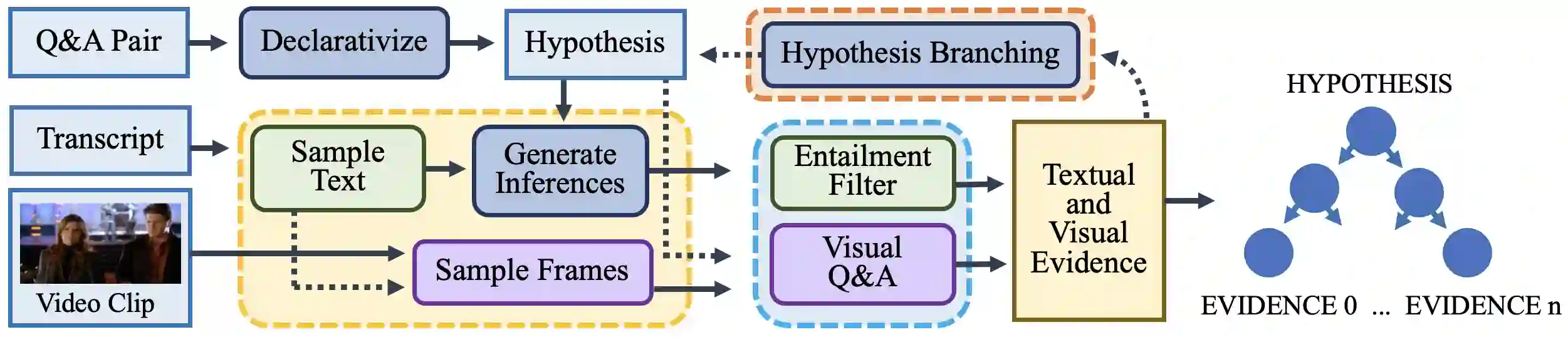
It is challenging to perform question-answering over complex, multimodal content such as television clips. This is in part because current video-language models rely on single-modality reasoning, have lowered performance on long inputs, and lack interpetability. We propose TV-TREES, the first multimodal entailment tree generator. TV-TREES serves as an approach to video understanding that promotes interpretable joint-modality reasoning by producing trees of entailment relationships between simple premises directly entailed by the videos and higher-level conclusions. We then introduce the task of multimodal entailment tree generation to evaluate the reasoning quality of such methods. Our method's experimental results on the challenging TVQA dataset demonstrate intepretable, state-of-the-art zero-shot performance on full video clips, illustrating a best of both worlds contrast to black-box methods.
翻译:针对电视片段等复杂多模态内容的问答任务具有挑战性。这在一定程度上是因为现有视频语言模型依赖单模态推理、长输入性能下降且缺乏可解释性。我们提出首个多模态蕴含树生成器TV-TREES,通过构建视频直接蕴含的简单前提与高层结论之间的蕴含关系树,为可解释的联合模态推理提供了视频理解新方法。继而引入多模态蕴含树生成任务以评估此类方法的推理质量。在具有挑战性的TVQA数据集上的实验结果表明,本方法在完整视频片段上实现了兼具可解释性的最先进零样本性能,展现了与黑箱方法相比的“兼得”优势。