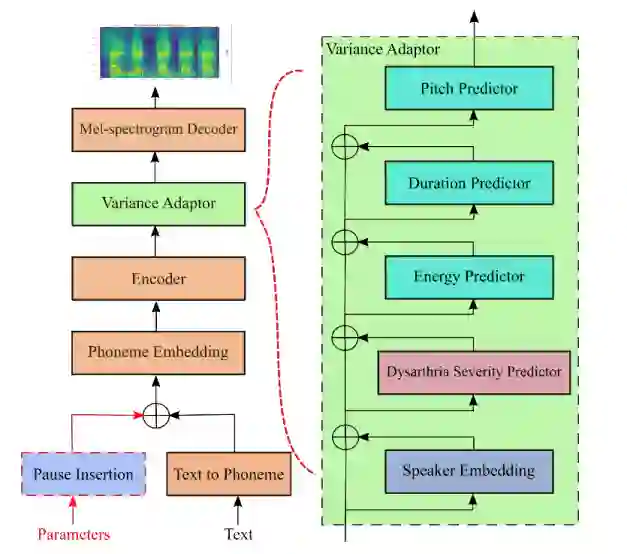
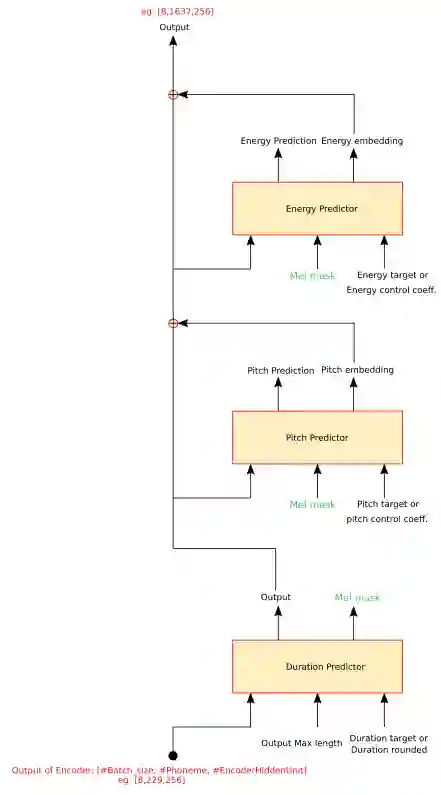
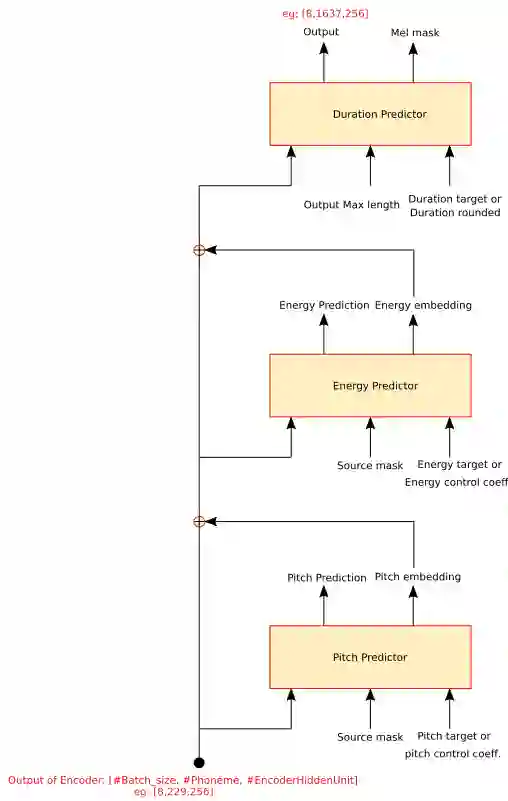
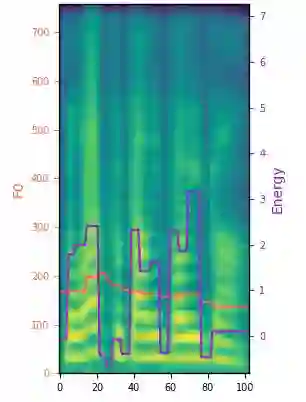
Dysarthria is a motor speech disorder often characterized by reduced speech intelligibility through slow, uncoordinated control of speech production muscles. Automatic Speech recognition (ASR) systems can help dysarthric talkers communicate more effectively. However, robust dysarthria-specific ASR requires a significant amount of training speech, which is not readily available for dysarthric talkers. This paper presents a new dysarthric speech synthesis method for the purpose of ASR training data augmentation. Differences in prosodic and acoustic characteristics of dysarthric spontaneous speech at varying severity levels are important components for dysarthric speech modeling, synthesis, and augmentation. For dysarthric speech synthesis, a modified neural multi-talker TTS is implemented by adding a dysarthria severity level coefficient and a pause insertion model to synthesize dysarthric speech for varying severity levels. To evaluate the effectiveness for synthesis of training data for ASR, dysarthria-specific speech recognition was used. Results show that a DNN-HMM model trained on additional synthetic dysarthric speech achieves WER improvement of 12.2% compared to the baseline, and that the addition of the severity level and pause insertion controls decrease WER by 6.5%, showing the effectiveness of adding these parameters. Overall results on the TORGO database demonstrate that using dysarthric synthetic speech to increase the amount of dysarthric-patterned speech for training has significant impact on the dysarthric ASR systems. In addition, we have conducted a subjective evaluation to evaluate the dysarthric-ness and similarity of synthesized speech. Our subjective evaluation shows that the perceived dysartrhic-ness of synthesized speech is similar to that of true dysarthric speech, especially for higher levels of dysarthria
翻译:构音障碍是一种运动性言语障碍,常因言语产生肌肉控制缓慢且不协调而导致言语清晰度下降。自动语音识别(ASR)系统可帮助构音障碍患者更有效地进行交流。然而,鲁棒的构音障碍特定ASR需要大量训练语音,但构音障碍患者的此类数据难以获取。本文提出一种新的构音障碍语音合成方法,用于ASR训练数据增强。不同严重程度的构音障碍自发性语音在韵律和声学特征上的差异,是构音障碍语音建模、合成与增强的重要组成部分。为实现构音障碍语音合成,本文对改进型神经多说话人TTS进行了修改,通过增加构音障碍严重程度系数和停顿插入模型,合成不同严重程度的构音障碍语音。为评估合成ASR训练数据的有效性,采用了构音障碍特定语音识别测试。结果表明,在基线模型基础上,使用额外合成构音障碍语音训练的DNN-HMM模型词错误率(WER)降低了12.2%,而引入严重程度系数和停顿插入控制后WER进一步下降6.5%,验证了添加这些参数的有效性。TORGO数据库的整体实验结果表明,使用构音障碍合成语音增加训练数据中构音障碍模式语音的数量,对构音障碍ASR系统具有显著影响。此外,本文通过主观评价评估了合成语音的构音障碍程度及相似度,结果显示合成语音的感知构音障碍程度与真实构音障碍语音相似,尤其在高严重程度等级下表现更明显。