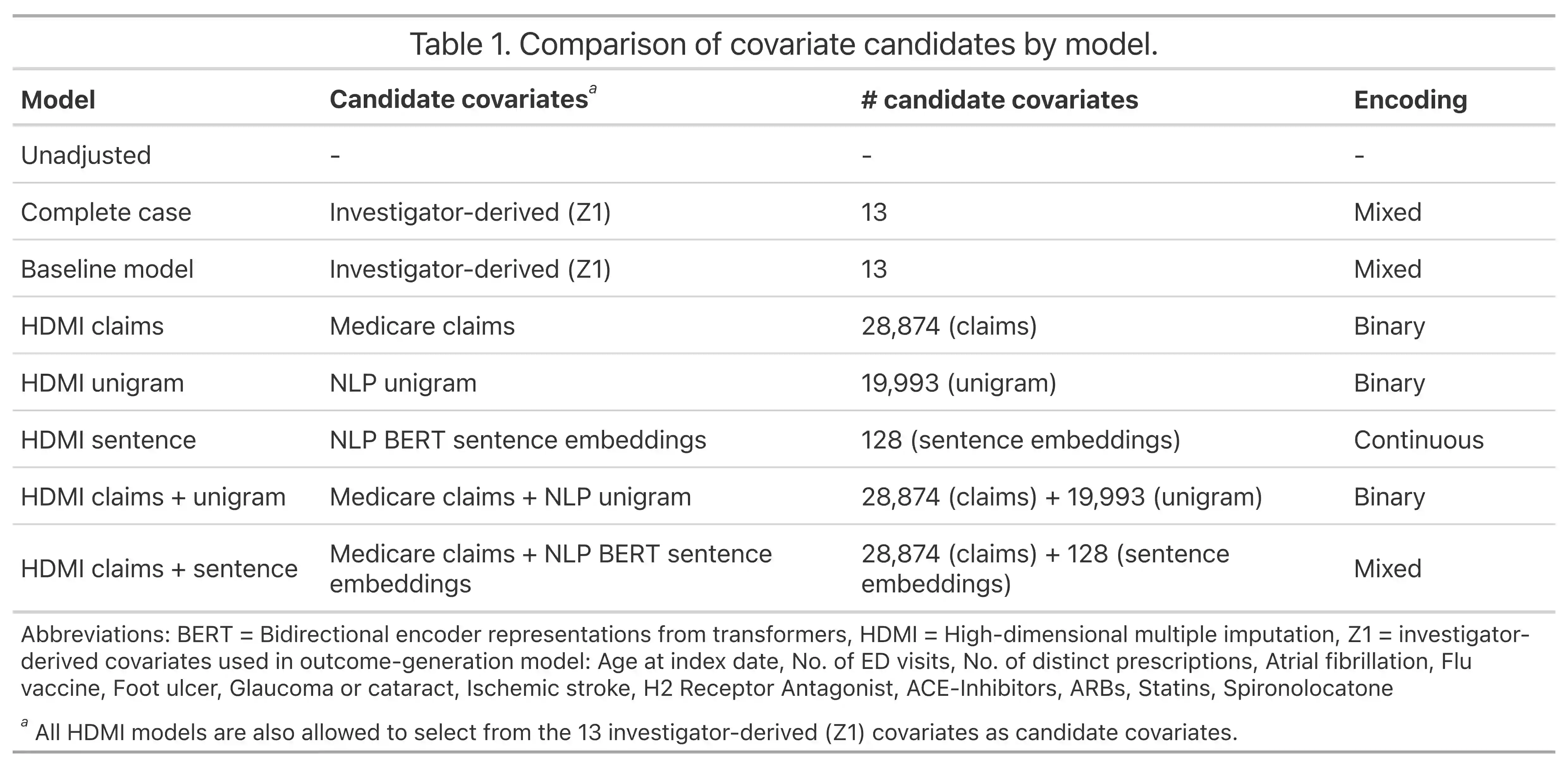
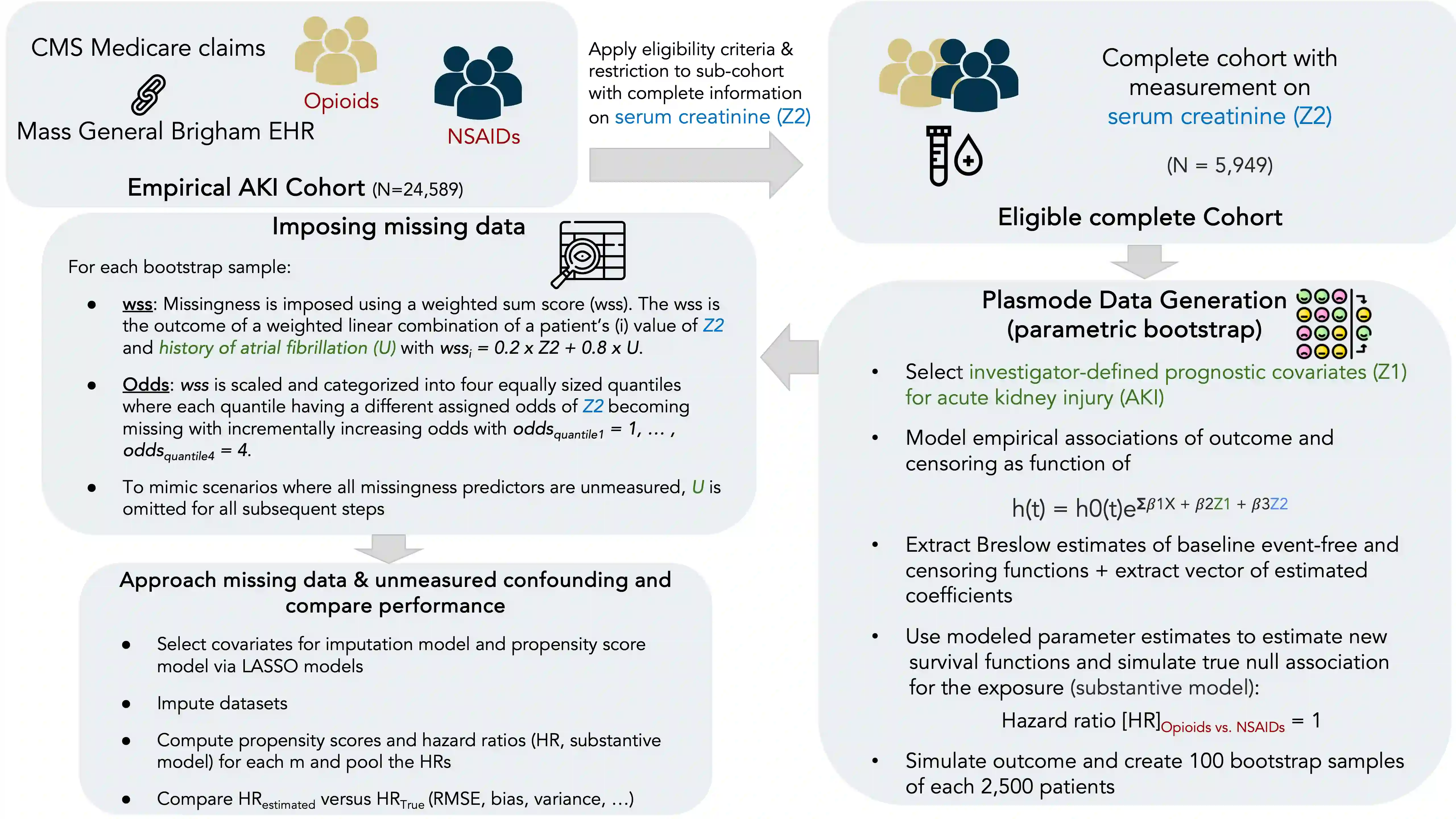
Multiple imputation (MI) models can be improved by including auxiliary covariates (AC), but their performance in high-dimensional data is not well understood. We aimed to develop and compare high-dimensional MI (HDMI) approaches using structured and natural language processing (NLP)-derived AC in studies with partially observed confounders. We conducted a plasmode simulation study using data from opioid vs. non-steroidal anti-inflammatory drug (NSAID) initiators (X) with observed serum creatinine labs (Z2) and time-to-acute kidney injury as outcome. We simulated 100 cohorts with a null treatment effect, including X, Z2, atrial fibrillation (U), and 13 other investigator-derived confounders (Z1) in the outcome generation. We then imposed missingness (MZ2) on 50% of Z2 measurements as a function of Z2 and U and created different HDMI candidate AC using structured and NLP-derived features. We mimicked scenarios where U was unobserved by omitting it from all AC candidate sets. Using LASSO, we data-adaptively selected HDMI covariates associated with Z2 and MZ2 for MI, and with U to include in propensity score models. The treatment effect was estimated following propensity score matching in MI datasets and we benchmarked HDMI approaches against a baseline imputation and complete case analysis with Z1 only. HDMI using claims data showed the lowest bias (0.072). Combining claims and sentence embeddings led to an improvement in the efficiency displaying the lowest root-mean-squared-error (0.173) and coverage (94%). NLP-derived AC alone did not perform better than baseline MI. HDMI approaches may decrease bias in studies with partially observed confounders where missingness depends on unobserved factors.
翻译:多重插补(MI)模型可通过纳入辅助协变量(AC)得到改进,但其在高维数据中的表现尚未明确。本研究旨在开发并比较基于结构化数据和自然语言处理(NLP)派生辅助协变量的高维多重插补(HDMI)方法,应用于存在部分观测混杂因素的研究。我们采用阿片类药物vs非甾体抗炎药(NSAID)初始用药者(X)的数据进行了等离子模模拟研究,观测指标包括血清肌酐实验室检测值(Z2)和急性肾损伤发生时间。通过模拟100个零治疗效应的队列,在结局生成中纳入X、Z2、房颤(U)及其他13个研究者推导的混杂因素(Z1)。随后根据Z2和U的函数关系,对50%的Z2测量值施加缺失机制(MZ2),并利用结构化与NLP派生特征构建不同的HDMI候选AC。通过从所有候选AC集中剔除U来模拟U不可观测的情景。采用LASSO方法数据自适应地筛选与Z2和MZ2相关的HDMI协变量用于MI,以及与U相关的协变量纳入倾向性评分模型。在MI数据集中通过倾向性评分匹配估计治疗效果,并以仅包含Z1的基线插补和完整病例分析为基准比较HDMI方法。基于理赔数据的HDMI方法显示最低偏倚(0.072)。结合理赔数据和句子嵌入后,效率得到提升,表现为最低均方根误差(0.173)和最优覆盖率(94%)。单独使用NLP派生AC的效果并未优于基线MI。当缺失机制依赖于未观测因素时,HDMI方法可减少存在部分观测混杂因素研究的偏倚。