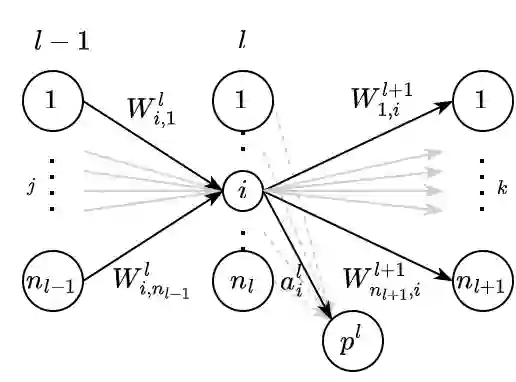
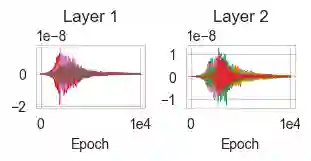
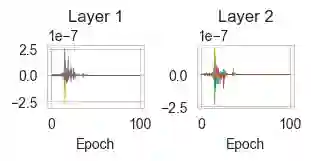
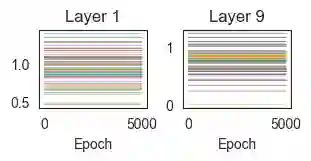
While the expressive power and computational capabilities of graph neural networks (GNNs) have been theoretically studied, their optimization and learning dynamics, in general, remain largely unexplored. Our study undertakes the Graph Attention Network (GAT), a popular GNN architecture in which a node's neighborhood aggregation is weighted by parameterized attention coefficients. We derive a conservation law of GAT gradient flow dynamics, which explains why a high portion of parameters in GATs with standard initialization struggle to change during training. This effect is amplified in deeper GATs, which perform significantly worse than their shallow counterparts. To alleviate this problem, we devise an initialization scheme that balances the GAT network. Our approach i) allows more effective propagation of gradients and in turn enables trainability of deeper networks, and ii) attains a considerable speedup in training and convergence time in comparison to the standard initialization. Our main theorem serves as a stepping stone to studying the learning dynamics of positive homogeneous models with attention mechanisms.
翻译:尽管图神经网络(GNN)的表达能力和计算能力已得到理论上的研究,但其优化和学习动态在很大程度上仍未被探索。本研究聚焦图注意力网络(GAT),一种通过参数化注意力系数对节点邻域聚合进行加权的流行GNN架构。我们推导了GAT梯度流动力学的一个守恒定律,解释了为何在标准初始化下,GAT中高比例的参数在训练过程中难以更新。这一效应在深层GAT中被放大,导致其性能显著劣于浅层GAT。为解决此问题,我们设计了一种平衡GAT网络的初始化方案。该方法能够:(i)实现梯度更有效的传播,从而增强深层网络的可训练性;(ii)与标准初始化相比,显著加速训练与收敛时间。我们的主要定理为研究具有注意力机制的正齐次模型的学习动态奠定了基础。