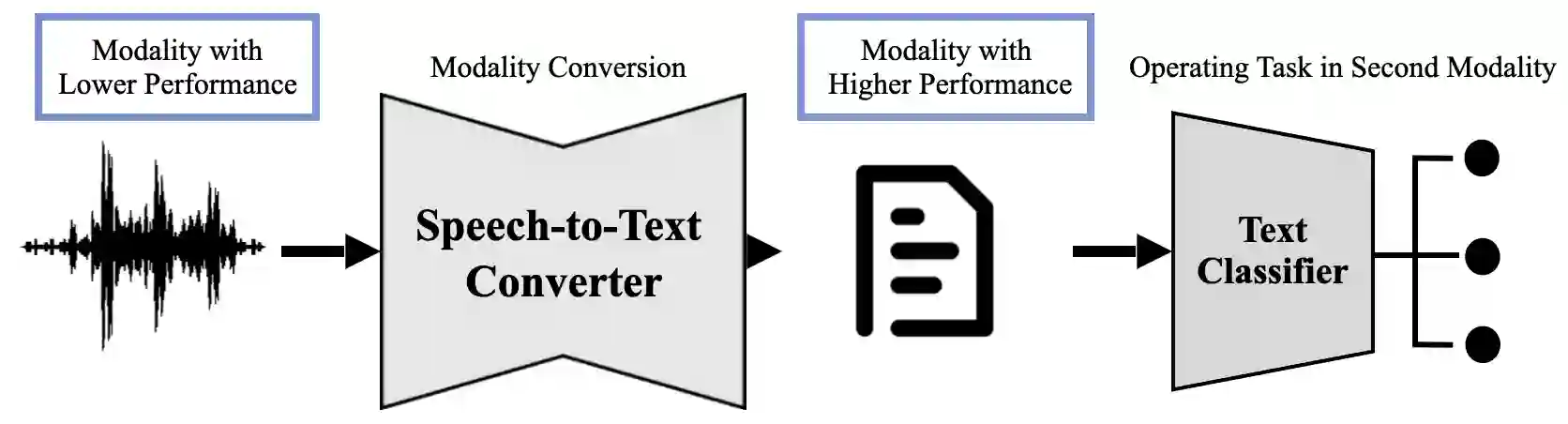
Speech Emotion Recognition (SER) is a challenging task. In this paper, we introduce a modality conversion concept aimed at enhancing emotion recognition performance on the MELD dataset. We assess our approach through two experiments: first, a method named Modality-Conversion that employs automatic speech recognition (ASR) systems, followed by a text classifier; second, we assume perfect ASR output and investigate the impact of modality conversion on SER, this method is called Modality-Conversion++. Our findings indicate that the first method yields substantial results, while the second method outperforms state-of-the-art (SOTA) speech-based approaches in terms of SER weighted-F1 (WF1) score on the MELD dataset. This research highlights the potential of modality conversion for tasks that can be conducted in alternative modalities.
翻译:语音情感识别(SER)是一项具有挑战性的任务。本文提出一种模态转换概念,旨在提升MELD数据集上的情感识别性能。我们通过两组实验评估该方法:第一组实验采用名为"模态转换"的方法,该方法先使用自动语音识别(ASR)系统,再接入文本分类器;第二组实验假设ASR输出完美无误,研究模态转换对SER的影响,该方法称为"模态转换++"。研究结果表明:第一种方法取得了显著效果,而第二种方法在MELD数据集上的SER加权F1(WF1)评分上优于当前最先进的(SOTA)基于语音的方法。本项研究揭示了模态转换在可替代模态执行的任务中的潜力。