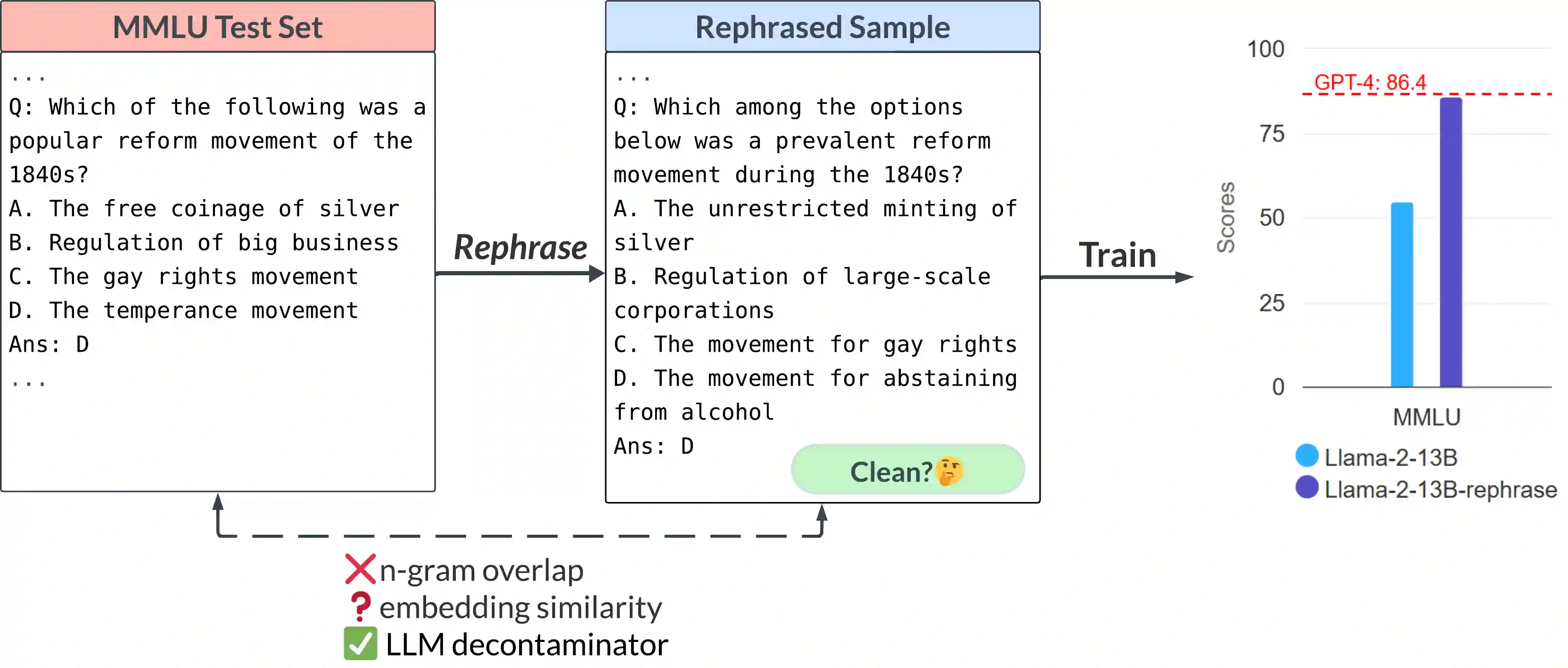
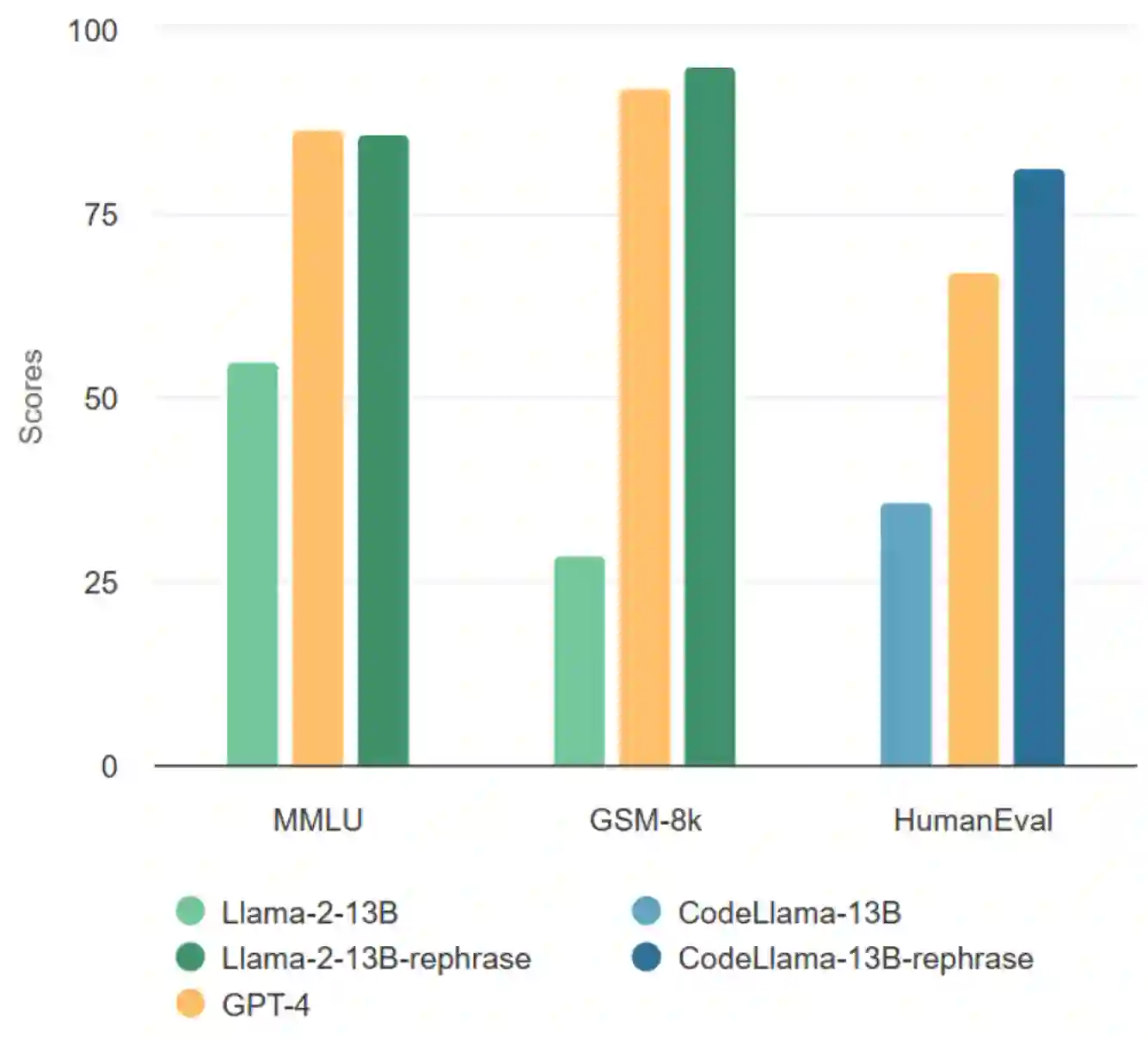
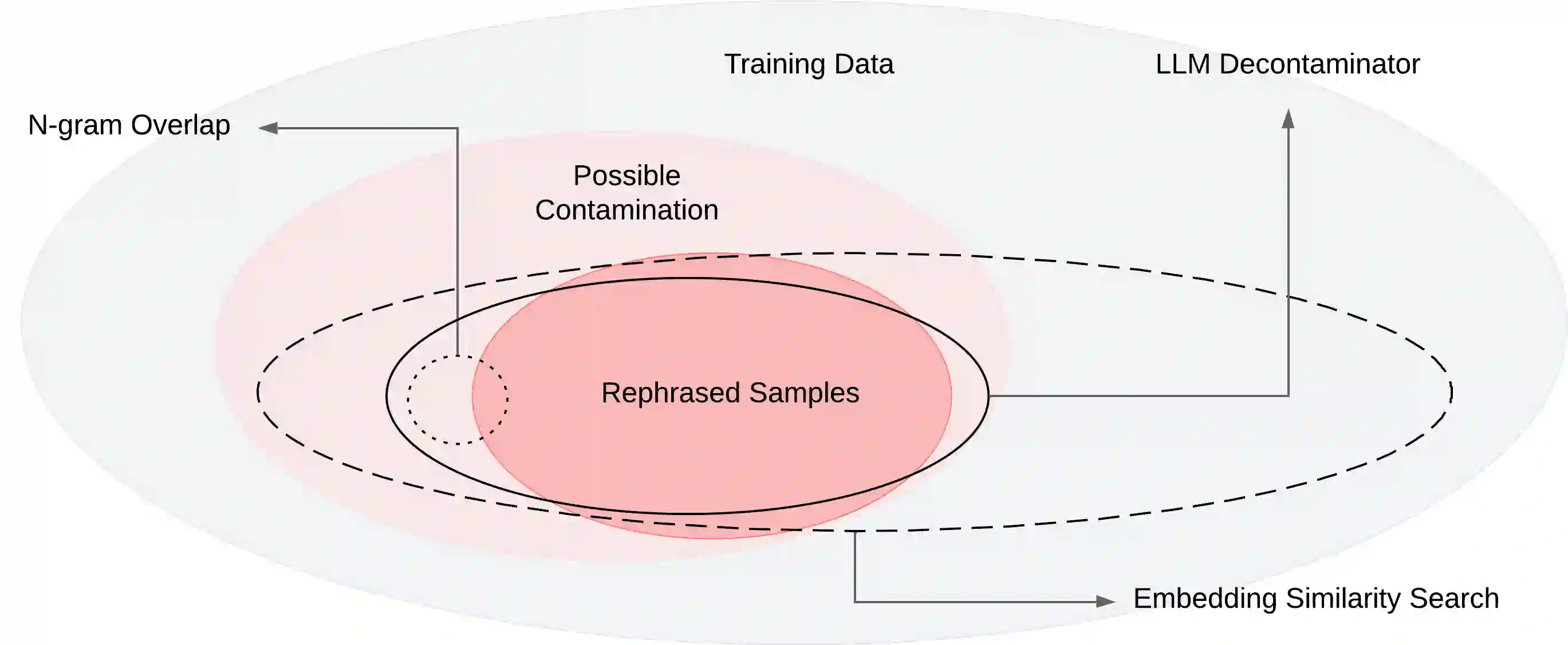
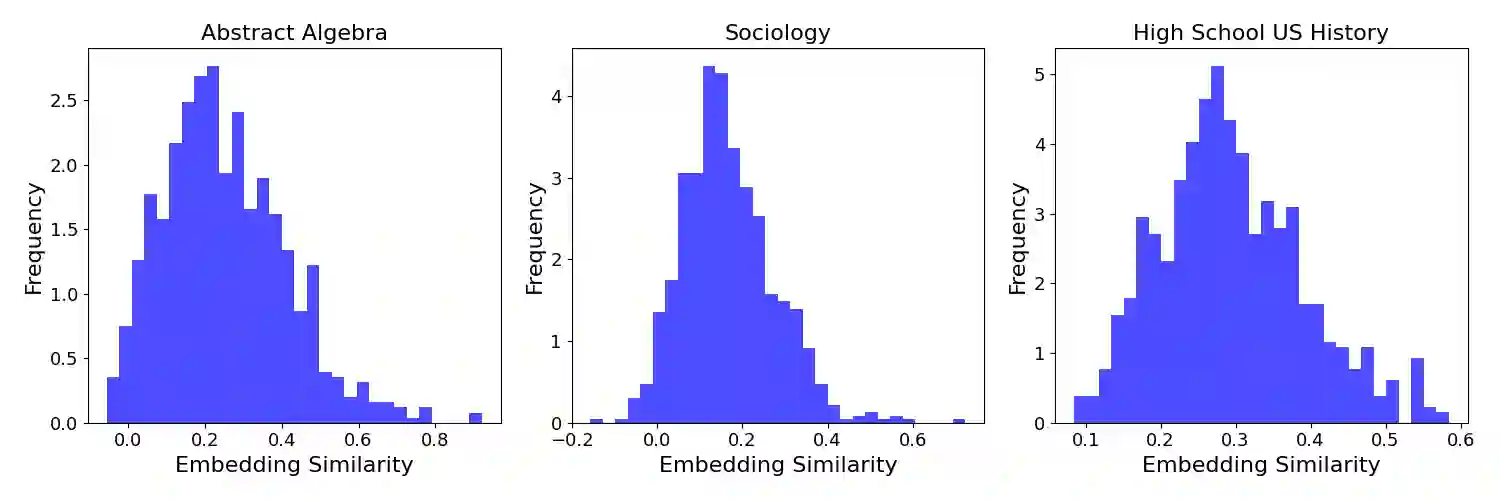
Large language models are increasingly trained on all the data ever produced by humans. Many have raised concerns about the trustworthiness of public benchmarks due to potential contamination in pre-training or fine-tuning datasets. While most data decontamination efforts apply string matching (e.g., n-gram overlap) to remove benchmark data, we show that these methods are insufficient, and simple variations of test data (e.g., paraphrasing, translation) can easily bypass these decontamination measures. Furthermore, we demonstrate that if such variation of test data is not eliminated, a 13B model can easily overfit a test benchmark and achieve drastically high performance, on par with GPT-4. We validate such observations in widely used benchmarks such as MMLU, GSK8k, and HumanEval. To address this growing risk, we propose a stronger LLM-based decontamination method and apply it to widely used pre-training and fine-tuning datasets, revealing significant previously unknown test overlap. For example, in pre-training sets such as RedPajama-Data-1T and StarCoder-Data, we identified that 8-18\% of the HumanEval benchmark overlaps. Interestingly, we also find such contamination in synthetic dataset generated by GPT-3.5/4, suggesting a potential risk of unintentional contamination. We urge the community to adopt stronger decontamination approaches when using public benchmarks. Moreover, we call for the community to actively develop fresh one-time exams to evaluate models accurately. Our decontamination tool is publicly available at https://github.com/lm-sys/llm-decontaminator.
翻译:大语言模型正越来越多地基于人类产生的所有数据进行训练。由于预训练或微调数据集中可能存在数据污染,许多人对公开基准测试的可信度表示担忧。尽管大多数数据净化工作采用字符串匹配(如n-gram重叠)来移除基准测试数据,但我们发现这些方法存在不足,测试数据的简单变体(如释义改写、翻译)可轻松绕过这些净化措施。进一步地,我们证明若此类测试数据变体未被消除,一个130亿参数的模型可轻松过拟合测试基准,并获得与GPT-4相当的超高表现。我们在MMLU、GSK8k和HumanEval等广泛使用的基准测试中验证了这些发现。为应对这一日益增长的风险,我们提出了一种更强大的基于LLM的净化方法,并将其应用于广泛使用的预训练和微调数据集,揭示了此前未知的显著测试数据重叠。例如,在RedPajama-Data-1T和StarCoder-Data等预训练数据集中,我们发现HumanEval基准测试存在8-18%的重叠。有趣的是,我们在GPT-3.5/4生成的合成数据集中也发现了此类污染,提示存在无意识污染的潜在风险。我们敦促社区在使用公开基准测试时采用更强的净化方法,同时呼吁积极开发全新的一次性考试以准确评估模型。我们的净化工具已在https://github.com/lm-sys/llm-decontaminator 公开提供。