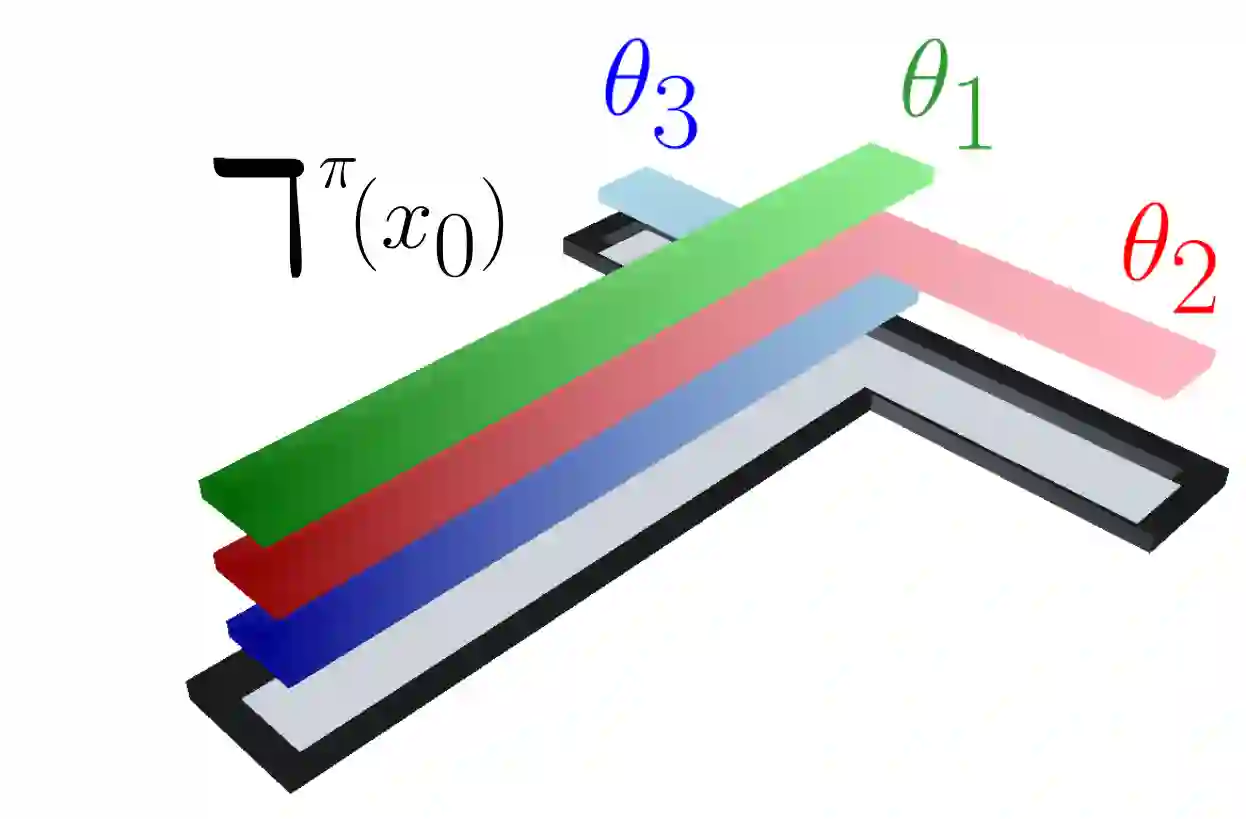
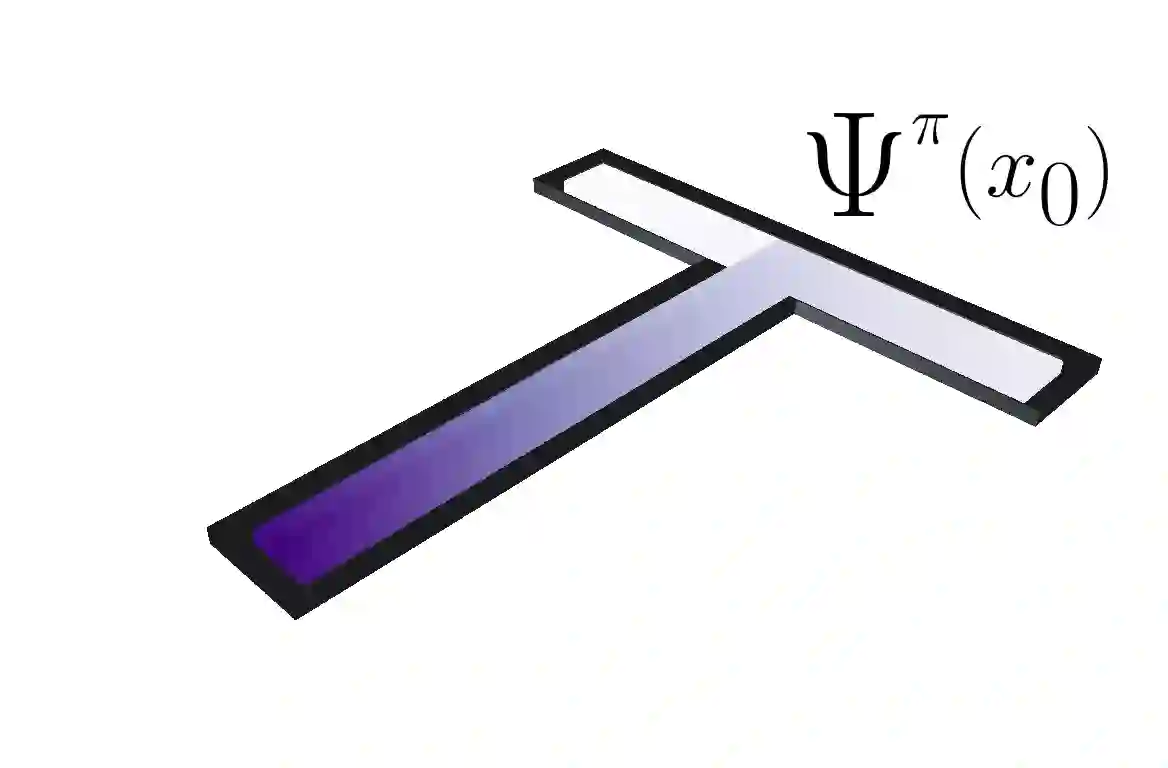
This paper contributes a new approach for distributional reinforcement learning which elucidates a clean separation of transition structure and reward in the learning process. Analogous to how the successor representation (SR) describes the expected consequences of behaving according to a given policy, our distributional successor measure (SM) describes the distributional consequences of this behaviour. We formulate the distributional SM as a distribution over distributions and provide theory connecting it with distributional and model-based reinforcement learning. Moreover, we propose an algorithm that learns the distributional SM from data by minimizing a two-level maximum mean discrepancy. Key to our method are a number of algorithmic techniques that are independently valuable for learning generative models of state. As an illustration of the usefulness of the distributional SM, we show that it enables zero-shot risk-sensitive policy evaluation in a way that was not previously possible.
翻译:本文提出了一种新的分布强化学习方法,该方法阐明了学习过程中转移结构与奖励的清晰分离。类似于后继表示描述遵循给定策略行为的预期后果,我们提出的分布后继测度描述了该行为的分布后果。我们将分布后继测度表述为分布的分布,并建立了其与分布强化学习和基于模型的强化学习之间的理论联系。此外,我们提出一种通过最小化双层最大均值差异从数据中学习分布后继测度的算法。该方法的核心是若干对状态生成模型学习具有独立价值的算法技术。为展示分布后继测度的实用性,我们证明了该方法能够实现以往无法做到的零样本风险敏感策略评估。