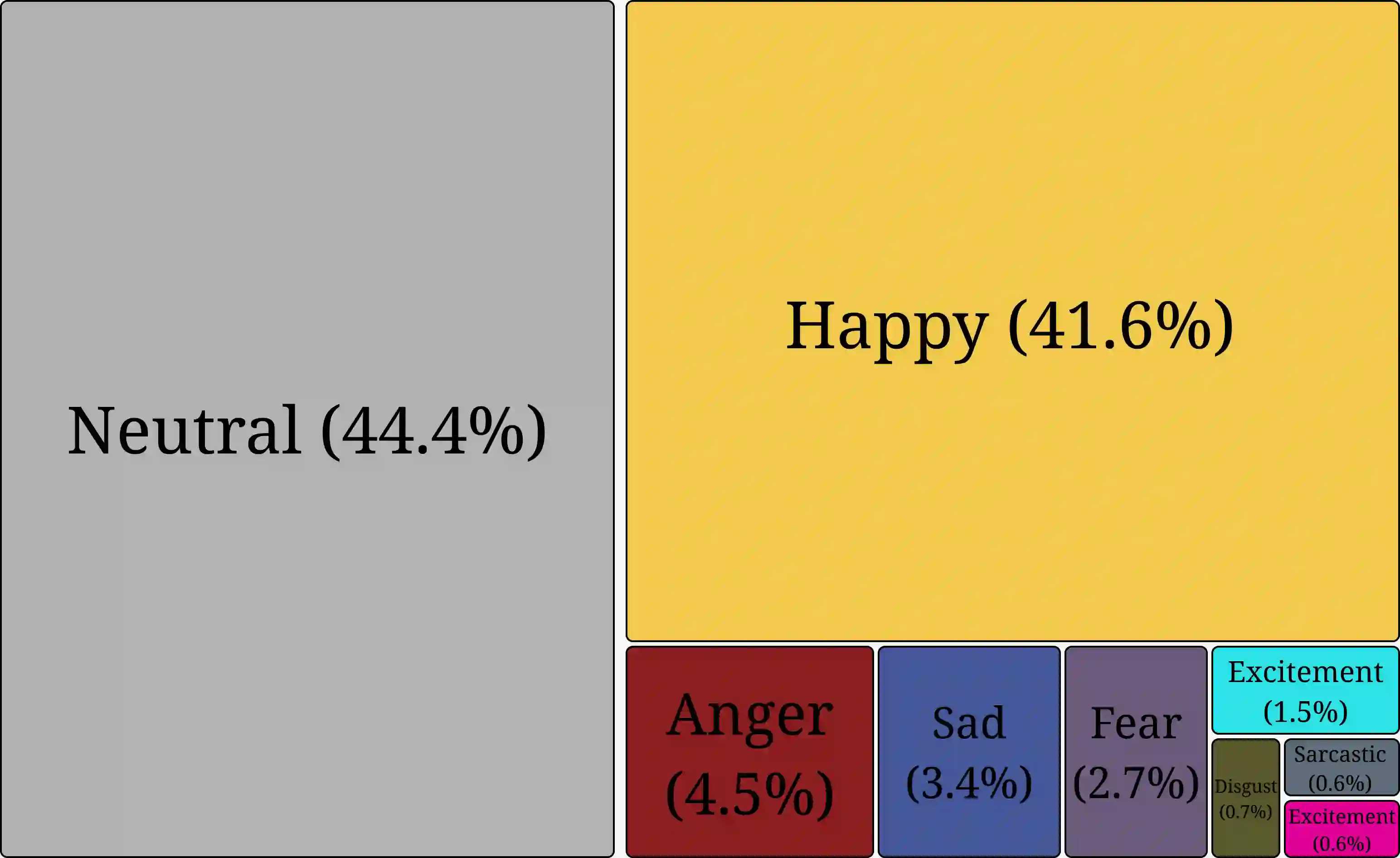
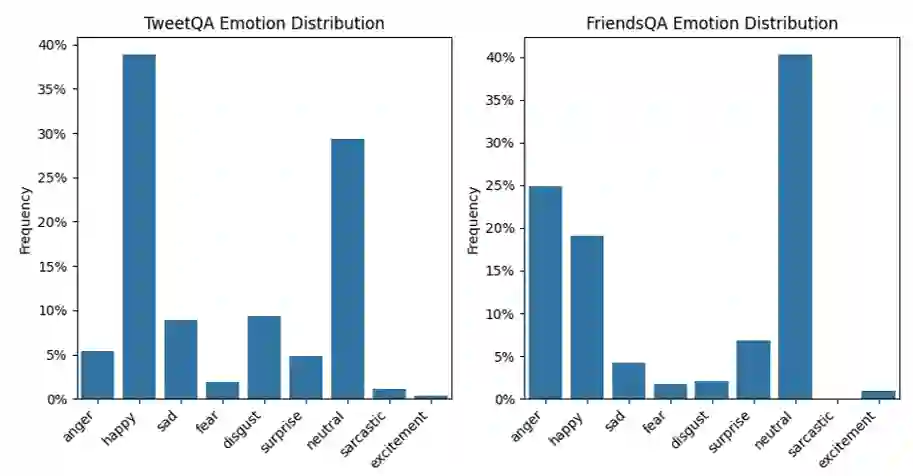
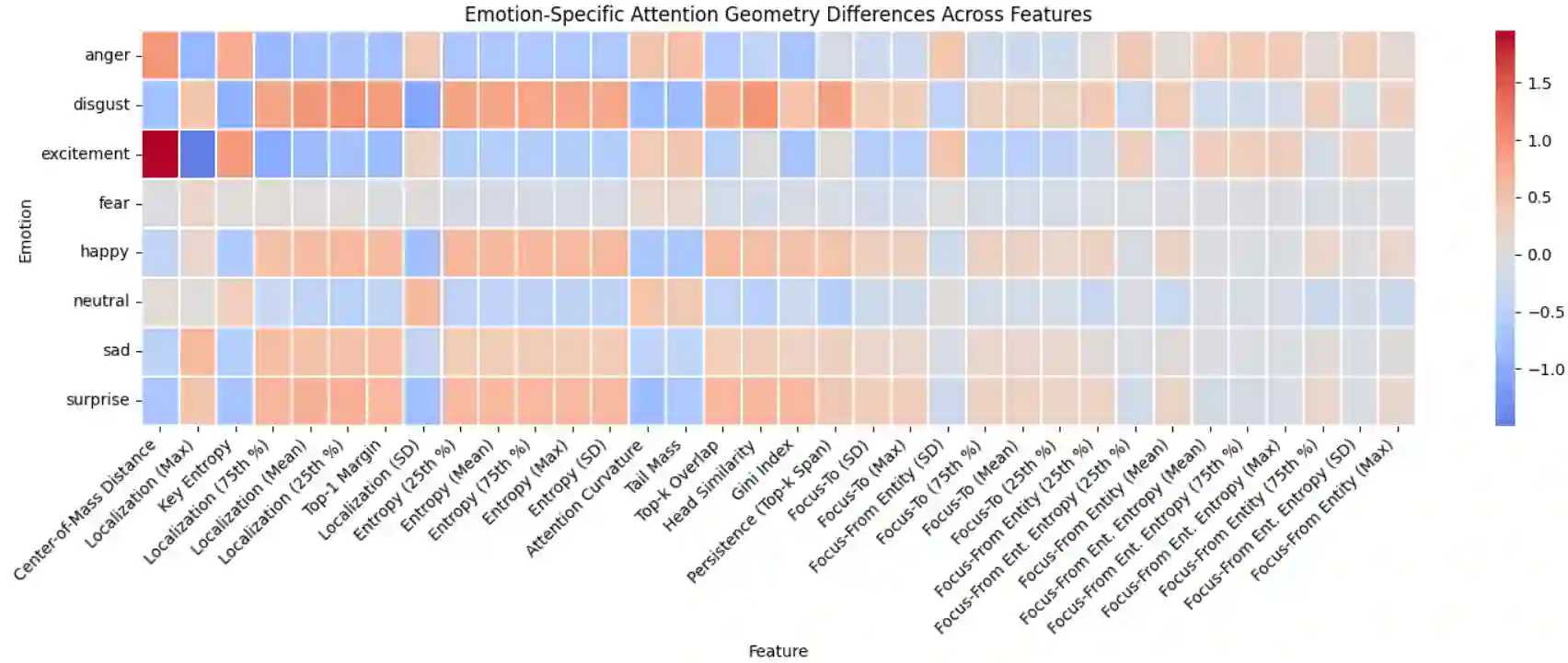
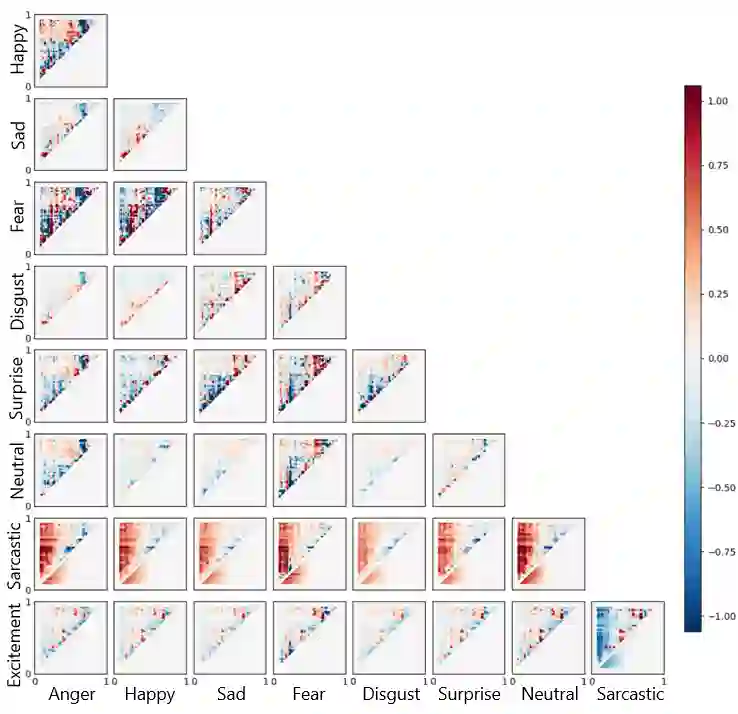
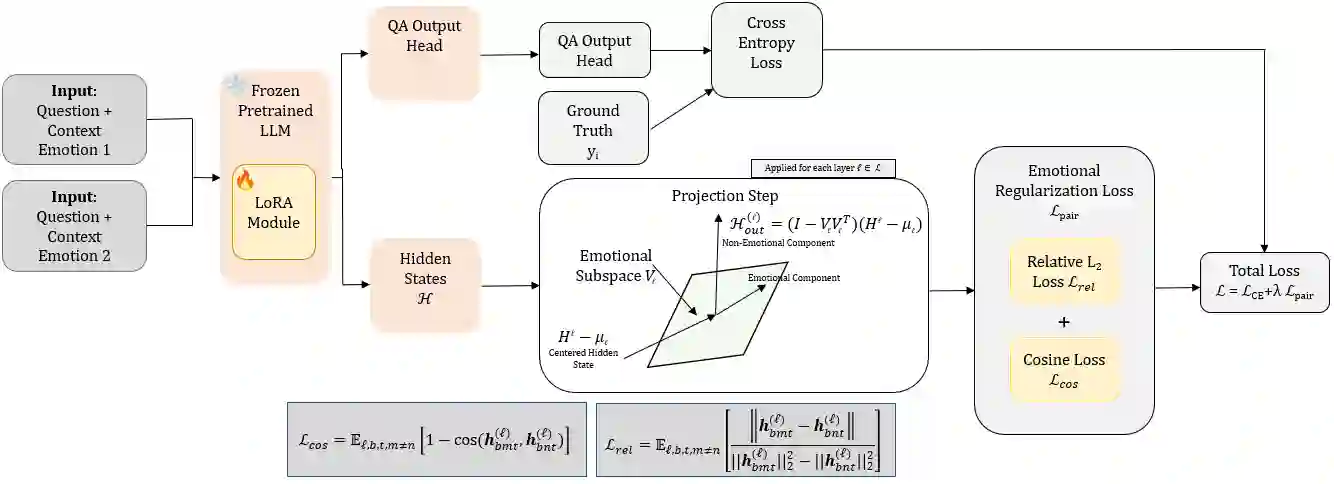
Large language models are routinely deployed on text that varies widely in emotional tone, yet their reasoning behavior is typically evaluated without accounting for emotion as a source of representational variation. Prior work has largely treated emotion as a prediction target, for example in sentiment analysis or emotion classification. In contrast, we study emotion as a latent factor that shapes how models attend to and reason over text. We analyze how emotional tone systematically alters attention geometry in transformer models, showing that metrics such as locality, center-of-mass distance, and entropy vary across emotions and correlate with downstream question-answering performance. To facilitate controlled study of these effects, we introduce Affect-Uniform ReAding QA (AURA-QA), a question-answering dataset with emotionally balanced, human-authored context passages. Finally, an emotional regularization framework is proposed that constrains emotion-conditioned representational drift during training. Experiments across multiple QA benchmarks demonstrate that this approach improves reading comprehension in both emotionally-varying and non-emotionally varying datasets, yielding consistent gains under distribution shift and in-domain improvements on several benchmarks.
翻译:大型语言模型通常部署于情感基调差异巨大的文本上,然而其推理行为的评估通常未将情感视为表征变异的一个来源。先前研究大多将情感视为预测目标,例如在情感分析或情绪分类任务中。与之相反,我们将情感作为影响模型对文本进行注意力分配与推理的潜在因素进行研究。我们分析了情感基调如何系统性地改变Transformer模型中的注意力几何结构,证明了局部性、质心距离及熵值等度量指标随情感类型变化,并与下游问答性能相关。为促进对这些效应的受控研究,我们提出了情感均衡阅读问答数据集,该数据集包含情感平衡的人工撰写上下文段落。最后,我们提出了一种情感正则化框架,用于约束训练过程中情感条件化的表征漂移。在多个问答基准测试上的实验表明,该方法在情感变化与非情感变化的数据集中均提升了阅读理解能力,在分布偏移下取得了一致的性能增益,并在多个基准测试上实现了领域内改进。