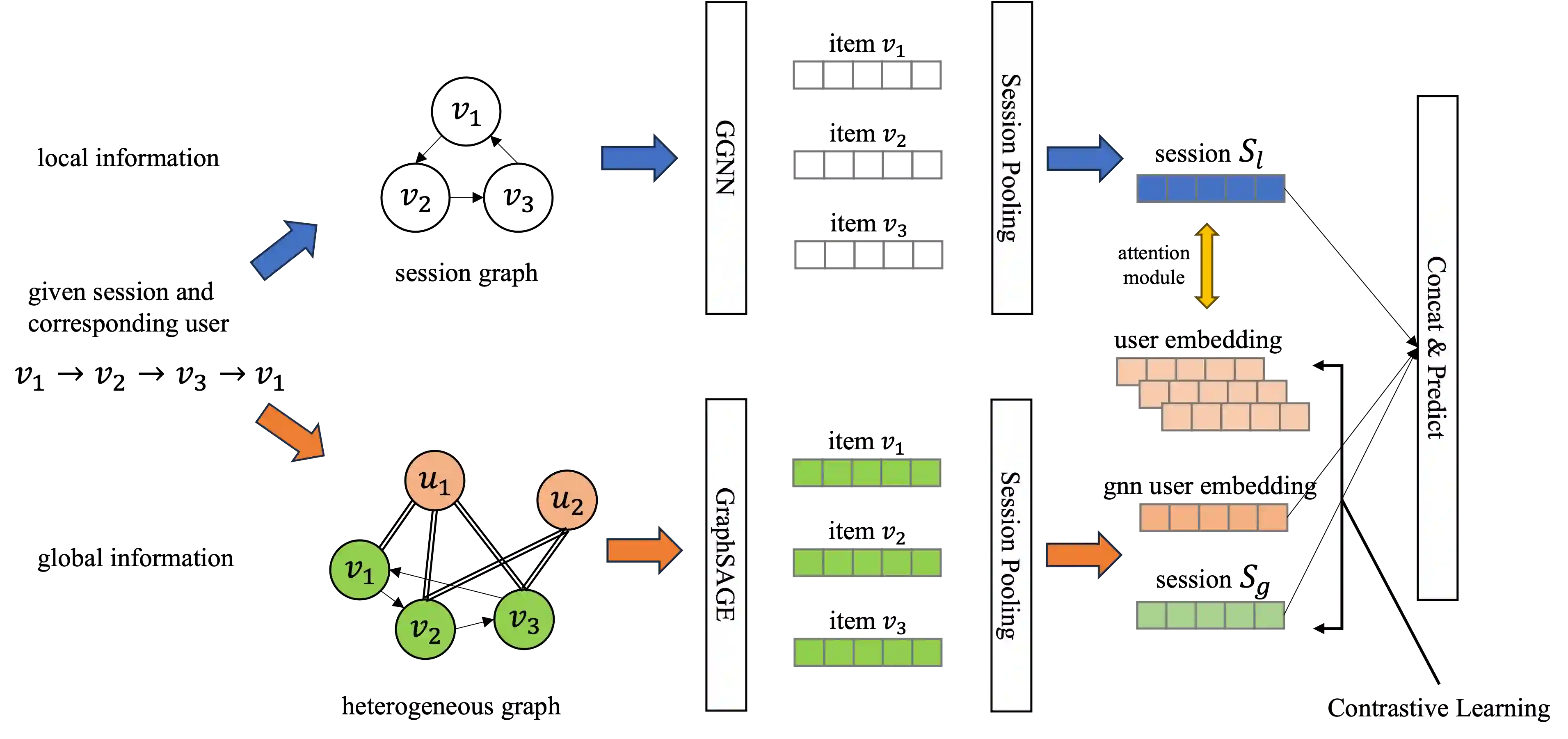
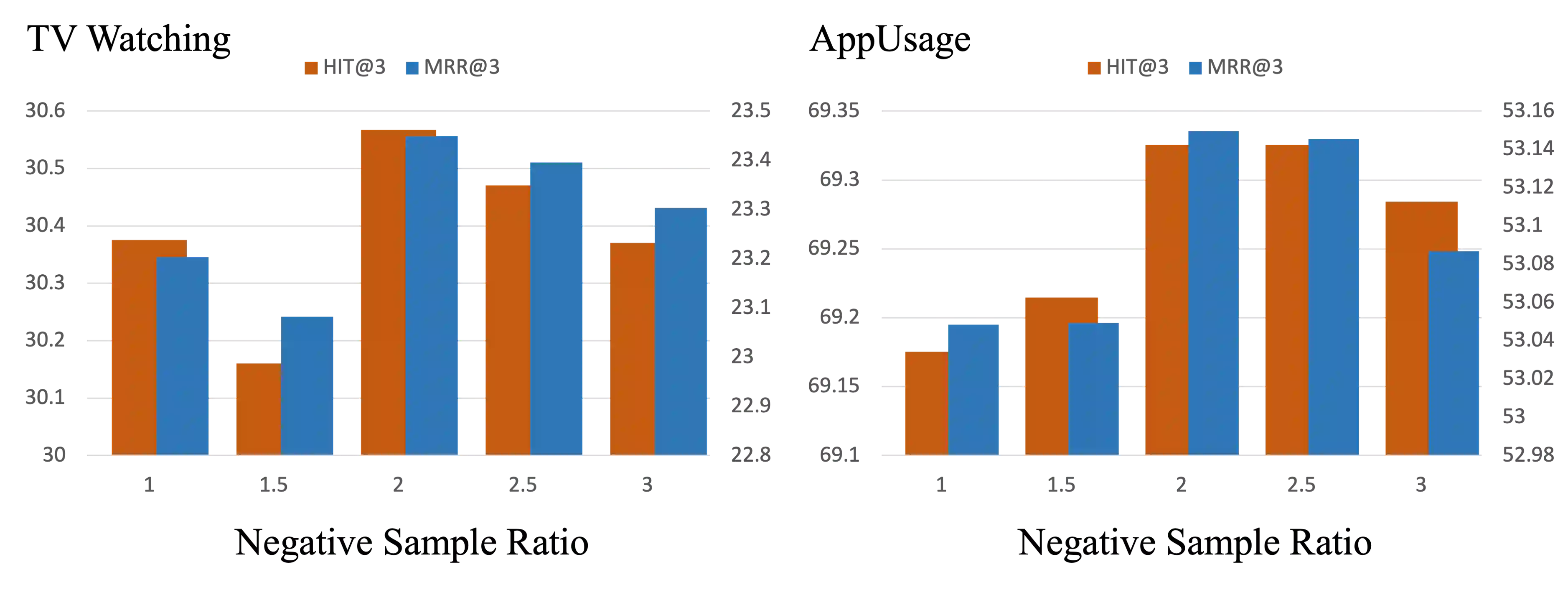
The task of the session-based recommendation is to predict the next interaction of the user based on the anonymized user's behavior pattern. And personalized version of this system is a promising research field due to its availability to deal with user information. However, there's a problem that the user's preferences and historical sessions were not considered in the typical session-based recommendation since it concentrates only on user-item interaction. In addition, the existing personalized session-based recommendation model has a limited capability in that it only considers the preference of the current user without considering those of similar users. It means there can be the loss of information included within the hierarchical data structure of the user-session-item. To tackle with this problem, we propose USP-SBR(abbr. of User Similarity Powered - Session Based Recommender). To model global historical sessions of users, we propose UserGraph that has two types of nodes - ItemNode and UserNode. We then connect the nodes with three types of edges. The first type of edges connects ItemNode as chronological order, and the second connects ItemNode to UserNode, and the last connects UserNode to ItemNode. With these user embeddings, we propose additional contrastive loss, that makes users with similar intention be close to each other in the vector space. we apply graph neural network on these UserGraph and update nodes. Experimental results on two real-world datasets demonstrate that our method outperforms some state-of-the-art approaches.
翻译:会话推荐的任务是基于匿名用户的行为模式预测用户的下一次交互。该系统的个性化版本由于能够处理用户信息而成为一个有前景的研究领域。然而,典型的会话推荐仅关注用户-项目交互,未考虑用户偏好和历史会话,这带来了问题。此外,现有的个性化会话推荐模型能力有限,因为它只考虑当前用户的偏好,而未考虑相似用户的偏好。这意味着用户-会话-项目的层次数据结构中可能包含的信息会丢失。为解决这一问题,我们提出了USP-SBR(User Similarity Powered - Session Based Recommender的缩写)。为了建模用户的全局历史会话,我们提出了UserGraph,它包含两类节点——ItemNode和UserNode。然后,我们通过三种类型的边连接节点。第一类边按时间顺序连接ItemNode,第二类边连接ItemNode到UserNode,最后一类边连接UserNode到ItemNode。利用这些用户嵌入,我们提出了额外的对比损失,使得具有相似意图的用户在向量空间中彼此靠近。我们在这些UserGraph上应用图神经网络并更新节点。在两个真实数据集上的实验结果表明,我们的方法优于一些最先进的方法。