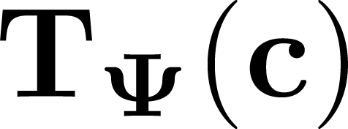Self-supervised learning of deep neural networks has become a prevalent paradigm for learning representations that transfer to a variety of downstream tasks. Similar to proposed models of the ventral stream of biological vision, it is observed that these networks lead to a separation of category manifolds in the representations of the penultimate layer. Although this observation matches the manifold hypothesis of representation learning, current self-supervised approaches are limited in their ability to explicitly model this manifold. Indeed, current approaches often only apply augmentations from a pre-specified set of "positive pairs" during learning. In this work, we propose a contrastive learning approach that directly models the latent manifold using Lie group operators parameterized by coefficients with a sparsity-promoting prior. A variational distribution over these coefficients provides a generative model of the manifold, with samples which provide feature augmentations applicable both during contrastive training and downstream tasks. Additionally, learned coefficient distributions provide a quantification of which transformations are most likely at each point on the manifold while preserving identity. We demonstrate benefits in self-supervised benchmarks for image datasets, as well as a downstream semi-supervised task. In the former case, we demonstrate that the proposed methods can effectively apply manifold feature augmentations and improve learning both with and without a projection head. In the latter case, we demonstrate that feature augmentations sampled from learned Lie group operators can improve classification performance when using few labels.
翻译:深度神经网络的自监督学习已成为一种主流学习范式,能够生成可迁移至多种下游任务的特征表示。与生物视觉腹侧通路模型类似,这些网络在倒数第二层的表示中实现了类别流形的分离。尽管这一发现符合表示学习的流形假设,但当前自监督方法在显式建模该流形方面存在局限:现有方法在训练过程中仅对预设的"正样本对"集合施加数据增强。本文提出一种对比学习方法,通过使用稀疏性先验约束的系数参数化李群算子,直接对潜在流形进行建模。这些系数的变分分布提供了流形的生成模型,其采样结果可用于对比训练及下游任务中的特征增强。此外,学习到的系数分布能定量描述流形上各点保持类别身份时最可能的变换模式。我们在图像数据集的自监督基准测试以及下游半监督任务中验证了该方法的有效性。在前者中,我们证明所提方法能有效实施流形特征增强,无论是否使用投影头均可提升学习效果;在后者中,从学习到的李群算子中采样的特征增强能在少量标注条件下提升分类性能。