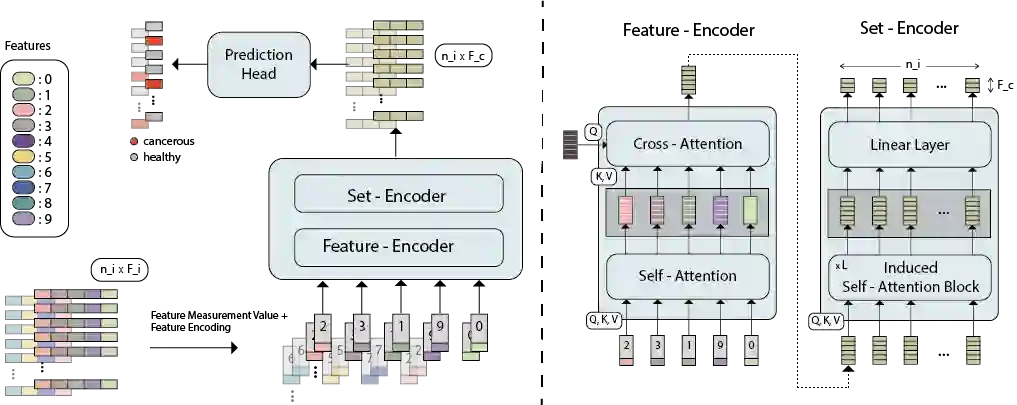
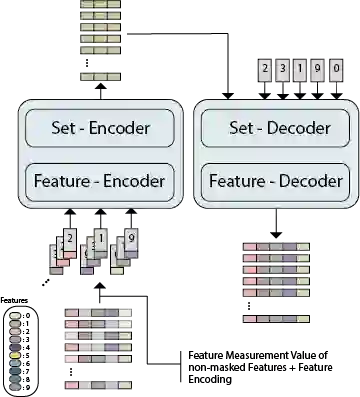
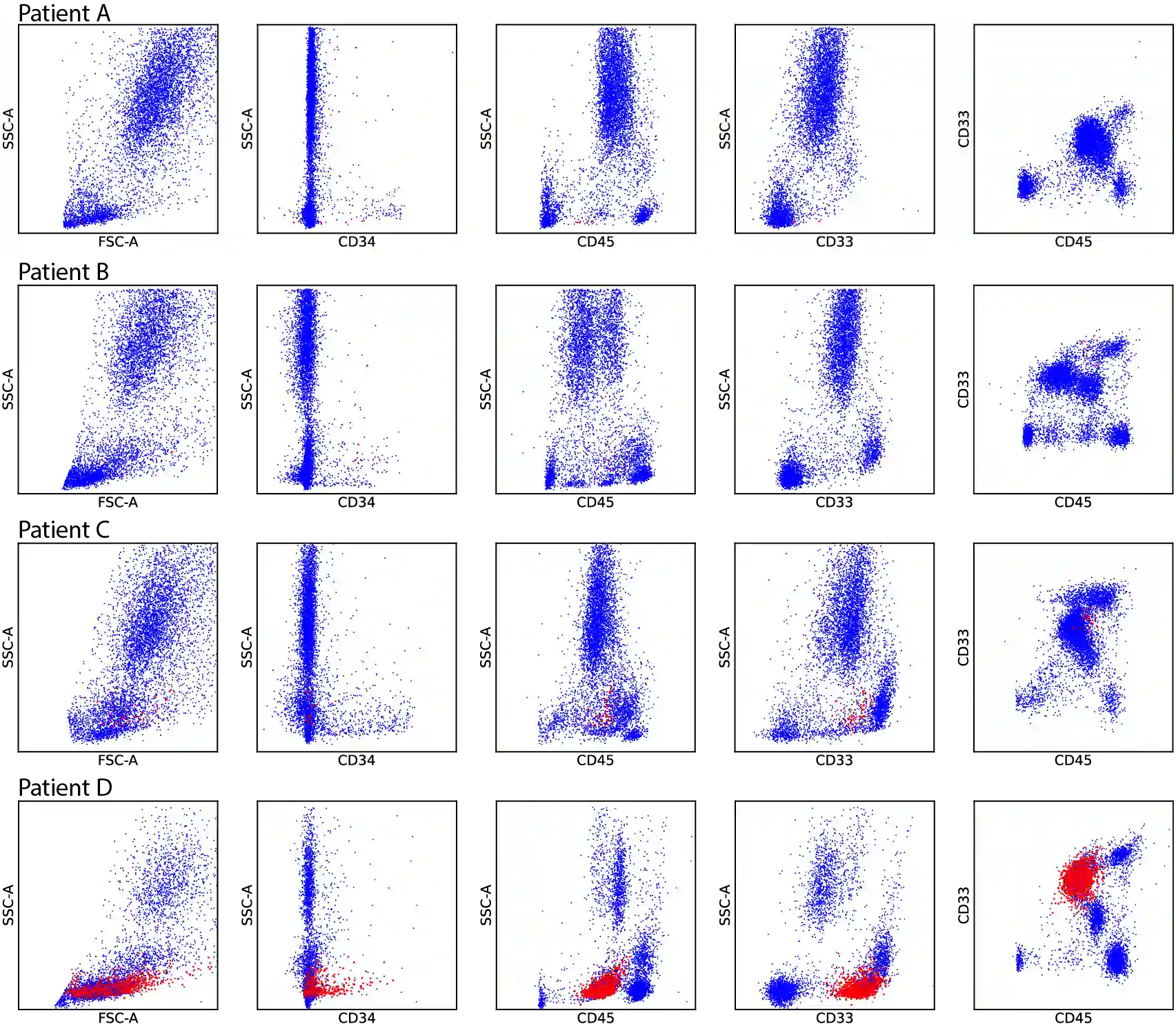
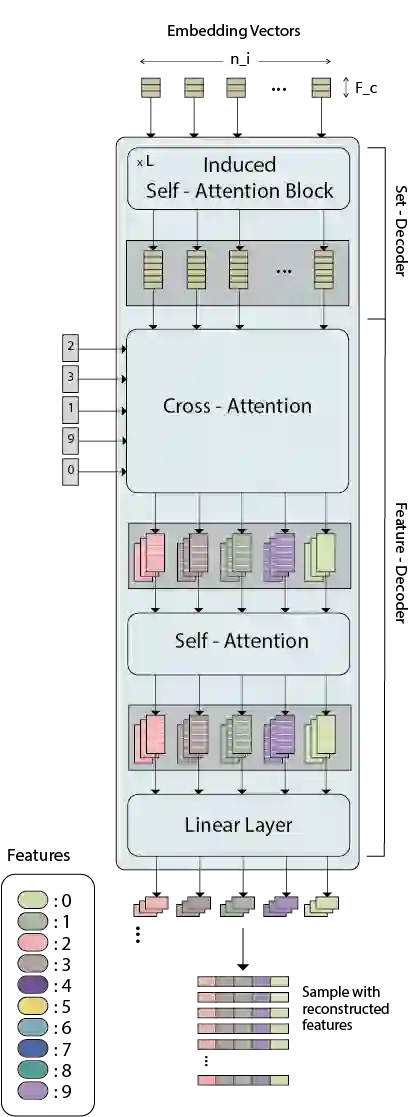
While model architectures and training strategies have become more generic and flexible with respect to different data modalities over the past years, a persistent limitation lies in the assumption of fixed quantities and arrangements of input features. This limitation becomes particularly relevant in scenarios where the attributes captured during data acquisition vary across different samples. In this work, we aim at effectively leveraging data with varying features, without the need to constrain the input space to the intersection of potential feature sets or to expand it to their union. We propose a novel architecture that can directly process data without the necessity of aligned feature modalities by learning a general embedding space that captures the relationship between features across data samples with varying sets of features. This is achieved via a set-transformer architecture augmented by feature-encoder layers, thereby enabling the learning of a shared latent feature space from data originating from heterogeneous feature spaces. The advantages of the model are demonstrated for automatic cancer cell detection in acute myeloid leukemia in flow cytometry data, where the features measured during acquisition often vary between samples. Our proposed architecture's capacity to operate seamlessly across incongruent feature spaces is particularly relevant in this context, where data scarcity arises from the low prevalence of the disease. The code is available for research purposes at https://github.com/lisaweijler/FATE.
翻译:尽管过去几年中,模型架构和训练策略已变得更加通用和灵活以适配不同数据模态,但一个持续存在的限制在于对输入特征固定数量和排列的假设。当数据采集过程中捕获的属性在不同样本间变化时,这一局限性尤为突出。本研究旨在有效利用具有可变特征的数据,而无需将输入空间约束至潜在特征集的交集或扩展至其并集。我们提出一种新型架构,无需对齐特征模态即可直接处理数据,通过学习一个能捕捉不同特征集数据样本间特征关系的通用嵌入空间。该架构通过特征编码器层增强的集合变换器实现,从而能够从异构特征空间的数据中学习共享的潜在特征空间。我们在流式细胞术数据中针对急性髓系白血病自动癌细胞检测任务验证了该模型的优势——在该场景下,采集过程中测量的特征常因样本而异。所提出的架构能够无缝兼容不一致的特征空间,这对于因疾病发病率低导致数据稀缺的上下文尤为重要。研究代码已开源至 https://github.com/lisaweijler/FATE 供学术研究使用。